python数据处理 根据颜色对图片进行分类 python数据处理 根据颜色对图片进行分类的方法
不论如何未来很美好 人气:0前面一篇文章有说过,利用scrapy来爬取图片,是为了对图片数据进行分类而收集数据。
本篇文章就是利用上次爬取的图片数据,根据图片的颜色特征来做一个简单的分类处理。
实现步骤如下:
1:图片路径添加
2:对比度处理
3:滤波处理
4:数据提取以及特征向量化
5:图片分类处理
6:根据处理结果将图片分类保存
代码量中等,还可以更少,只是我为了练习类的使用,而将每个步骤都封装成了一个独立的类,当然里面也有类继承的问题,遇到的问题前面一篇文章有讲解。内容可能有点繁琐,尤其是文件和路径的使用(可以自己修改),已经尽量优化代码了。
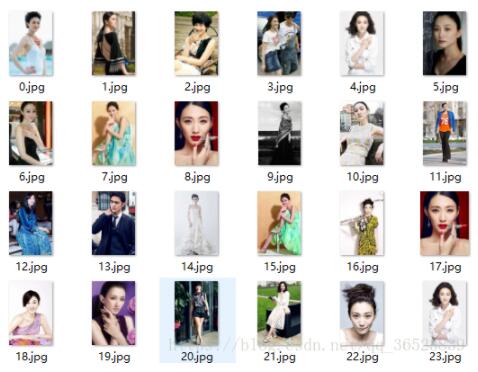
爬取的原始数据如下:
直接上代码:
import os
import numpy as np
import skimage
import matplotlib.pyplot as plt
from skimage import io #读取图片
from skimage import exposure #调用调对比度的方法 rescale_intensity、equalize_hist
from skimage.filters import gaussian #高斯
from skimage import img_as_float #图片unit8类型到float
from scipy.cluster.vq import kmeans,vq,whiten #聚类算法
import shutil #文件夹内容删除
class Path(object):
def __init__(self):
self.path = r"D:\PYscrapy\get_lixiaoran\picture"
self.pathlist = [] #原始图片列表
self.page = 0
def append(self): #将每张图片的路径加载到列表中
much = os.listdir(self.path)
for i in range(len(much)):
repath = os.path.join(self.path,str(self.page)+'.jpg')
self.page +=1
self.pathlist.append(repath)
return self.pathlist
class Contrast(object):
def __init__(self,pathlist):
self.pathlist = pathlist
self.contrastlist = [] #改变对比度之后的图片列表
self.path2 = r"D:\PYscrapy\get_lixiaoran\picture2"
self.page2 = 0
def balance(self): #将每张图片进行对比度的处理,两种方式 1:均衡化 2:从某个值开始取极值
if os.path.exists(self.path2) == False:
os.mkdir(self.path2)
# for lis in self.pathlist:
# data = skimage.io.imread(lis)
# equalized = exposure.equalize_hist(data) #方法一这里使用个人人为更好的均衡化处理对比度的方法
# self.contrastlist.append(equalized)
for lis in self.pathlist:
data = skimage.io.imread(lis)
high_contrast = exposure.rescale_intensity(data,in_range=(20,220)) #方法二 以20和220取两端极值
self.contrastlist.append(high_contrast)
for img in self.contrastlist:
repath = os.path.join(self.path2,str(self.page2)+'.jpg') #保存修改后的图片
skimage.io.imsave(repath,img)
self.page2 +=1
class Filter(Contrast):
def __init__(self,pathlist):
super().__init__(pathlist)
self.path31 = self.path2
self.path32 = r"D:\PYscrapy\get_lixiaoran\picture3"
self.page3 = 0
self.filterlist = []
def filte_r(self):
img = os.listdir(self.path31) #读取文件内容
if os.path.exists(self.path32) == False:
os.mkdir(self.path32)
for lis in range(len(img)): #循环做每张图片的高斯过滤
path = os.path.join(self.path31,str(lis)+r'.jpg')
img = skimage.io.imread(path)
gas = gaussian(img,sigma=3) #multichannel=False 去掉颜色2D
self.filterlist.append(gas)
path_gas = os.path.join(self.path32,str(self.page3)+r'.jpg')
skimage.io.imsave(path_gas,gas)
self.page3 +=1
return self.path32
class Vectoring(object):
def __init__(self,filter_path):
self.path41 = filter_path
self.diff = []
self.calculate = []
def vector(self):
numbers = os.listdir(self.path41) #获取文件夹内容
