python中的高阶函数 python高级特性和高阶函数及使用详解
shhnwangjian 人气:0python高级特性
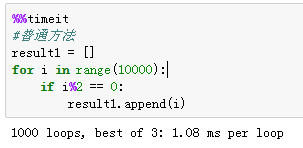
1、集合的推导式
•列表推导式,使用一句表达式构造一个新列表,可包含过滤、转换等操作。
语法:[exp for item in collection if codition]
if codition - 可选


•字典推导式,使用一句表达式构造一个新列表,可包含过滤、转换等操作。
语法:{key_exp:value_exp for item in collection if codition}

•集合推导式
语法:{exp for item in collection if codition}

•嵌套列表推导式

2、多函数模式
函数列表,python中一切皆对象。
# 处理字符串
str_lst = ['$1.123', ' $1123.454', '$899.12312']
def remove_space(str):
"""
remove space
"""
str_no_space = str.replace(' ', '')
return str_no_space
def remove_dollar(str):
"""
remove $
"""
if '$' in str:
return str.replace('$', '')
else:
return str
def clean_str_lst(str_lst, operations):
"""
clean string list
"""
result = []
for item in str_lst:
for op in operations:
item = op(item)
result.append(item)
return result
clean_operations = [remove_space, remove_dollar]
result = clean_str_lst(str_lst, clean_operations)
print result
执行结果:['1.123', '1123.454', '899.12312']
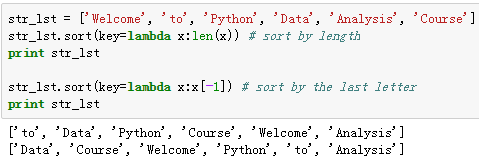
3、匿名函数lambda
•没有函数名
•单条语句组成
•语句执行的结果就是返回值
•可用作sort的key函数
python高阶函数
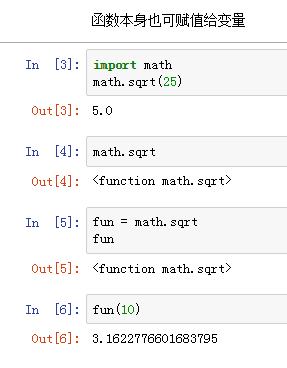
1、函数式编程
•函数本身可以赋值给变量,赋值后变量为函数;
•允许将函数本身作为参数传入另一个函数;
•允许返回一个函数。

2、map/reduce函数
•map(fun, lst),将传入的函数变量func作用到lst变量的每个元素中,并将结果组成新的列表返回


•reduce(func(x,y),lst),其中func必须有两个参数。每次func计算的结果继续和序列的下一个元素做累积计算。
lst = [a1, a2 ,a3, ......, an] reduce(func(x,y), lst) = func(func(func(a1, a2), a3), ......, an)

3、filter函数
•筛选序列
•filter(func, lst),将func作用于lst的每个元素,然后根据返回值是True或False判断是保留还是丢弃该元素。

下面看下Python高级函数使用
map的使用:map(function, iterable, ...)
map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
>>> def f(x): ... return x + x ... >>> r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9]) >>> list(r) [2, 4, 6, 8, 10, 12, 14, 16, 18] # 提供了两个列表,对相同位置的列表数据进行相加 >>> map(lambda x, y: x + y, [1, 3, 5, 7, 9], [2, 4, 6, 8, 10]) [3, 7, 11, 15, 19]
reduce的使用:reduce(function, iterable[, initializer])
reduce把一个函数作用在一个序列[x1, x2, x3, ...]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算。
>>> from functools import reduce >>> def add(x, y): ... return x + y ... >>> reduce(add, [1, 3, 5, 7, 9]) 25 >>> reduce(lambda x, y: x+y, [1,2,3,4,5]) # 使用 lambda 匿名函数 15 from functools import reduce def add(x,y): return x + y print (reduce(add, range(1, 101)))
filter的使用:filter(function, iterable)
filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
def is_odd(n): return n % 2 == 1 list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15])) # 结果: [1, 5, 9, 15] def not_empty(s): return s and s.strip() list(filter(not_empty, ['A', '', 'B', None, 'C', ' '])) # 结果: ['A', 'B', 'C']
filter()函数返回的是一个Iterator,也就是一个惰性序列,所以要强迫filter()完成计算结果,需要用list()函数获得所有结果并返回list。
sorted的使用:sorted(iterable[, cmp[, key[, reverse]]])
Python内置的sorted()函数就可以对list进行排序:
>>>a = [5,7,6,3,4,1,2] >>> b = sorted(a) # 保留原列表 >>> a [5, 7, 6, 3, 4, 1, 2] >>> b [1, 2, 3, 4, 5, 6, 7] 此外,sorted()函数也是一个高阶函数,它还可以接收一个key函数来实现自定义的排序,例如按绝对值大小排序: >>> sorted([36, 5, -12, 9, -21], key=abs) #key指定的函数将作用于list的每一个元素上,并根据key函数返回的结果进行排序。对比原始的list和经过key=abs处理过的list: #list = [36, 5, -12, 9, -21] #keys = [36, 5, 12, 9, 21] [5, 9, -12, -21, 36] #字符串排序 >>> sorted(['bob', 'about', 'Zoo', 'Credit']) ['Credit', 'Zoo', 'about', 'bob']
默认情况下,对字符串排序,是按照ASCII的大小比较的,由于'Z' < 'a',结果,大写字母Z会排在小写字母a的前面。
要进行反向排序,不必改动key函数,可以传入第三个参数reverse=True:
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True) ['Zoo', 'Credit', 'bob', 'about']
raw_input的使用:raw_input([prompt])
prompt: 可选,字符串,可作为一个提示语。
raw_input() 将所有输入作为字符串看待
>>>a = raw_input("input:")
input:123
>>> type(a)
<type 'str'> # 字符串
>>> a = raw_input("input:")
input:runoob
>>> type(a)
<type 'str'> # 字符串
>>>
input() 需要输入 python 表达式
>>>a = input("input:")
input:123 # 输入整数
>>> type(a)
<type 'int'> # 整型
>>> a = input("input:")
input:"runoob" # 正确,字符串表达式
>>> type(a)
<type 'str'> # 字符串
>>> a = input("input:")
input:runoob # 报错,不是表达式
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<string>", line 1, in <module>
NameError: name 'runoob' is not defined
<type 'str'>
总结
以上所述是小编给大家介绍的python高级特性和高阶函数及使用详解,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对网站的支持!
加载全部内容