Python实现线性判别分析(LDA)的MATLAB方式
人气:0线性判别分析(linear discriminant analysis),LDA。也称为Fisher线性判别(FLD)是模式识别的经典算法。
(1)中心思想:将高维的样本投影到最佳鉴别矢量空间,来达到抽取分类信息和压缩特种空间维数的效果,投影后保证样本在新的子空间有最大的类间距离和最小的类内距离。也就是说在该空间中有最佳的可分离性。
(2)与PCA的不同点:PCA主要是从特征的协方差出发,来找到比较好的投影方式,最后需要保留的特征维数可以自己选择。但是LDA更多的是考虑了类别信息,即希望投影后不同类别之间数据点的距离更大,同一类别的数据点更紧凑。
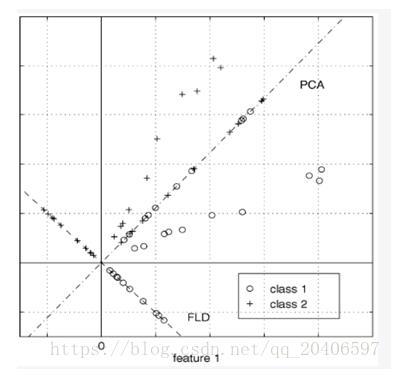
从图中也可以看出,LDA的投影后就已经将不同的类别分开了。
所以说,LDA是以分类为基准的,考虑的是如何选择投影方向使得分类更好,是有监督的。但是PCA是一种无监督的降维方式,它只是单纯的降维,只考虑如何选择投影面才能使得降维以后的样本信息保留的最大。
(3)LDA的维度:LDA降维后是与类别个数直接相关的,而与数据本身的维度没有关系。如果有C个类别,LDA降维后一般会选择1-C-1维。对于很多二分类问题,LDA之后就剩下一维,然后再找到一个分类效果最好的阈值就可以进行分类了。
(4)投影的坐标系是否正交:
PCA的投影坐标系都是正交的,而LDA是根据类别的标注,主要关注的是分类能力,因此可以不去关注石否正交,而且一般都不正交。
(5)LDA步骤:
(a)计算各个类的样本均值:

这个地方需要注意的是,分别求出每个类别样本的Sbi或者Swi后,在计算总体的Sb和Sw时需要做加权平均,因为每个类别中的样本数目可能是不一样的。
(d)LDA作为一个分类的算法,我们希望类内的聚合度高,即类内散度矩阵小,而类间散度矩阵大。这样的分类效果才好。因此引入Fisher鉴别准则表达式:

(inv(Sw)Sb)的特征向量。且最优投影轴的个数d<=C-1;
(e)所以,只要计算出矩阵inv(Sw)Sb的最大特征值对应的特征向量,该特征向量就是投影方向W。
(6)计算各点在投影后的方向上的投影点:

MATLAB实现代码:
%这是训练数据集
%2.9500 6.6300 0
%2.5300 7.7900 0
%3.5700 5.6500 0
%3.1600 5.4700 0
%2.5800 4.4600 1
%2.1600 6.2200 1
%3.2700 3.5200 1
X=load('22.txt');
pos0=find(X(:,3)==0);
pos1=find(X(:,3)==1);
X1=X(pos0,1:2);
X2=X(pos1,1:2);
hold on
plot(X1(:,1),X1(:,2),'r+','markerfacecolor', [ 1, 0, 0 ]);
plot(X2(:,1),X2(:,2),'b*','markerfacecolor', [ 0, 0, 1 ]);
grid on
%输出样本的二维分布
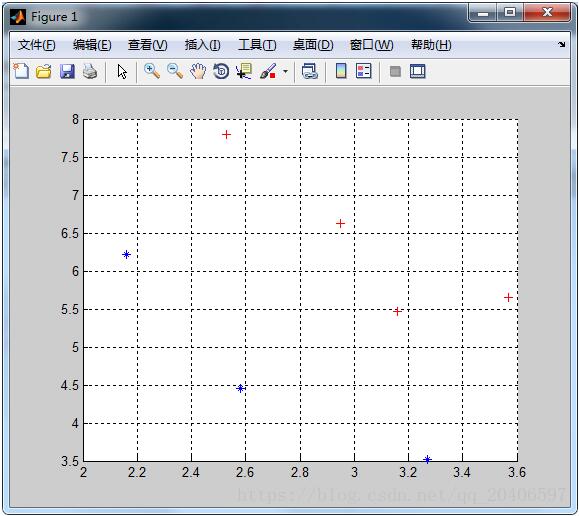
