Python 图文识别OCR 初探利用Python进行图文识别(OCR)
Max老白Gān丶 人气:0话说什么是OCR?????
简介
OCR技术是光学字符识别的缩写(Optical Character Recognition),是通过扫描等光学输入方式将各种票据、报刊、书籍、文稿及其它印刷品的文字转化为图像信息,再利用文字识别技术将图像信息转化为可以使用的计算机输入技术。可应用于银行票据、大量文字资料、档案卷宗、文案的录入和处理领域。适合于银行、税务等行业大量票据表格的自动扫描识别及长期存储。相对一般文本,通常以最终识别率、识别速度、版面理解正确率及版面还原满意度4个方面作为OCR技术的评测依据;而相对于表格及票据,通常以识别率或整张通过率及识别速度为测定OCR技术的实用标准。
解析
采用OCR识别技术,可以将其应用于银行票据光盘缩微系统,可以自动提取票据要素,可减轻操作员的工作量,减少重复劳动,尤其是在与银行事后且监督系统相结合后,可以替代原先的操作人员完成事后监督工作。由计算机自动识别票据上的日期、帐号、金额等要素,通过银行事后监督系统与业务系统中的数据进行比较,完成传统的事后监督操作;配有印章验证系统后,自动将凭证图像中的印章与系统中预留的印鉴进行比较,完成印章的真伪识别。
OCR识别技术不仅具有可以自动判断、拆分、识别和还原各种通用型印刷体表格,在表格理解上做出了令人满意的实用结果,能够自动分析文稿的版面布局,自动分栏、并判断出标题、横栏、图像、表格等相应属性,并判定识别顺序,能将识别结果还原成与扫描文稿的版面布局一致的新文本。表格自动录入技术,可自动识别特定表格的印刷或打印汉字、字母、数字,可识别手写体汉字、手写体字母、数字及多种手写符号,并按表格格式输出。提高了表格录入效率,可节省大量人力。同时支持将表格识别直接还原成PTF、PDF、HTML等格式文档;并可以对图像嵌入横排文本和竖排文本、表格文本进行自动排版面分析。 利用目前的高新技术-OCR,直接从凭证影像中提取金额、帐号等重要数据,代替人的手工录入,与条码识别/流水识别紧密结合,实现建立事后副本帐、完成事后监督的工作。OCR处理一般使用性能较好的PC机,OCR处理程序一经启动会自动扫描数据库中的凭证影像,发现有需OCR处理而未处理的,提取到本地进行处理。
OCR手写体、印刷体识别技术,能识别不同人写的千差万别的手写体汉字和数字,应用于本系统,识别凭证影像中储户填写的信息,如大写金额、小写金额、帐号、存期、日期、证件号等,可以代替手工录入。同时被识别得出的金额还要与流水识别所得的金额进行核对,核对成功,则OCR识别成功。这样处理是为了避免误判。
