MongoDB 那些事(一文以蔽之)
东山絮柳仔 人气:0前言
身边一直都有小伙伴在问:MongoDB到底是什么?它有到底什么特性?有什么与众不同?在什么情况下使用MongoDB最合适?以什么样的姿势是最好的?难道就一定要用吗?....说实话,这些问题都问到精髓了,也看得出来你们的急切和真切。有时候大家都比较忙,很难抽出一天的时间,坐而论道,把这些问题掰扯清楚,然后忽如睡醒,豁然开悟。当然,个人也不是专业的”布道者“,所以,通过电话、微信、QQ、钉钉或者其它的办公聊天软件,让我几句话给大家说明白,有些困难,也不切实际。所以,难免有时候,你们是曼联藏不住的哀怨,我也是意犹未尽。现在,我把我前两年分享的一个PPT,分享给大家,希望通过这个分享,能让大家对MongoDB有一个相对整体的全面认识。
第一部分 概述
1.1 MongoDB 初识

1.2 MongoDB“江湖”地位
名副其实的 名列前茅、青年才俊
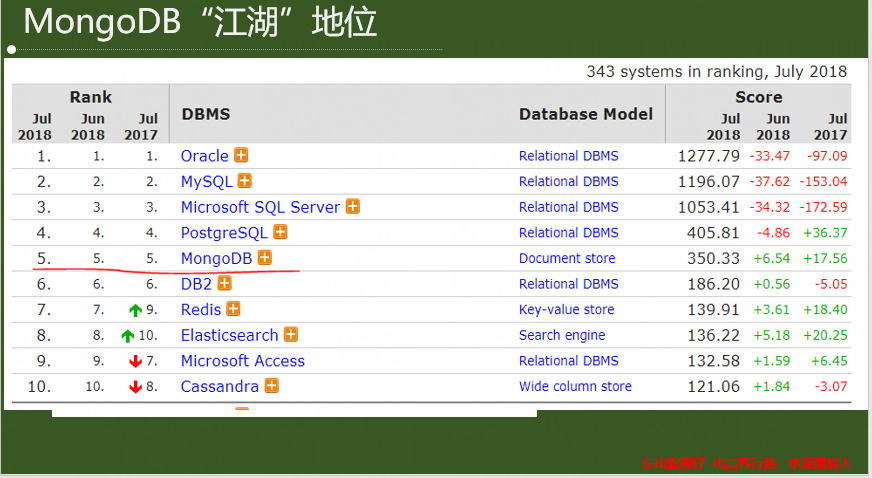
广受好评 迷弟迷妹 众多

未来可期,潜力股

两年已过,热度不减,你的地位依然无可替代

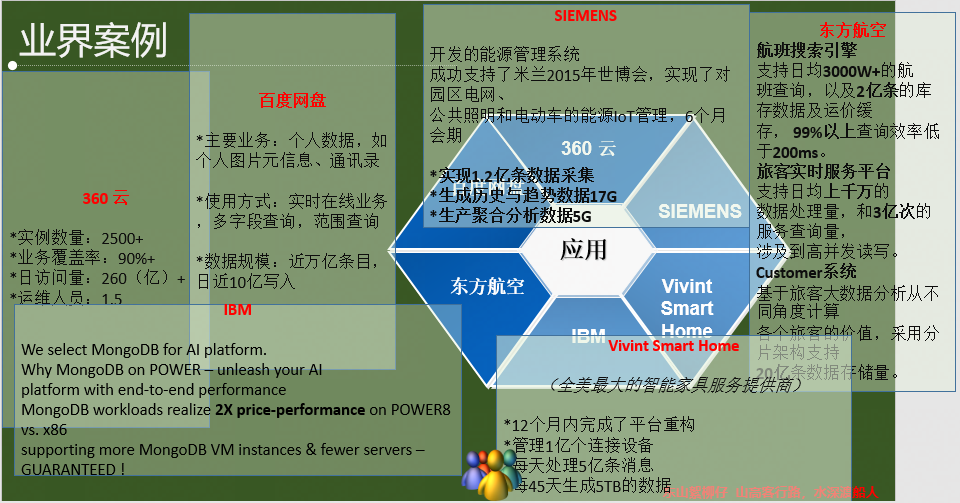
1.3 业界案例
第二部分 MongoDB 特性
2.1 特性之动态文档模型
2.2 特性之副本集

