Mysql提升大数据表拷贝效率 Mysql提升大数据表拷贝效率的解决方案
陈钦 人气:0前言
本文主要给大家介绍了关于Mysql提升大数据表拷贝效率的相关内容,分享出来供大家参考学习,我们大家在工作上会经常遇到量级比较大的数据表 ;
场景: 该数据表需要进行alter操作 比如增加一个字段,减少一个字段. 这个在一个几万级别数据量的数据表可以直接进行alter表操作,但是要在一个接近1000W的数据表进行操作,不是一件容易的事;
可能情况:
1.导致数据库崩溃或者卡死
2.导致其他进程 进行数据库读写I/O变慢
3.还有一个可能就是数据格式不一致 导致数据无法写入(比如一个varchar类型要改为int类型,当数据长度过大时会报错)
解决方案:--
1.重新创建一张数据表 create new_table select * from old_table 这种形式相当于复制一张新的数据表 ----(不建议): 这里面仅仅复制数据表的字段和数据 , 但是表结构 主键,索引和默认值都不会拷贝过来
2.分成两个步骤
1). create new_table like old_table 创建一个新表,表结构和old_table一致(包含主键,索引和默认值等)
2). insert into new_table select * from old_table 把old_table的数据全部拷贝到new_table里面去
----(如果数据量少的话,在几万行左右建议使用此方案, 如果数据量到达数百万 上千万时, 这个也是不适用的)
扩展: 如果你只要拷贝一部分数据表的话,可以指定 insert into new_table (字段1,字段2) select 字段1,字段2 from old_table [limit n,m] ;
3.
1).通过select from into outfile 命令来导出数据表数据
2).通过load data infile into 命令来导入数据表数据
不多废话 直接看图,感受下100万左右的数据量 方案2 和 方案3 处理速度相差多少
>select * from money_info into outfile '/var/lib/mysql-files/money.txt'; >create table money_info_cyq11 like money_info; >load data infile '/var/lib/mysql-files/money.txt' into table money_info_cyq11;
>create table money_info_cyq22 like money_info; >insert into money_info_cyq22 select * from money_info;
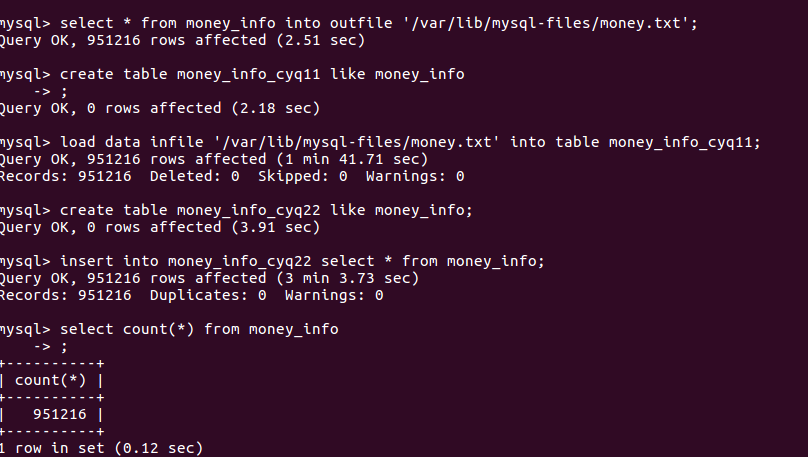

速度在4倍左右,网上说的20倍还没体验到[捂脸]
注:这里还存在一个问题

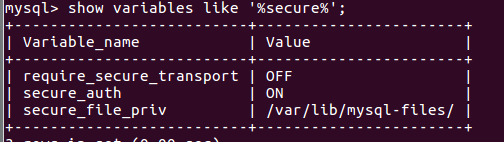
outfile的目录是有要求的
>show variables like '%secure%';
通过这条命令可以看到secure_file_priv 对应out_file的目录在哪个位置 , 指定这个位置导出即可;
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,如果有疑问大家可以留言交流,谢谢大家对的支持。
加载全部内容