Pandas 数据去重 pandas中的数据去重处理的实现方法
我是小蚂蚁 人气:0数据去重可以使用duplicated()和drop_duplicates()两个方法。
DataFrame.duplicated(subset = None,keep =‘first' )返回boolean Series表示重复行
参数:
subset:列标签或标签序列,可选
仅考虑用于标识重复项的某些列,默认情况下使用所有列
keep:{‘first',‘last',False},默认'first'
- first:标记重复,True除了第一次出现。
- last:标记重复,True除了最后一次出现。
- 错误:将所有重复项标记为True。
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
df = pd.read_csv('./demo_duplicate.csv')
print(df)
print(df['Seqno'].unique()) # [0. 1.]
# 使用duplicated 查看 重复值
# 参数 keep 可以标记重复值 {'first','last',False}
print(df['Seqno'].duplicated())
'''
0 False
1 True
2 True
3 True
4 False
Name: Seqno, dtype: bool
'''
# 删除 series 重复数据
print(df['Seqno'].drop_duplicates())
'''
0 0.0
4 1.0
Name: Seqno, dtype: float64
'''
# 删除 dataframe 重复数据
print(df.drop_duplicates(['Seqno'])) # 按照 Seqno 来 去重
'''
Price Seqno Symbol time
0 1623.0 0.0 APPL 1473411962
4 1649.0 1.0 APPL 1473411963
'''
# drop_dujplicates() 第二个参数 keep 包含的值 有: first、last、False
print(df.drop_duplicates(['Seqno'], keep='last')) # 保存最后一个
'''
Price Seqno Symbol time
3 1623.0 0.0 APPL 1473411963
4 1649.0 1.0 APPL 1473411963
'''
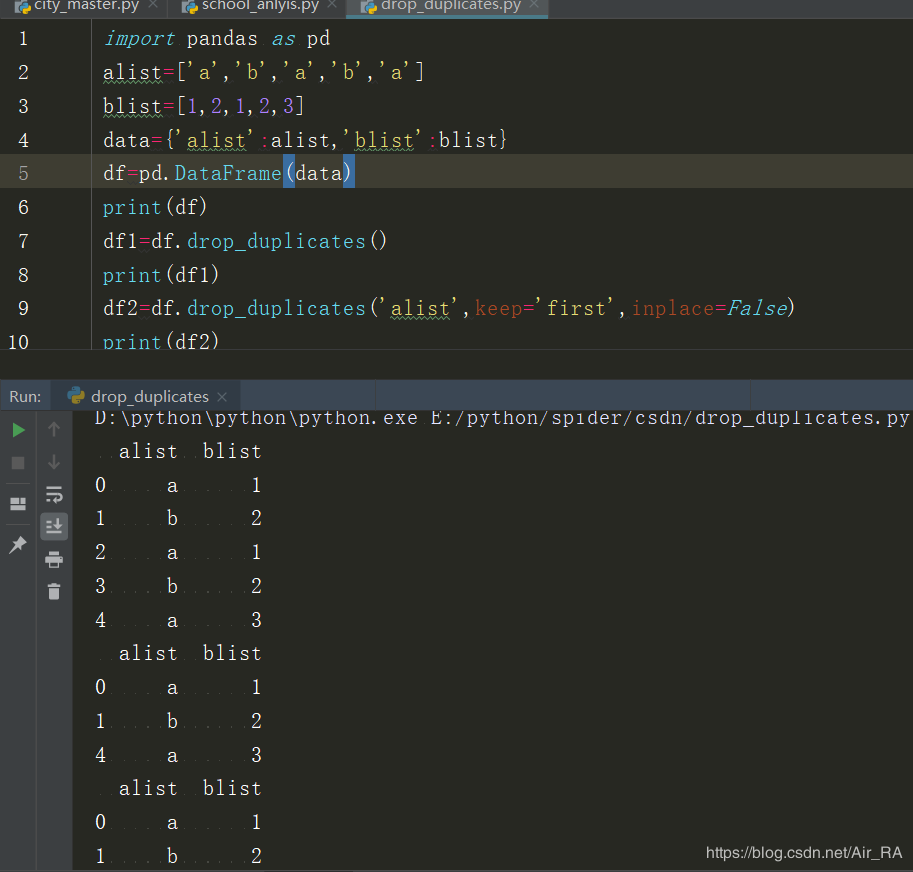
pandas 去除重复行
DataFrame.drop_duplicates(subset = None,keep ='first',inplace = False )
subset : 指定列,默认情况下使用所有列
keep : {'first','last',False},默认'first'
first :删除重复项保留第一次出现的。last :删除重复项保留最后一次出现的。false:删除所有重复项。
inplace : 布尔值,默认为False 是否删除重复项或返回副本
栗子:
您可能感兴趣的文章:
加载全部内容