PyCharm+PySpark远程调试的环境配置 PyCharm+PySpark远程调试的环境配置的方法
Mars_myCafe 人气:0前言:前两天准备用 Python 在 Spark 上处理量几十G的数据,熟料在利用PyCharm进行PySpark远程调试时掉入深坑,特写此博文以帮助同样深处坑中的bigdata&machine learning fans早日出坑。
Version :Spark 1.5.0、Python 2.7.14
1. 远程Spark集群环境
首先Spark集群要配置好且能正常启动,版本号可以在Spark对应版本的官方网站查到,注意:Spark 1.5.0作为一个比较古老的版本,不支持Python 3.6+;另外Spark集群的每个节点的Python版本必须保持一致。这里只讲如何加入pyspark远程调试所需要修改的部分。在$SPARK_HOME/conf/spark-env.sh中添加一行:
export PYSPARK_PYTHON=/home/hadoop/anaconda2/bin/python2
这里的Python路径是集群上Python版本的路径,我这里是用的anaconda安装的Python2,所以路路径如上。正常启动Spark集群后,在命令行输入pyspark后回车,能正确进入到pyspark shell。
2. 本地PyCharm配置
首先将Spark集群的spark-1.5.0部署包拷贝到本地机器,并在/etc/hosts(Linux类机器)或C:\Windows\System32….\hosts(Windows机器)中加入Spark集群Master节点的IP与主机名的映射;本地正确安装Spark集群同版本Python;
安装py4j
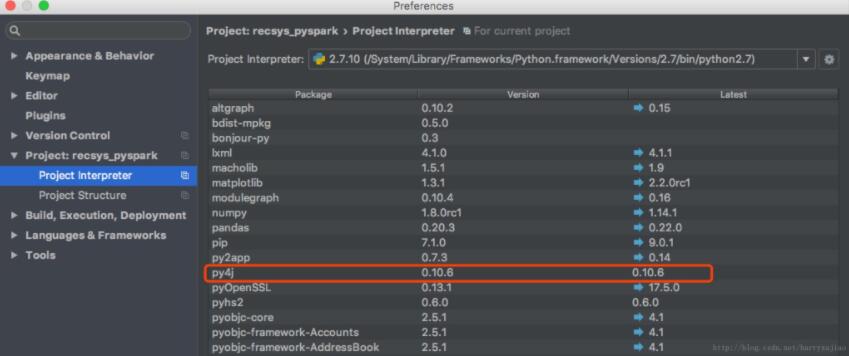
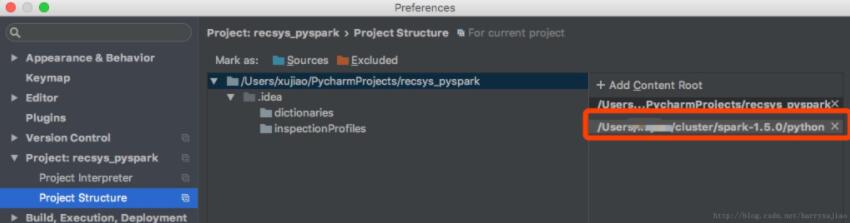
添加spark-1.5.0/python目录
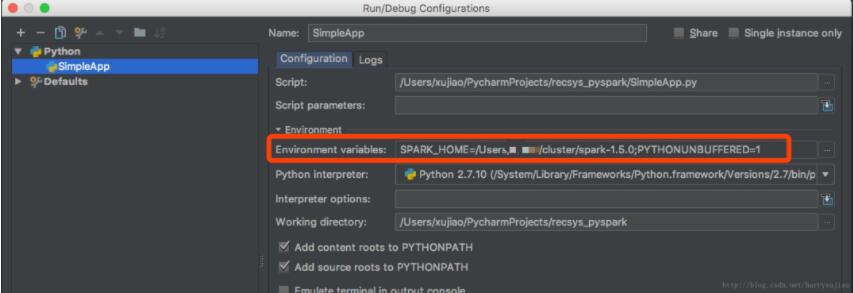
新建一个Python文件Simple,编辑Edit Configurations添加SPARK_HOME变量
写一个类似下面的简单测试程序
# -*- encoding: UTF-8 -*-
# @auther:Mars
# @datetime:2018-03-01
from pyspark import SparkContext
sc = SparkContext("spark://master:7077","Simple APP")
logData = sc.textFile("hdfs://master:9000/README.md").cache()
numAs = logData.filter(lambda s: 'a' in s).count()
numBs = logData.filter(lambda s: 'b' in s).count()
print("Lines with a: %i, lines with b: %i"%(numAs, numBs))
sc.stop()
运行可以得到看到下图,就OK了~
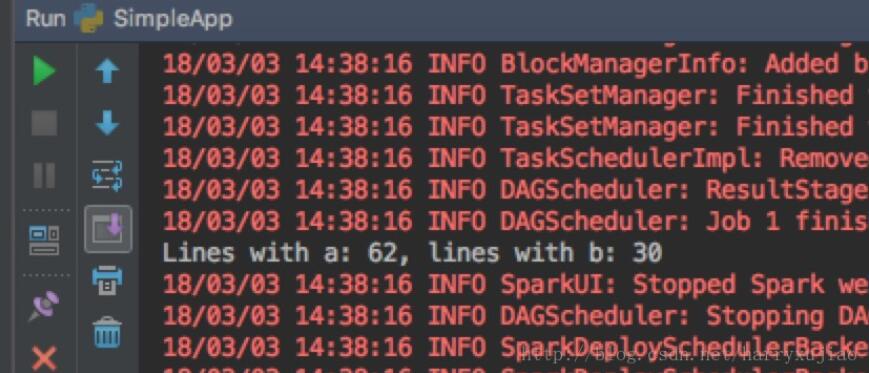
切记,1)本地与Spark集群的版本要一致;2)程序中不要用IP地址(不信可以试试,如果你用IP地址不报错,请告知我~谢谢)
以上这篇PyCharm+PySpark远程调试的环境配置的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
加载全部内容