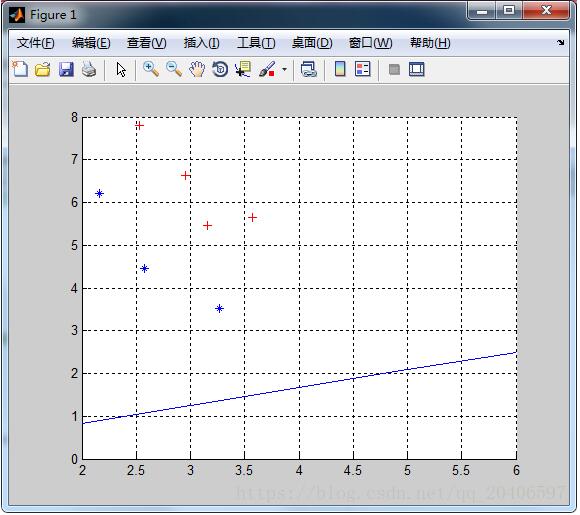
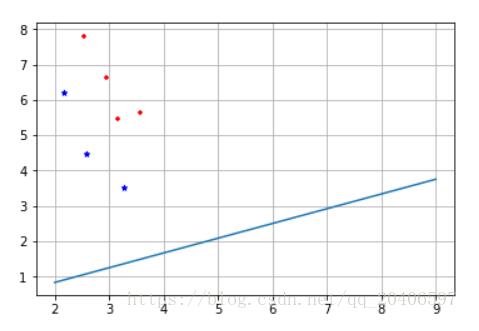
M1 = mean(X1); M2 = mean(X2); M = mean([X1;X2]); %第二步:求类内散度矩阵 p = size(X1,1); q = size(X2,1); a=repmat(M1,4,1); S1=(X1-a)'*(X1-a); b=repmat(M2,3,1); S2=(X2-b)'*(X2-b); Sw=(p*S1+q*S2)/(p+q); %第三步:求类间散度矩阵 sb1=(M1-M)'*(M1-M); sb2=(M2-M)'*(M2-M); Sb=(p*sb1+q*sb2)/(p+q); bb=det(Sw); %第四步:求最大特征值和特征向量 [V,L]=eig(inv(Sw)*Sb); [a,b]=max(max(L)); W = V(:,b);%最大特征值所对应的特征向量 %第五步:画出投影线 k=W(2)/W(1); b=0; x=2:6; yy=k*x+b; plot(x,yy);%画出投影线
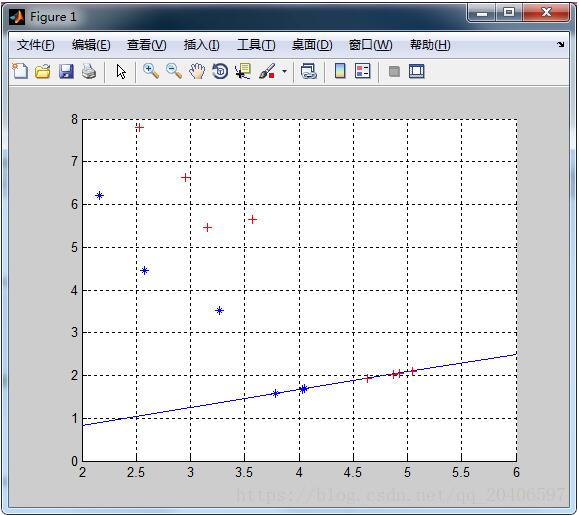
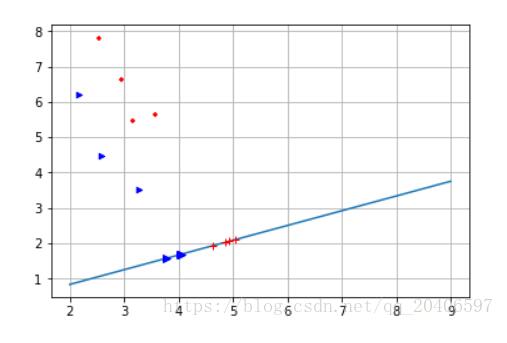
%计算第一类样本在直线上的投影点 xi=[]; for i=1:p y0=X1(i,2); x0=X1(i,1); x1=(k*(y0-b)+x0)/(k^2+1); xi=[xi;x1]; end yi=k*xi+b; XX1=[xi yi]; %计算第二类样本在直线上的投影点 xj=[]; for i=1:q y0=X2(i,2); x0=X2(i,1); x1=(k*(y0-b)+x0)/(k^2+1); xj=[xj;x1]; end yj=k*xj+b; XX2=[xj yj]; % y=W'*[X1;X2]'; plot(XX1(:,1),XX1(:,2),'r+','markerfacecolor', [ 1, 0, 0 ]); plot(XX2(:,1),XX2(:,2),'b*','markerfacecolor', [ 0, 0, 1 ]);
python 实现:
import numpy as np
import matplotlib.pyplot as plt
X=np.loadtxt("22.txt")
pos0=np.where(X[:,2]==0)
print(pos0)
pos1=np.where(X[:,2]==1)
print(pos1)
X1=X[pos0,0:2]
X1=X1[0,:,:]
print(X1,X1.shape)
X2=X[pos1,0:2]
X2=X2[0,:,:]
print(X2,X2.shape)