复制集的作用:
(1)高可用,防止设备(服务器、网络)故障。提供自动FailOver功能;
(2)灾难恢复,当发生故障时,可以从其它节点快速恢复;
(3)功能隔离,用于分析、报表,数据挖掘,系统任务等;用于备份。
复制集成员最多50个。参与Primary选举投票的成员最多7个,其他成员的votes属性必须设置为0,即不参与投票。
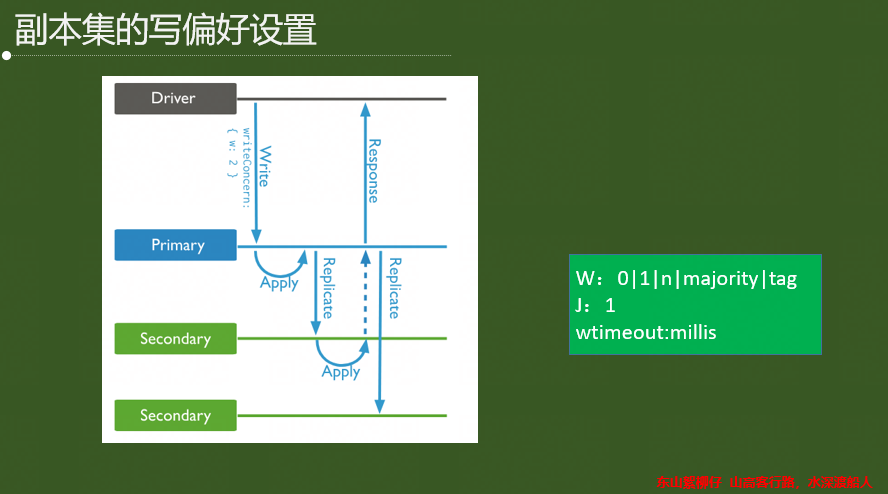
写关注机制WriteConcert;用来指定MongoDB对写操作的回执行为。
可在connection level 或者写操作level指定。

