关于Pytorch的MNIST数据集的预处理详解
人气:0关于Pytorch的MNIST数据集的预处理详解
MNIST的准确率达到99.7%
用于MNIST的卷积神经网络(CNN)的实现,具有各种技术,例如数据增强,丢失,伪随机化等。
操作系统:ubuntu18.04
显卡:GTX1080ti
python版本:2.7(3.7)
网络架构
具有4层的CNN具有以下架构。
输入层:784个节点(MNIST图像大小)
第一卷积层:5x5x32
第一个最大池层
第二卷积层:5x5x64
第二个最大池层
第三个完全连接层:1024个节点
输出层:10个节点(MNIST的类数)
用于改善CNN性能的工具
采用以下技术来改善CNN的性能。
1. Data augmentation
通过以下方式将列车数据的数量增加到5倍
随机旋转:每个图像在[-15°,+ 15°]范围内随机旋转。
随机移位:每个图像在两个轴上随机移动一个范围为[-2pix,+ 2pix]的值。
零中心归一化:将像素值减去(PIXEL_DEPTH / 2)并除以PIXEL_DEPTH。
2. Parameter initializers
重量初始化器:xaiver初始化器
偏差初始值设定项:常量(零)初始值设定项
3. Batch normalization
所有卷积/完全连接的层都使用批量标准化。
4. Dropout
The third fully-connected layer employes dropout technique.
5. Exponentially decayed learning rate
A learning rate is decayed every after one-epoch.
代码部分
第一步:了解MNIST数据集
MNIST数据集是一个手写体数据集,一共60000张图片,所有的图片都是28×28的,下载数据集的地址:数据集官网。这个数据集由四部分组成,分别是:
train-images-idx3-ubyte.gz: training set images (9912422 bytes) train-labels-idx1-ubyte.gz: training set labels (28881 bytes) t10k-images-idx3-ubyte.gz: test set images (1648877 bytes) t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
也就是一个训练图片集,一个训练标签集,一个测试图片集,一个测试标签集;我们可以看出这个其实并不是普通的文本文件
或是图片文件,而是一个压缩文件,下载并解压出来,我们看到的是二进制文件。
第二步:加载MNIST数据集
先引入一些库文件
import torchvision,torch import torchvision.transforms as transforms from torch.utils.data import Dataset, DataLoader import matplotlib.pyplot as plt
加载MNIST数据集有很多方法:
方法一:在pytorch下可以直接调用torchvision.datasets里面的MNIST数据集(这是官方写好的数据集类)
train = torchvision.datasets.MNIST(root='./mnist/',train=True, transform= transforms.ToTensor())
返回值为一个元组(train_data,train_target)(这个类使用的时候也有坑,必须用train[i]索引才能使用 transform功能)
一般是与torch.utils.data.DataLoader配合使用
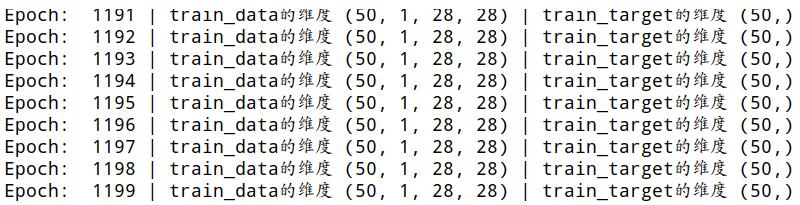
dataloader = DataLoader(train, batch_size=50,shuffle=True, num_workers=4) for step, (x, y) in enumerate(dataloader): b_x = x.shape b_y = y.shape print 'Step: ', step, '| train_data的维度' ,b_x,'| train_target的维度',b_y