#第一步,求各个类别的均值 M1=np.mean(X1,0) M1=np.array([M1]) print(M1,M1.shape) M2=np.mean(X2,0) M2=np.array([M2]) print(M2) M=np.mean(X[:,0:2],0) M=np.array([M]) print(M) p=np.size(X1,0) print(p) q=np.size(X2,0) print(q) #第二步,求类内散度矩阵 S1=np.dot((X1-M1).transpose(),(X1-M1)) print(S1) S2=np.dot((X2-M2).transpose(),(X2-M2)) print(S2) Sw=(p*S1+q*S2)/(p+q) print(Sw) #第三步,求类间散度矩阵 Sb1=np.dot((M1-M).transpose(),(M1-M)) print(Sb1) Sb2=np.dot((M2-M).transpose(),(M2-M)) print(Sb2) Sb=(p*Sb1+q*Sb2)/(p+q) print(Sb) #判断Sw是否可逆 bb=np.linalg.det(Sw) print(bb) #第四步,求最大特征值和特征向量 [V,L]=np.linalg.eig(np.dot(np.linalg.inv(Sw),Sb)) print(V,L.shape) list1=[] a=V list1.extend(a) print(list1) b=list1.index(max(list1)) print(a[b]) W=L[:,b] print(W,W.shape) #根据求得的投影向量W画出投影线 k=W[1]/W[0] b=0; x=np.arange(2,10) yy=k*x+b plt.plot(x,yy) plt.scatter(X1[:,0],X1[:,1],marker='+',color='r',s=20) plt.scatter(X2[:,0],X2[:,1],marker='*',color='b',s=20) plt.grid() plt.show()
#计算第一类样本在直线上的投影点 xi=[] yi=[] for i in range(0,p): y0=X1[i,1] x0=X1[i,0] x1=(k*(y0-b)+x0)/(k**2+1) y1=k*x1+b xi.append(x1) yi.append(y1) print(xi) print(yi) #计算第二类样本在直线上的投影点 xj=[] yj=[] for i in range(0,q): y0=X2[i,1] x0=X2[i,0] x1=(k*(y0-b)+x0)/(k**2+1) y1=k*x1+b xj.append(x1) yj.append(y1) print(xj) print(yj) #画出投影后的点 plt.plot(x,yy) plt.scatter(X1[:,0],X1[:,1],marker='+',color='r',s=20) plt.scatter(X2[:,0],X2[:,1],marker='>',color='b',s=20) plt.grid() plt.plot(xi,yi,'r+') plt.plot(xj,yj,'b>') plt.show()
以上这篇Python实现线性判别分析(LDA)的MATLAB方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
您可能感兴趣的文章:
加载全部内容