2.3 特性之分片
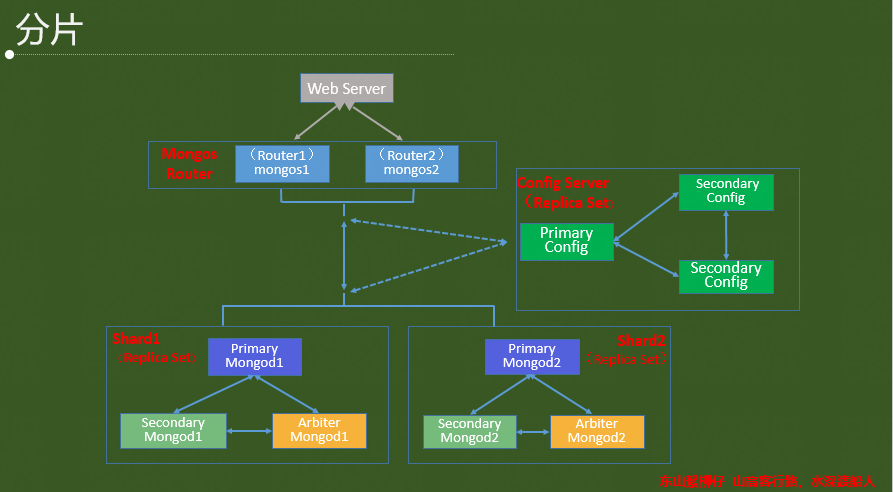
分片(sharding)的优势
A.对集群进行抽象,让集群“不可见”,分片对应用系统是透明的
MongoDB自带了一个叫做mongos的专有路由进程。mongos就是掌握统一路口的路由器,其会将客户端发来的请求准确无误的路由到集群中的一个或者一组服务器上,同时会把接收到的响应拼装起来发回到客户端。
B.保证集群总是可读写
MongoDB通过多种途径来确保集群的可用性和可靠性。将MongoDB的分片和复制集功能结合使用,在确保数据分片到多台服务器的同时,也确保了每分数据都有相应的备份,可以确保有服务器坏掉时,其他的从库可以立即接替坏掉的部分继续工作。
C.使集群易于扩展
当系统需要更多的空间和资源的时候,MongoDB使我们可以按需方便的扩充系统容量。
分片(sharding)的组件
A. Mongos
Mongos作为Sharding Cluster的访问入口,所有的请求都由mongos来路由、分发、合并,这些动作对客户端driver透明,用户连接mongos就像连接mongod一样使用。Mongos会根据请求类型及shard key将请求路由到对应的Shard。
B.Config Server
Config Server 存储Sharding Cluster 的所有元数据,所有的元数据都存储在config数据库:
*保存每个分片上的chunk的信息 * 保存chunk上的片键范围。
C.Shard
Shard 存储应用数据记录。Chunk size 默认是64M。
(1)分片键决定了文档在集群中的位置;(2)分片键必须有索引;(3)分片键大小限制在512bytes;(4)MongoDB不接受已进行collection 级分片的collection上插入无分片键的文档(也不支持空值插入);(5) 一旦集合已经分片,就不可以直接修改分片键。
分片(sharding)的分割和迁移
分割和迁移 MongoDB底层依赖2个机制来保持集群的平衡:分割和迁移。分割是把一个大的数据块分割为2个更小的数据块的过程。迁移就是在分片之间移动数据块的过程。当某些分片服务器包含的数据块数据量大大超过其他分片服务器时就会触发迁移的过程,这个触发器叫做迁移回合(migration round)
| Number of Chunks Migration | Threshold |
| Less then 20 | 2 |
| 21-80 | 4 |
| Greater than 80 | 8 |
迁移工作谁来做?
自动:3.2 版本里,Mongos有个后台的Balance任务,该任务不断来判断是否需要迁移,如果需要,则发送moveChunk命令到源shard上开始迁移。
手动:用户能主动触发数据迁移,还可以手动关停、指定运行时间窗口。
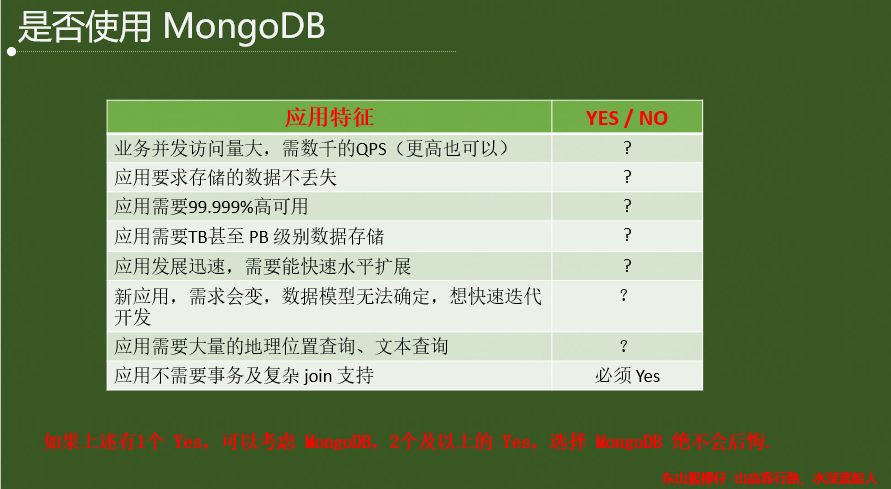
2.4 使用MongoDB的场景
第三部分 基本操作
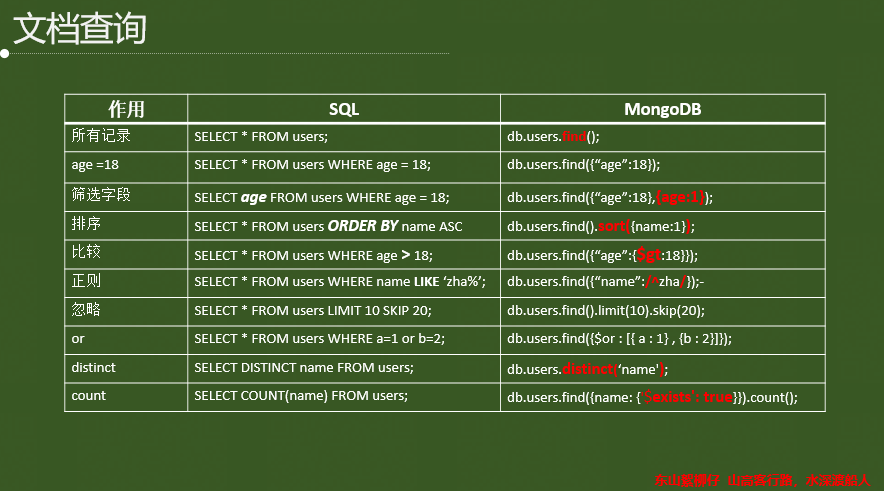
3.1 查询操作
3.2 插入操作

