python抓取挂号网医生数据 Python微医挂号网医生数据抓取
Python新世界 人气:01. 写在前面
今天要抓取的一个网站叫做微医网站,地址为 https://www.guahao.com ,我们将通过python3爬虫抓取这个网址,然后数据存储到CSV里面,为后面的一些分析类的教程做准备。本篇文章主要使用的库为pyppeteer 和 pyquery
首先找到 医生列表页
https://www.guahao.com/expert/all/全国/all/不限/p5
这个页面显示有 75952 条数据 ,实际测试中,翻页到第38页,数据就加载不出来了,目测后台程序猿没有把数据返回,不过为了学习,我们忍了。
2. 页面URL
https://www.guahao.com/expert/all/全国/all/不限/p1
https://www.guahao.com/expert/all/全国/all/不限/p2
...
https://www.guahao.com/expert/all/全国/all/不限/p38
数据总过38页,量不是很大,咱只需要随便选择一个库抓取就行,这篇博客,我找了一个冷门的库
pyppeteer 在使用过程中,发现资料好少,很尴尬。而且官方的文档写的也不好,有兴趣的可以自行去看看。关于这个库的安装也在下面的网址中。
https://miyakogi.github.io/pyppeteer/index.html
最简单的使用方法,在官方文档中也简单的写了一下,如下,可以把一个网页直接保存为一张图片。
import asyncio
from pyppeteer import launch
async def main():
browser = await launch() # 运行一个无头的浏览器
page = await browser.newPage() # 打开一个选项卡
await page.goto('http://www.baidu.com') # 加载一个页面
await page.screenshot({'path': 'baidu.png'}) # 把网页生成截图
await browser.close()
asyncio.get_event_loop().run_until_complete(main()) # 异步
我整理了下面的一些参考代码,你可以 做一些参考。
browser = await launch(headless=False) # 可以打开浏览器
await page.click('#login_user') # 点击一个按钮
await page.type('#login_user', 'admin') # 输入内容
await page.click('#password')
await page.type('#password', '123456')
await page.click('#login-submit')
await page.waitForNavigation()
# 设置浏览器窗口大小
await page.setViewport({
'width': 1350,
'height': 850
})
content = await page.content() # 获取网页内容
cookies = await page.cookies() # 获取网页cookies
3. 爬取页面
运行下面的代码,你就可以看到控制台不断的打印网页的源码,只要获取到源码,就可以进行后面的解析与保存数据了。如果出现控制不输出任何东西的情况,那么请把下面的
await launch(headless=True) 修改为 await launch(headless=False)
import asyncio
from pyppeteer import launch
class DoctorSpider(object):
async def main(self, num):
try:
browser = await launch(headless=True)
page = await browser.newPage()
print(f"正在爬取第 {num} 页面")
await page.goto("https://www.guahao.com/expert/all/全国/all/不限/p{}".format(num))
content = await page.content()
print(content)
except Exception as e:
print(e.args)
finally:
num += 1
await browser.close()
await self.main(num)
def run(self):
loop = asyncio.get_event_loop()
asyncio.get_event_loop().run_until_complete(self.main(1))
if __name__ == '__main__':
doctor = DoctorSpider()
doctor.run()
4. 解析数据
解析数据采用的是pyquery ,这个库在之前的博客中有过使用,直接应用到案例中即可。最终产生的数据通过pandas保存到CSV文件中。
import asyncio
from pyppeteer import launch
from pyquery import PyQuery as pq
import pandas as pd # 保存csv文件
class DoctorSpider(object):
def __init__(self):
self._data = list()
async def main(self,num):
try:
browser = await launch(headless=True)
page = await browser.newPage()
print(f"正在爬取第 {num} 页面")
await page.goto("https://www.guahao.com/expert/all/全国/all/不限/p{}".format(num))
content = await page.content()
self.parse_html(content)
print("正在存储数据....")
data = pd.DataFrame(self._data)
data.to_csv("微医数据.csv", encoding='utf_8_sig')
except Exception as e:
print(e.args)
finally:
num+=1
await browser.close()
await self.main(num)
def parse_html(self,content):
doc = pq(content)
items = doc(".g-doctor-item").items()
for item in items:
#doctor_name = item.find(".seo-anchor-text").text()
name_level = item.find(".g-doc-baseinfo>dl>dt").text() # 姓名和级别
department = item.find(".g-doc-baseinfo>dl>dd>p:eq(0)").text() # 科室
address = item.find(".g-doc-baseinfo>dl>dd>p:eq(1)").text() # 医院地址
star = item.find(".star-count em").text() # 评分
inquisition = item.find(".star-count i").text() # 问诊量
expert_team = item.find(".expert-team").text() # 专家团队
service_price_img = item.find(".service-name:eq(0)>.fee").text()
service_price_video = item.find(".service-name:eq(1)>.fee").text()
one_data = {
"name": name_level.split(" ")[0],
"level": name_level.split(" ")[1],
"department": department,
"address": address,
"star": star,
"inquisition": inquisition,
"expert_team": expert_team,
"service_price_img": service_price_img,
"service_price_video": service_price_video
}
self._data.append(one_data)
def run(self):
loop = asyncio.get_event_loop()
asyncio.get_event_loop().run_until_complete(self.main(1))
if __name__ == '__main__':
doctor = DoctorSpider()
doctor.run()
总结一下,这个库不怎么好用,可能之前没有细细的研究过,感觉一般,你可以在多尝试一下,看一下是否可以把整体的效率提高上去。
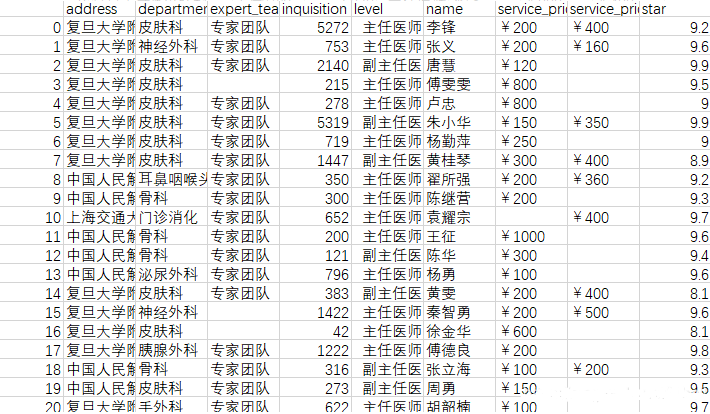
数据清单:
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对的支持。如果你想了解更多相关内容请查看下面相关链接
加载全部内容