如图将60000张图片的数据分为1200份,每份包含50张图像,这样并行处理数据能有效加快计算速度
看个人喜好,本人不太喜欢这种固定的数据类,所以想要灵活多变,可以开始自己写数据集类
方法二:自己设置数据集
使用pytorch相关类,API对数据集进行封装,pytorch中数据集相关的类位于torch.utils.data package中。
本次实验,主要使用以下类:
torch.utils.data.Dataset
torch.utils.data.DataLoader
Dataset类的使用: 所有的类都应该是此类的子类(也就是说应该继承该类)。 所有的子类都要重写(override) len(), getitem() 这两个方法。
使用到的python package
| python package | 目的 |
|---|---|
numpy |
矩阵操作,对图像进行转置 |
skimage |
图像处理,图像I/O,图像变换 |
matplotlib |
图像的显示,可视化 |
os |
一些文件查找操作 |
torch |
pytorch |
torvision |
pytorch |
导入相关的包
import numpy as np from skimage import io from skimage import transform import matplotlib.pyplot as plt import os import torch import torchvision from torch.utils.data import Dataset, DataLoader from torchvision.transforms import transforms from PIL import Image
第一步:
定义一个子类,继承Dataset类, 重写 __len()__, __getitem()__ 方法。
细节:
1.数据集一个样本的表示:采用字典的形式sample = {'img': img, 'target': target}。
图像的读取:采用torch.load进行读取,读取之后的结果为torch.Tensor形式。
图像变换:transform参数
class MY_MNIST(Dataset):
training_file = 'training.pt'
test_file = 'test.pt'
def __init__(self, root, transform=None):
self.transform = transform
self.data, self.targets = torch.load(root)
def __getitem__(self, index):
img, target = self.data[index], int(self.targets[index])
img = Image.fromarray(img.numpy(), mode='L')
if self.transform is not None:
img = self.transform(img)
img =transforms.ToTensor()(img)
sample = {'img': img, 'target': target}
return sample
def __len__(self):
return len(self.data)
train = MY_MNIST(root='./mnist/MNIST/processed/training.pt', transform= None)
第二步
实例化一个对象,并读取和显示数据集
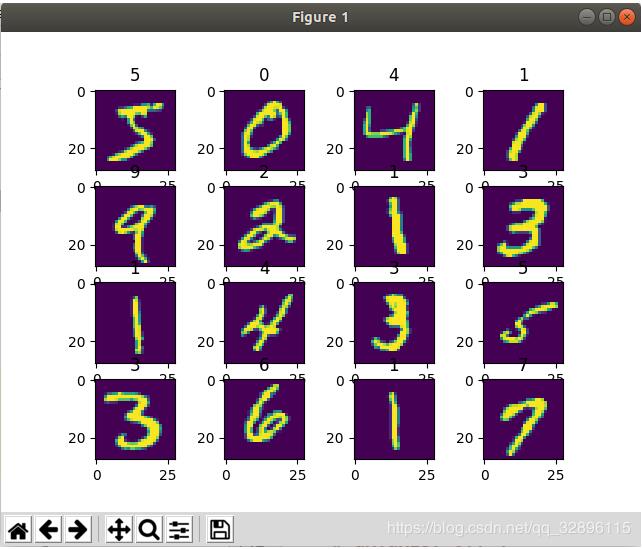
for (cnt,i) in enumerate(train):
image = i['img']
label = i['target']
ax = plt.subplot(4, 4, cnt+1)
# ax.axis('off')
ax.imshow(image.squeeze(0))
ax.set_title(label)
plt.pause(0.001)
if cnt ==15:
break
输出如下 ,这样就表明,咱们自己写的数据集读取图像,并读取之后的结果为torch.Tensor形式成功啦!
