MySQL中UNION与UNION ALL的基本使用方法
人气:0在数据库中,UNION和UNION ALL关键字都是将两个结果集合并为一个,但这两者从使用和效率上来说都有所不同。
MySQL中的UNION
UNION在进行表链接后会筛选掉重复的记录,所以在表链接后会对所产生的结果集进行排序运算,删除重复的记录再返回结果。实际大部分应用中是不会产生重复的记录,最常见的是过程表与历史表UNION。如:
select * from gc_dfys union select * from ls_jg_dfys
这个SQL在运行时先取出两个表的结果,再用排序空间进行排序删除重复的记录,最后返回结果集,如果表数据量大的话可能会导致用磁盘进行排序。
MySQL中的UNION ALL
而UNION ALL只是简单的将两个结果合并后就返回。这样,如果返回的两个结果集中有重复的数据,那么返回的结果集就会包含重复的数据了。
从效率上说,UNION ALL 要比UNION快很多,所以,如果可以确认合并的两个结果集中不包含重复的数据的话,那么就使用UNION ALL,如下:
select * from gc_dfys union all select * from ls_jg_dfys
使用Union,则所有返回的行都是唯一的,如同您已经对整个结果集合使用了DISTINCT,若果多表查询结果中有完全一致的数据,mysql将自动去重
使用Union all,则不会排重,返回所有的行
如果您想使用ORDER BY或LIMIT子句来对全部UNION结果进行分类或限制,则应对单个地SELECT语句加圆括号,并把ORDER BY或LIMIT放到最后一个的后面:
(SELECT a FROM tbl_name WHERE a=10 AND B=1) UNION (SELECT a FROM tbl_name WHERE a=11 AND B=2) ORDER BY a LIMIT 10;
麻烦一点也可以这么干:
select userid from ( select userid from testa union all select userid from testb) t order by userid limit 0,1;
在子句中。order by 配合limit使用才有意义,如果不配合使用,将被语法分析器优化时除去
如果你还想group by,而且还有条件,那么:
select userid from (select userid from testa union all select userid from testb) t group by userid having count(userid) = 2;
注意:在union的括号后面必须有个别名,否则会报错
当然了,如果当union的几个表的数据量很大时,建议还是采用先导出文本,然后用脚本来执行
因为纯粹用sql,效率会比较低,而且它会写临时文件,如果你的磁盘空间不够大,就有可能会出错
Error writing file '/tmp/MYLsivgK' (Errcode: 28)
例子:
DROP TABLE IF EXISTS `ta`;
CREATE TABLE `ta` (
`id` varchar(255) DEFAULT NULL,
`num` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of ta
-- ----------------------------
INSERT INTO `ta` VALUES ('a', '5');
INSERT INTO `ta` VALUES ('b', '10');
INSERT INTO `ta` VALUES ('c', '15');
INSERT INTO `ta` VALUES ('d', '10');
-- ----------------------------
-- Table structure for `tb`
-- ----------------------------
DROP TABLE IF EXISTS `tb`;
CREATE TABLE `tb` (
`id` varchar(255) DEFAULT NULL,
`num` int(11) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of tb
-- ----------------------------
INSERT INTO `tb` VALUES ('b', '5');
INSERT INTO `tb` VALUES ('c', '15');
INSERT INTO `tb` VALUES ('d', '20');
INSERT INTO `tb` VALUES ('e', '99');
此时 ta tb 对应的c字段的num是一样的
sql:
SELECT id,SUM(num) FROM (
SELECT * FROM ta
UNION ALL
SELECT * FROM tb) as tmp
GROUP BY id
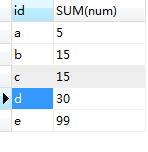
运行结果:

若:
SELECT id,SUM(num) FROM (
SELECT * FROM ta
UNION
SELECT * FROM tb) as tmp
GROUP BY id
运行结果:
使用Union,则所有返回的行都是唯一的,如同您已经对整个结果集合使用了DISTINCT,若果多表查询结果中有完全一致的数据,mysql将自动去重
使用Union all,则不会排重,返回所有的行
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对的支持。
您可能感兴趣的文章:
加载全部内容