pandas库pd.read_excel操作读取excel 详解pandas库pd.read_excel操作读取excel文件参数整理与实例
brucewong0516 人气:7除了使用xlrd库或者xlwt库进行对excel表格的操作读与写,而且pandas库同样支持excel的操作;且pandas操作更加简介方便。
首先是pd.read_excel的参数:函数为:
pd.read_excel(io, sheetname=0,header=0,skiprows=None,index_col=None,names=None,
arse_cols=None,date_parser=None,na_values=None,thousands=None,
convert_float=True,has_index_names=None,converters=None,dtype=None,
true_values=None,false_values=None,engine=None,squeeze=False,**kwds)
表格数据:
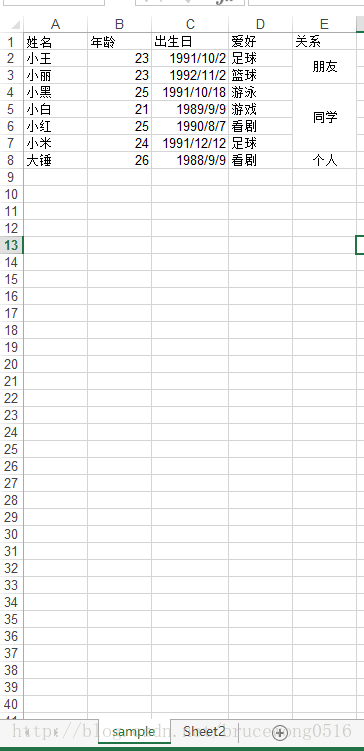

常用参数解析:
io :excel 路径;
In [10]: import pandas as pd #定义路径IO In [11]: IO = 'example.xls' #读取excel文件 In [12]: sheet = pd.read_excel(io=IO) #此处由于sheetname默认是0,所以返回第一个表 In [13]: sheet Out[13]: 姓名 年龄 出生日 爱好 关系 0 小王 23 1991-10-02 足球 朋友 1 小丽 23 1992-11-02 篮球 NaN 2 小黑 25 1991-10-18 游泳 同学 3 小白 21 1989-09-09 游戏 NaN 4 小红 25 1990-08-07 看剧 NaN 5 小米 24 1991-12-12 足球 NaN 6 大锤 26 1988-09-09 看剧 个人 #上述列表返回的结果和原表格存在合并单元格的差异
sheetname:默认是sheetname为0,返回多表使用sheetname=[0,1],若sheetname=None是返回全表 。注意:int/string返回的是dataframe,而none和list返回的是dict of dataframe。
In [7]: sheet = pd.read_excel('example.xls',sheetname= [0,1])
#参数为None时,返回全部的表格,是一个表格的字典;
#当参数为list = [0,1,2,3]此类时,返回的多表格同样是字典
In [8]: sheet
Out[8]:
{0: 姓名 年龄 出生日 爱好 关系
0 小王 23 1991-10-02 足球 朋友
1 小丽 23 1992-11-02 篮球 NaN
2 小黑 25 1991-10-18 游泳 同学
3 小白 21 1989-09-09 游戏 NaN
4 小红 25 1990-08-07 看剧 NaN
5 小米 24 1991-12-12 足球 NaN
6 大锤 26 1988-09-09 看剧 个人, 1: 1 3 5 学生
0 2 3 4 老师
1 4 1 9 教授}
#value是一个多位数组
In [15]: sheet[0].values
Out[15]:
array([['小王', 23, Timestamp('1991-10-02 00:00:00'), '足球', '朋友'],
['小丽', 23, Timestamp('1992-11-02 00:00:00'), '篮球', nan],
['小黑', 25, Timestamp('1991-10-18 00:00:00'), '游泳', '同学'],
['小白', 21, Timestamp('1989-09-09 00:00:00'), '游戏', nan],
['小红', 25, Timestamp('1990-08-07 00:00:00'), '看剧', nan],
['小米', 24, Timestamp('1991-12-12 00:00:00'), '足球', nan],
['大锤', 26, Timestamp('1988-09-09 00:00:00'), '看剧', '个人']], dtype=object)
#同样可以根据表头名称或者表的位置读取该表的数据
#通过表名
In [17]: sheet = pd.read_excel('example.xls',sheetname= 'Sheet2')
In [18]: sheet
Out[18]:
1 3 5 学生
0 2 3 4 老师
1 4 1 9 教授
#通过表的位置
In [19]: sheet = pd.read_excel('example.xls',sheetname= 1)
In [20]: sheet
Out[20]:
1 3 5 学生
0 2 3 4 老师
1 4 1 9 教授
header :指定作为列名的行,默认0,即取第一行,数据为列名行以下的数据;若数据不含列名,则设定 header = None;
#数据不含作为列名的行
In [21]: sheet = pd.read_excel('example.xls',sheetname= 1,header = None)
In [22]: sheet
Out[22]:
0 1 2 3
0 1 3 5 学生
1 2 3 4 老师
2 4 1 9 教授
#默认第一行数据作为列名
In [23]: sheet = pd.read_excel('example.xls',sheetname= 1,header =0)
In [24]: sheet
Out[24]:
1 3 5 学生
0 2 3 4 老师
1 4 1 9 教授
skiprows:省略指定行数的数据
In [25]: sheet = pd.read_excel('example.xls',sheetname= 1,header = None,skiprows= 1)
#略去1行的数据,自上而下的开始略去数据的行
In [26]: sheet
Out[26]:
0 1 2 3
0 2 3 4 老师
1 4 1 9 教授
skip_footer:省略从尾部数的行数据
In [27]: sheet = pd.read_excel('example.xls',sheetname= 1,header = None,skip_footer= 1)
#从尾部开始略去行的数据
In [28]: sheet
Out[28]:
0 1 2 3
0 1 3 5 学生
1 2 3 4 老师
index_col :指定列为索引列,也可以使用 u'string'
#指定第二列的数据作为行索引
In [30]: sheet = pd.read_excel('example.xls',sheetname= 1,header = None,skip_footer= 1,index_col=1)
In [31]: sheet
Out[31]:
0 2 3
1
3 1 5 学生
3 2 4 老师
names:指定列的名字,传入一个list数据
In [32]: sheet = pd.read_excel('example.xls',sheetname= 1,header = None,skip_footer= 1,index_col=1,names=['a','b','c'])
...:
In [33]: sheet
Out[33]:
a b c
1
3 1 5 学生
3 2 4 老师
总体而言,pandas库的pd.read_excel和pd.read_csv的参数比较类似,且相较之前的xlrd库的读表操作更加简单,针对一般批量的数据处理最好选择pandas库操作。但是功能有待完善或者本次研究的不够深入,比如合并单元格的问题,欢迎一起讨论交流。
加载全部内容