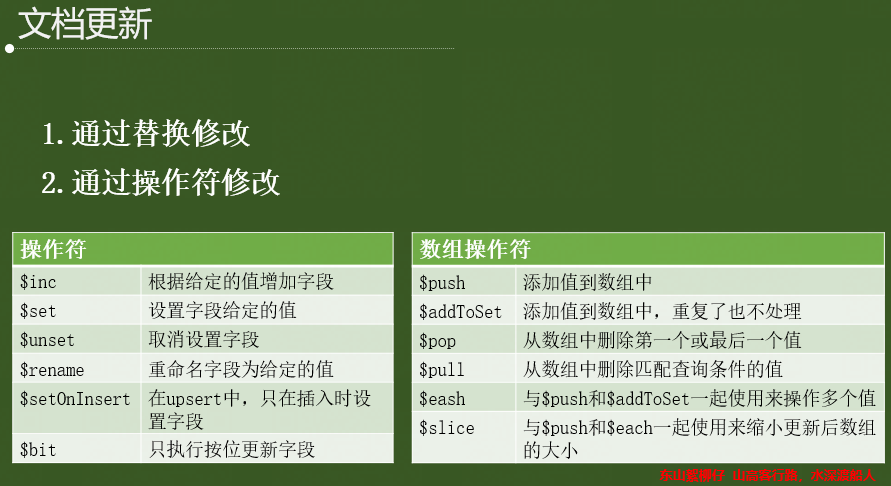
3.3 更新操作
3.4 聚合操作
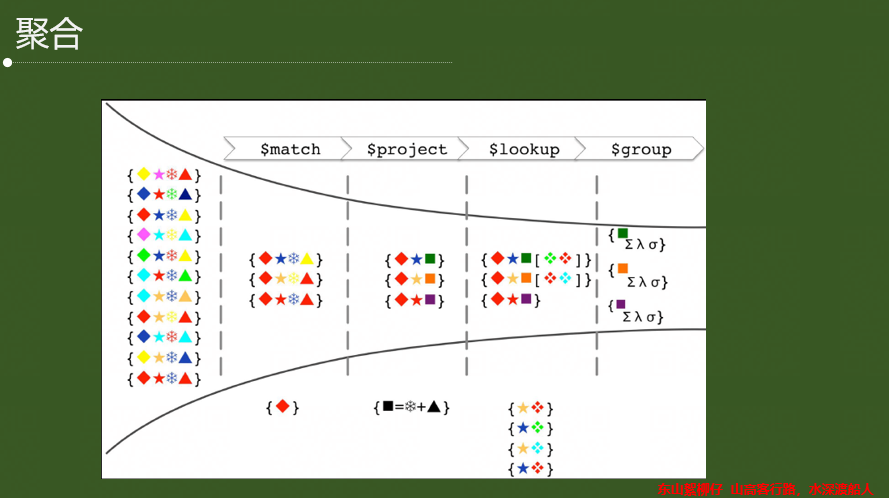
(1)MongoDB提供了两种内置分析数据的方法:Map Reduce和Aggregation框架。聚合框架,第一在MongoDB2.2 中引入,每一次新版本发布都会更新。MongoDB 2.6 加入了许多更新,框架也相对成熟了。
(2)其他聚合功能:.count() 和.distinct()。
(3)map-reduces是MongoDB提供灵活聚合功能的首次尝试。使用map-reduce,可以使用JavaScript定义整个处理流程。这提供了很大的灵活性,但是比聚合框架性能要低得多。此外,编写map-reduce的过程相对复杂,比聚合框架更加难以理解。
(4)虽然map-reduce提供了JavaScript的灵活性,但是它限制了必须是单线程和解释性的模式。聚合框架是作为原生C++和多线程模式执行的。虽然map-reduce没有被淘汰,但是未来的改进都会在集合框架上进行的。
第四部分 性能优化
4.1 性能诊断