os.chdir(self.path41) #切换路径
for i in range(len(numbers)):
self.diff.append([])
for j in range(4):
self.diff[i].append([]) #diff[[number],[img_float],[bin_centers],[hist]]
for cnt,number in enumerate(numbers):
img_float = img_as_float(skimage.io.imread(number)) #将图像ndarry nint8->float
hist,bin_centers = exposure.histogram(img_float,nbins=10) #取图像的 每个区间的像素值 分隔区间
self.diff[cnt][0] = number
self.diff[cnt][1] = img_float
self.diff[cnt][2] = bin_centers #把数据添加到diff中
self.diff[cnt][3] = hist
for i,j in enumerate(self.diff): #使用hist和bin_centers相乘来降维,向量化
self.calculate.append([y*self.diff[i][3][x] for x,y in enumerate(self.diff[i][2])]) #这里可能需要理解一下,就是涉及的参数有点多
for i in range(len(self.diff)):
self.diff[i].append(self.calculate[i]) #将特征向量calculate也加入到diff中
return self.diff #diff[[number],[img_float],[bin_centers],[hist],[calculate]]
class Modeling(Vectoring):
def __init__(self,filter_path,K):
super().__init__(filter_path)
self.K = K
def model(self):
diff = self.vector()
calculate = []
for i in range(len(diff)):
calculate.append(diff[i][4])
spot = whiten(calculate) #这里使用scipy的k-means方法来对图片进行分类
center,_ = kmeans(spot,self.K) #如果对scipy的k-means不熟悉,前面有专门的讲解
cluster,_ = vq(spot,center)
return diff,cluster #获得预测值
class Predicting(object):
def __init__(self,predicted_diff,predicted_cluster,K):
self.diff = predicted_diff
self.cluster = predicted_cluster
self.path42 = r'D:\PYscrapy\get_lixiaoran\picture4'
self.K = K
def predicted(self):
if os.path.exists(self.path42) == True:
much = shutil.rmtree(self.path42)
os.mkdir(self.path42)
else:
os.mkdir(self.path42)
os.chdir(self.path42)
for i in range(self.K): #创建K个文件夹
os.mkdir('classify{}'.format(i))
for i,j in enumerate(self.cluster):
skimage.io.imsave('classify{}\\{}'.format(j,self.diff[i][0]),self.diff[i][1]) #根据图片的分类来将它们保存至对应的文件夹
if __name__=="__main__":
np.random.seed(10)
#文件路径添加
start = Path()
pathlist = start.append()
#对比度类
second = Contrast(pathlist)
second.balance() #get改变对比度后的图片个数
#高斯过滤
filte = Filter(pathlist)
filter_path = filte.filte_r()
#数据提取及向量化
vectoring = Vectoring(filter_path)
#K值的自定义
K = 3
#建模
modeling = Modeling(filter_path,K)
predicted_diff,predicted_cluster = modeling.model()
#预测
predicted = Predicting(predicted_diff,predicted_cluster,K)
predicted.predicted()
文件如下:

(K=3)分类如下(picrure4):

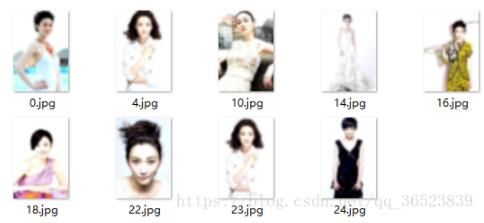
白色的基本在一类
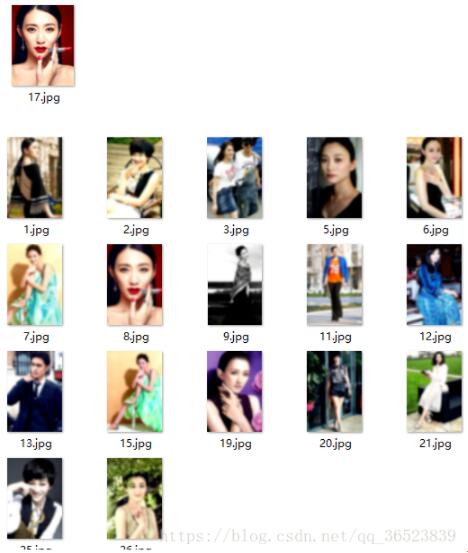
黑色的基本一类
分类出来的图片比较模糊是因为,我分类的是处理过后的图片,并非原图。
其实仔细看效果还是有的,就是确实不是太明显,图片的内容还是有点复杂的。大体的框架已经有了,只是优化的问题,调整优化,以及向量特征化的处理,就能得到更好的结果。或者使用一些更好的处理方式,我这里只是简单的使用了几种常见的图片处理方式,所以效果一般。
这里的类有点多,从上到下是类的顺序,所以一步步看还是不复杂的。如果有什么好的建议可以分享一下。
以上这篇python数据处理 根据颜色对图片进行分类的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
加载全部内容