python验证码识别之滴水算法分割图片 python验证码识别教程之利用滴水算法分割图片
Hi!Roy! 人气:0滴水算法概述
滴水算法是一种用于分割手写粘连字符的算法,与以往的直线式地分割不同 ,它模拟水滴的滚动,通过水滴的滚动路径来分割字符,可以解决直线切割造成的过分分割问题。
引言
之前提过对于有粘连的字符可以使用滴水算法来解决分割,但智商捉急的我实在是领悟不了这个算法的精髓,幸好有小伙伴已经实现相关代码。
我对上面的代码进行了一些小修改,同时升级为python3的代码。
还是以这张图片为例:
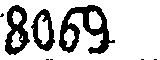
在以前的我们已经知道这种简单的粘连可以通过控制阈值来实现分割,这里我们使用滴水算法。
首先使用之前文章中介绍的垂直投影或者连通域先进行一次切割处理,得到结果如下:

针对于最后粘连情况来使用滴水算法处理:
from itertools import groupby
def binarizing(img,threshold):
"""传入image对象进行灰度、二值处理"""
img = img.convert("L") # 转灰度
pixdata = img.load()
w, h = img.size
# 遍历所有像素,大于阈值的为黑色
for y in range(h):
for x in range(w):
if pixdata[x, y] < threshold:
pixdata[x, y] = 0
else:
pixdata[x, y] = 255
return img
def vertical(img):
"""传入二值化后的图片进行垂直投影"""
pixdata = img.load()
w,h = img.size
result = []
for x in range(w):
black = 0
for y in range(h):
if pixdata[x,y] == 0:
black += 1
result.append(black)
return result
def get_start_x(hist_width):
"""根据图片垂直投影的结果来确定起点
hist_width中间值 前后取4个值 再这范围内取最小值
"""
mid = len(hist_width) // 2 # 注意py3 除法和py2不同
temp = hist_width[mid-4:mid+5]
return mid - 4 + temp.index(min(temp))
def get_nearby_pix_value(img_pix,x,y,j):
"""获取临近5个点像素数据"""
if j == 1:
return 0 if img_pix[x-1,y+1] == 0 else 1
elif j ==2:
return 0 if img_pix[x,y+1] == 0 else 1
elif j ==3:
return 0 if img_pix[x+1,y+1] == 0 else 1
elif j ==4:
return 0 if img_pix[x+1,y] == 0 else 1
elif j ==5:
return 0 if img_pix[x-1,y] == 0 else 1
else:
raise Exception("get_nearby_pix_value error")
def get_end_route(img,start_x,height):
"""获取滴水路径"""
left_limit = 0
right_limit = img.size[0] - 1
end_route = []
cur_p = (start_x,0)
last_p = cur_p
end_route.append(cur_p)
while cur_p[1] < (height-1):
sum_n = 0
max_w = 0
next_x = cur_p[0]
next_y = cur_p[1]
pix_img = img.load()
for i in range(1,6):
cur_w = get_nearby_pix_value(pix_img,cur_p[0],cur_p[1],i) * (6-i)
sum_n += cur_w
if max_w < cur_w:
max_w = cur_w
if sum_n == 0:
# 如果全黑则看惯性
max_w = 4
if sum_n == 15:
max_w = 6
if max_w == 1:
next_x = cur_p[0] - 1
next_y = cur_p[1]
elif max_w == 2:
next_x = cur_p[0] + 1
next_y = cur_p[1]
elif max_w == 3:
next_x = cur_p[0] + 1
next_y = cur_p[1] + 1
elif max_w == 5:
next_x = cur_p[0] - 1
next_y = cur_p[1] + 1
elif max_w == 6:
next_x = cur_p[0]
next_y = cur_p[1] + 1
elif max_w == 4:
if next_x > cur_p[0]:
# 向右
next_x = cur_p[0] + 1
next_y = cur_p[1] + 1
if next_x < cur_p[0]:
next_x = cur_p[0]
next_y = cur_p[1] + 1
if sum_n == 0:
next_x = cur_p[0]
next_y = cur_p[1] + 1
else:
raise Exception("get end route error")
if last_p[0] == next_x and last_p[1] == next_y:
if next_x < cur_p[0]:
max_w = 5
next_x = cur_p[0] + 1
next_y = cur_p[1] + 1
else:
max_w = 3
next_x = cur_p[0] - 1
next_y = cur_p[1] + 1
last_p = cur_p
if next_x > right_limit:
next_x = right_limit
next_y = cur_p[1] + 1
if next_x < left_limit:
next_x = left_limit
next_y = cur_p[1] + 1
cur_p = (next_x,next_y)
end_route.append(cur_p)
return end_route
def get_split_seq(projection_x):
split_seq = []
start_x = 0
length = 0
for pos_x, val in enumerate(projection_x):
if val == 0 and length == 0:
continue
elif val == 0 and length != 0:
split_seq.append([start_x, length])
length = 0
elif val == 1:
if length == 0:
start_x = pos_x
length += 1
else:
raise Exception('generating split sequence occurs error')
# 循环结束时如果length不为0,说明还有一部分需要append
if length != 0:
split_seq.append([start_x, length])
return split_seq
def do_split(source_image, starts, filter_ends):
"""
具体实行切割
: param starts: 每一行的起始点 tuple of list
: param ends: 每一行的终止点
"""
left = starts[0][0]
top = starts[0][1]
right = filter_ends[0][0]
bottom = filter_ends[0][1]
pixdata = source_image.load()
for i in range(len(starts)):
left = min(starts[i][0], left)
top = min(starts[i][1], top)
right = max(filter_ends[i][0], right)
bottom = max(filter_ends[i][1], bottom)
width = right - left + 1
height = bottom - top + 1
image = Image.new('RGB', (width, height), (255,255,255))
for i in range(height):
start = starts[i]
end = filter_ends[i]
for x in range(start[0], end[0]+1):
if pixdata[x,start[1]] == 0:
image.putpixel((x - left, start[1] - top), (0,0,0))
return image
def drop_fall(img):
"""滴水分割"""
width,height = img.size
# 1 二值化
b_img = binarizing(img,200)
# 2 垂直投影
hist_width = vertical(b_img)
# 3 获取起点
start_x = get_start_x(hist_width)
# 4 开始滴水算法
start_route = []
for y in range(height):
start_route.append((0,y))
end_route = get_end_route(img,start_x,height)
filter_end_route = [max(list(k)) for _,k in groupby(end_route,lambda x:x[1])] # 注意这里groupby
img1 = do_split(img,start_route,filter_end_route)
img1.save('cuts-d-1.png')
start_route = list(map(lambda x : (x[0]+1,x[1]),filter_end_route)) # python3中map不返回list需要自己转换
end_route = []
for y in range(height):
end_route.append((width-1,y))
img2 = do_split(img,start_route,end_route)
img2.save('cuts-d-2.png')
if __name__ == '__main__':
p = Image.open("cuts-2.png")
drop_fall(p)
执行后会得到切分后的2个照片:

从这张图片来看,虽然切分成功但是效果比较一般。另外目前的代码只能对2个字符粘连的情况切分,参悟了滴水算法精髓的小伙伴可以试着改成多个字符粘连的情况。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对的支持。
加载全部内容