4.2 性能优化之模式设计
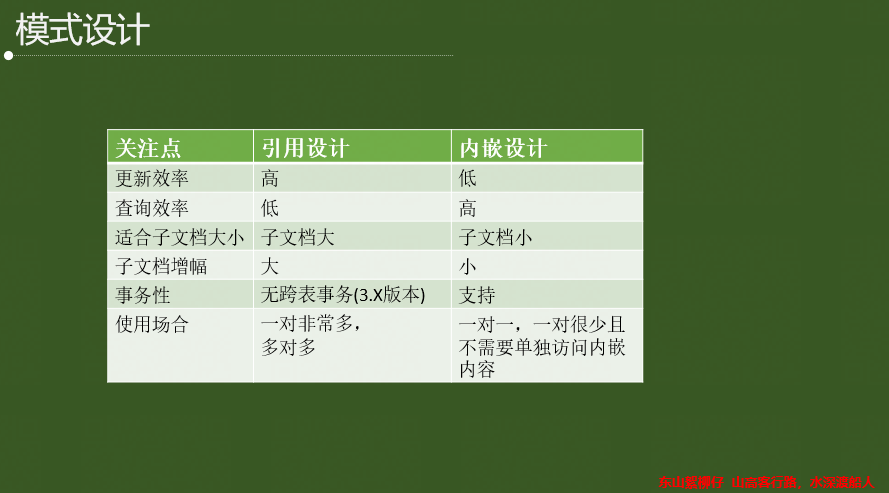
(1)业务驱动,而非数据驱动;
(2)不要按照关系型来设计表结构,建议更多使用内嵌方式;
(3)数据库集合(collection)的数量不宜太多;
(4)数据冗余是可以接受的。
4.3 性能优化之索引设计

(1)重复率越低越适合做索引;状态、性别等不适合建立索引;
(2)对于包含多个键的查询,创建包含这些键的复合索引是个不错的解决方案。复合索引的键值顺序很重要,理解索引最左前缀原则;
(3)有添加尽量匹配覆盖索引;
(4)稀疏索引:不存储Null信息的索引,(3.2以上才有,不能当做分片的片键);局部索引(稀疏索引进化版);
(5)后台创建索引;
(6)文本索引一个重要的不同是一个集合只有一个文本索引;
(7)文字搜索索引提供的功能快速单词搜素的索引、匹配精确字段、使用特定单词或者句子排序文档、支持多语言、基于匹配度对查询结果打分。
IT打工人,码字不易,转载分享请注明出处,谢谢配合!!!
加载全部内容