第三步(可选 optional)
对数据集进行变换:一般收集到的图像大小尺寸,亮度等存在差异,变换的目的就是使得数据归一化。另一方面,可以通过变换进行数据增强
关于pytorch中的变换transforms,请参考该系列之前的文章
由于数据集中样本采用字典dicts形式表示。 因此不能直接调用torchvision.transofrms中的方法。
本实验进行了旋转,随机裁剪,调节图像的色彩饱和明暗等操作。
compose = transforms.Compose([
transforms.Resize(20),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(20),
transforms.ColorJitter(brightness=1, contrast=0.1, hue=0.5),
# transforms.ToTensor(),
# transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
train_transformed = MY_MNIST(root='./mnist/MNIST/processed/training.pt', transform= compose)
#显示变换后的图像
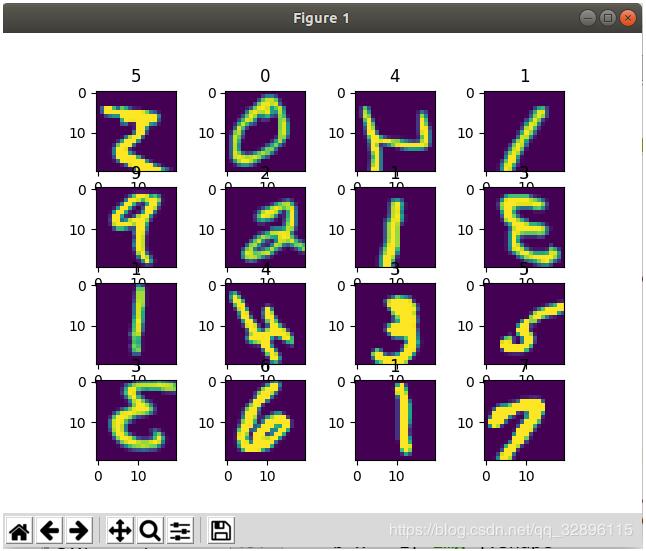
for (cnt,i) in enumerate(train_transformed):
image = i['img']
# print image[0].sum()
# image = compose(image)
print 'sdsdadfasfasfasf',type(image)
label = i['target']
ax = plt.subplot(4, 4, cnt+1)
# ax.axis('off')
ax.imshow(image.squeeze(0))
ax.set_title(label)
plt.pause(0.001)
if cnt ==15:
break
变换后的图像,和之前对比,你发现了什么不同吗?
第四步: 使用DataLoader进行包装
为何要使用DataLoader?
① 深度学习的输入是mini_batch形式
② 样本加载时候可能需要随机打乱顺序,shuffle操作
③ 样本加载需要采用多线程
pytorch提供的DataLoader封装了上述的功能,这样使用起来更方便。
# 使用DataLoader可以利用多线程,batch,shuffle等
trainset_dataloader = DataLoader(dataset=transformed_trainset,
batch_size=4,
shuffle=True,
num_workers=4)
可视化:
dataloader = DataLoader(train, batch_size=50,shuffle=True, num_workers=4)
通过DataLoader包装之后,样本以min_batch形式输出,而且进行了随机打乱顺序。
for step, i in enumerate(dataloader): b_x = i['img'].shape b_y = i['target'].shape print 'Step: ', step, '| train_data的维度' ,b_x,'| train_target的维度',b_y
如图图片大小已经裁剪为20*20,而且并行处理让60000个数据在3秒内就能处理好,效率非常高
Step: 1186 | train_data的维度 (50, 1, 20, 20) | train_target的维度 (50,) Step: 1187 | train_data的维度 (50, 1, 20, 20) | train_target的维度 (50,) Step: 1188 | train_data的维度 (50, 1, 20, 20) | train_target的维度 (50,) Step: 1189 | train_data的维度 (50, 1, 20, 20) | train_target的维度 (50,) Step: 1190 | train_data的维度 (50, 1, 20, 20) | train_target的维度 (50,) Step: 1191 | train_data的维度 (50, 1, 20, 20) | train_target的维度 (50,) Step: 1192 | train_data的维度 (50, 1, 20, 20) | train_target的维度 (50,) Step: 1193 | train_data的维度 (50, 1, 20, 20) | train_target的维度 (50,) Step: 1194 | train_data的维度 (50, 1, 20, 20) | train_target的维度 (50,) Step: 1195 | train_data的维度 (50, 1, 20, 20) | train_target的维度 (50,) Step: 1196 | train_data的维度 (50, 1, 20, 20) | train_target的维度 (50,) Step: 1197 | train_data的维度 (50, 1, 20, 20) | train_target的维度 (50,) Step: 1198 | train_data的维度 (50, 1, 20, 20) | train_target的维度 (50,) Step: 1199 | train_data的维度 (50, 1, 20, 20) | train_target的维度 (50,)
未完待续…
以上这篇关于Pytorch的MNIST数据集的预处理详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
您可能感兴趣的文章:
加载全部内容