python 破解网站反爬虫 详解python 破解网站反爬虫的两种简单方法
DA1YuH 人气:0最近在学爬虫时发现许多网站都有自己的反爬虫机制,这让我们没法直接对想要的数据进行爬取,于是了解这种反爬虫机制就会帮助我们找到解决方法。
常见的反爬虫机制有判别身份和IP限制两种,下面我们将一一来进行介绍。
(一) 判别身份
首先我们看一个例子,看看到底什么时反爬虫。
我们还是以 豆瓣电影榜top250(https://movie.douban.com/top250) 为例。`
import requests # 豆瓣电影榜top250的网址 url = 'https://movie.douban.com/top250' # 请求与网站的连接 res = requests.get(url) # 打印获取的文本 print(res.text)
这是段简单的请求与网站连接并打印获取数据的代码,我们来看看它的运行结果。

我们可以发现我们什么数据都没有获取到,这就是由于这个网站有它的身份识别功能,把我们识别为了爬虫,拒绝为我们提供数据。不管是浏览器还是爬虫访问网站时都会带上一些信息用于身份识别。而这些信息都被存储在一个叫请求头(request headers) 的地方。而这个请求头中我们只需要了解其中的一个叫user-agent(用户代理) 的就可以了。user-agent里包含了操作系统、浏览器类型、版本等信息,通过修改它我们就能成功地伪装成浏览器。
下面我们来看怎么找这个user-agent吧。
首先得打开浏览器,随便打开一个网站,再打开开发者工具。
再点击network标签,接着点第一个请求,再找到Request Headers,最后找到user-agent字段。(有时候可能点击network标签后是空白得,这时候刷新下网页就好啦!)
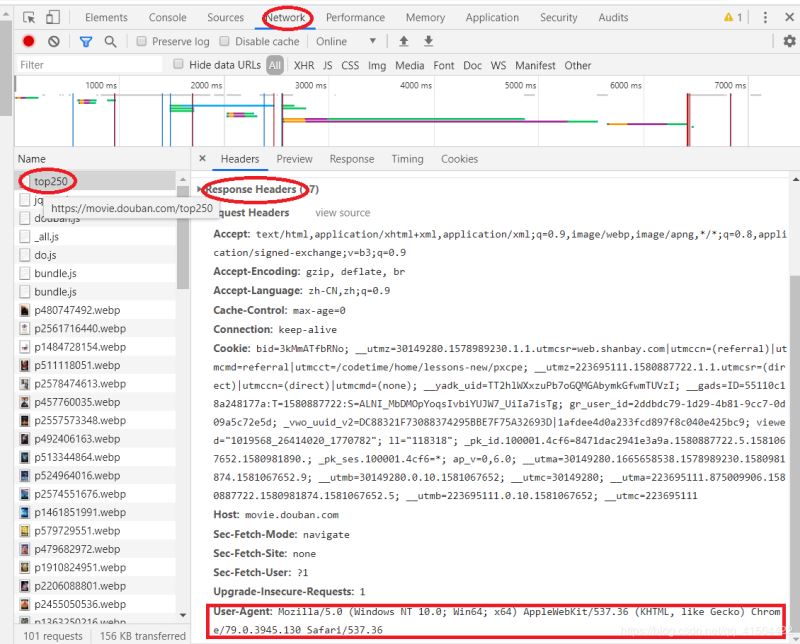
找到请求头后,我们只需要把他放进一个字典里就好啦,具体操作见下面代码。
import requests
# 复制刚才获取得请求头
headers = {
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
# 豆瓣电影榜top250的网址
url = 'https://movie.douban.com/top250'
# 请求与网站的连接
res = requests.get(url, headers=headers)
# 打印获取的文本
print(res.text)
现在我们再来看部分输出结果。

我们可以发现已经将该网站的HTML文件全部爬取到了,至此第一种方法就将完成了。下面我们来看第二种方法。
(二) IP限制
IP(Internet Protocol) 全称互联网协议地址,意思是分配给用户上网使用的网际协议的设备的数字标签。它就像我们SFZ号一样,只要知道你的SFZ号就能查出你是哪个人。
当我们爬取大量数据时,如果我们不加以节制地访问目标网站,会使网站超负荷运转,一些个人小网站没什么反爬虫措施可能因此瘫痪。而大网站一般会限制你的访问频率,因为正常人是不会在 1s 内访问几十次甚至上百次网站的。所以,如果你访问过于频繁,即使改了 user-agent 伪装成浏览器了,也还是会被识别为爬虫,并限制你的 IP 访问该网站。
因此,我们常常使用 time.sleep() 来降低访问的频率,比如上一篇博客中的爬取整个网站的代码,我们每爬取一个网页就暂停一秒。
import requests
import time
from bs4 import BeautifulSoup
# 将获取豆瓣电影数据的代码封装成函数
def get_douban_movie(url):
# 设置反爬虫的请求头
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
# 请求网站的连接
res = requests.get('https://movie.douban.com/top250', headers=headers)
# 将网站数据存到BeautifulSoup对象中
soup = BeautifulSoup(res.text,'html.parser')
# 爬取网站中所有标签为'div',并且class='pl2'的数据存到Tag对象中
items = soup.find_all('div', class_='hd')
for i in items:
# 再筛选出所有标签为a的数据
tag = i.find('a')
# 只读取第一个class='title'作为电影名
name = tag.find(class_='title').text
# 爬取书名对应的网址
link = tag['href']
print(name,link)
url = 'https://movie.douban.com/top250?start={}&filter='
# 将所有网址信息存到列表中
urls = [url.format(num*25) for num in range(10)]
for item in urls:
get_douban_movie(item)
# 暂停 1 秒防止访问太快被封
time.sleep(1)
部分运行结果:
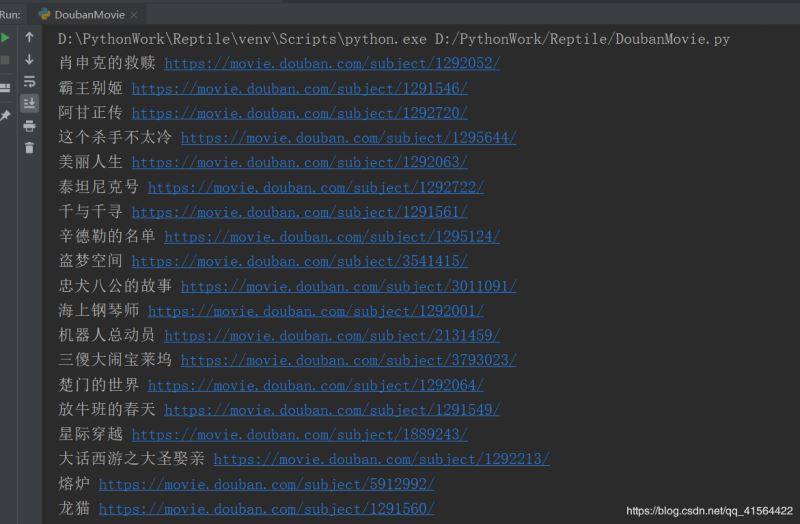
至此两种比较简单的应对反爬虫方法就讲完啦,希望能对大家有所帮助,如果有问题,请及时给予我指正,感激不尽!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
您可能感兴趣的文章:
加载全部内容