经过对银行产生的实际凭证进行的大量测试,在实际开发过程中,根据银行的实际需求,OCR技术在票据和表格识别能力和手写体自动识别能力上不断提升,目前处理速度可达到每分钟60~80张票据,存折识别率已经达到了85%以上,存单、凭条识别率达到90%以上,而85%以上的识别率就能减少80%以上的数据录入员。
在档案领域OCR技术使档案扫描成果达到了全文可识别,将档案数字化发展提升了到了一个新的阶段,是原本扫描出来的图片变得更容易进行检索,为数字档案馆的数据查询提供了技术支持,是档案数字化发展中必不可少的一环。
以上来自百度百科哈哈哈哈哈!!
相关的工具:Tesseract
Tesseract概述:
Tesseract 是一个OCR库,目前由Google赞助(Google也是一家以OCR和机器学习技术闻名于世的公司)。Tesseract是目前公认最优秀、最精确的开源OCR系统。
Tesseract的Windows安装包下载地址为:http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe,下载后双击直接安装即可。安装完后,需要将Tesseract添加到系统变量中。在CMD中输入tesseract-v,如显示以下界面,则表示Tesseract安装完成且添加到系统变量中。
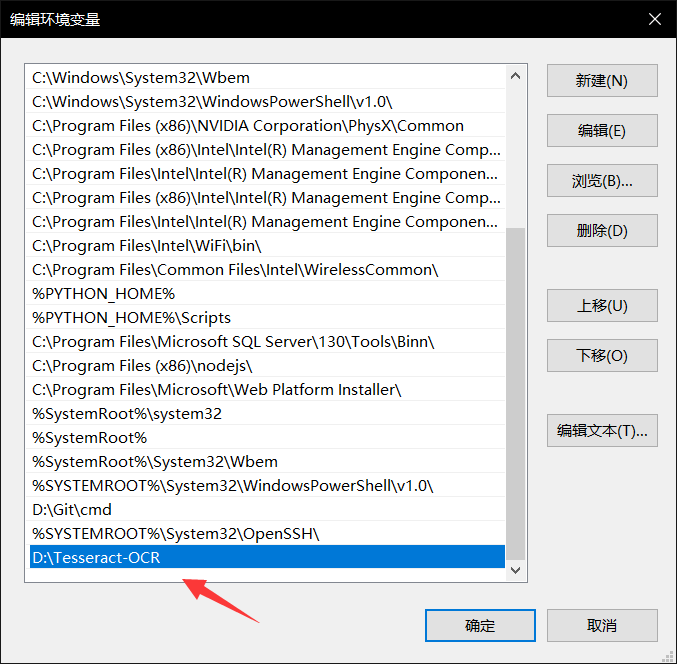
配置完成后在命令行输入tesseract -v,如果出现如下图所示,说明环境变量配置成功
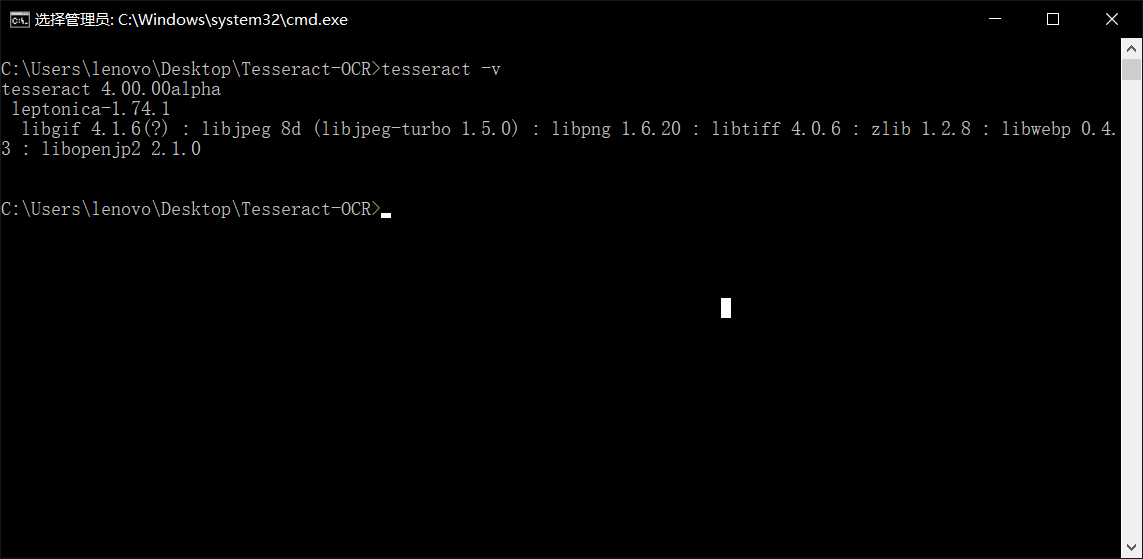
命令使用: tesseract C://Users\lenovo\Desktop\Tesseract-OCR\233.jpg C://Users\lenovo\Desktop\Tesseract-OCR\Max.txt,则会将233.jpg中的识别文字写入到Max.txt一执行报错???什么情况?
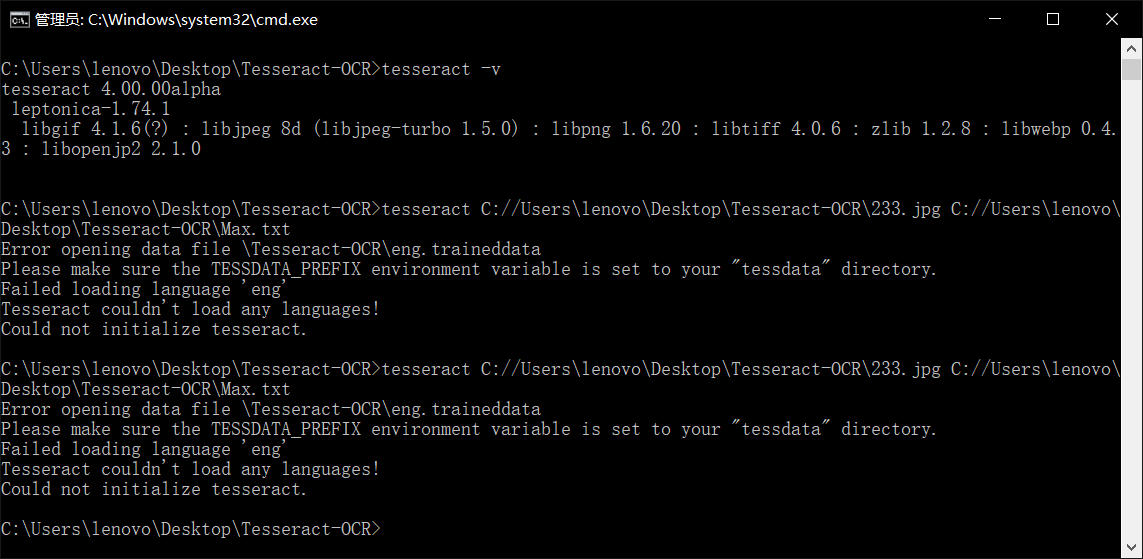
后来我找了一些资料来看 上面的意思就是说不能加载'eng'语言包。请将tessdata的父文件夹路径设置为TESSDATA_PREFIX环境变量值,这个就是说在环境变量中新建一个系统变量,变量名称为TESSDATA_PREFIX,tessdata是放置语言包的文件夹,一般在你安装tesseract的目录下,即tesseract的安装目录就是tessdata的父目录,把ESSDATA_PREFIX的值设置为它就没问题了
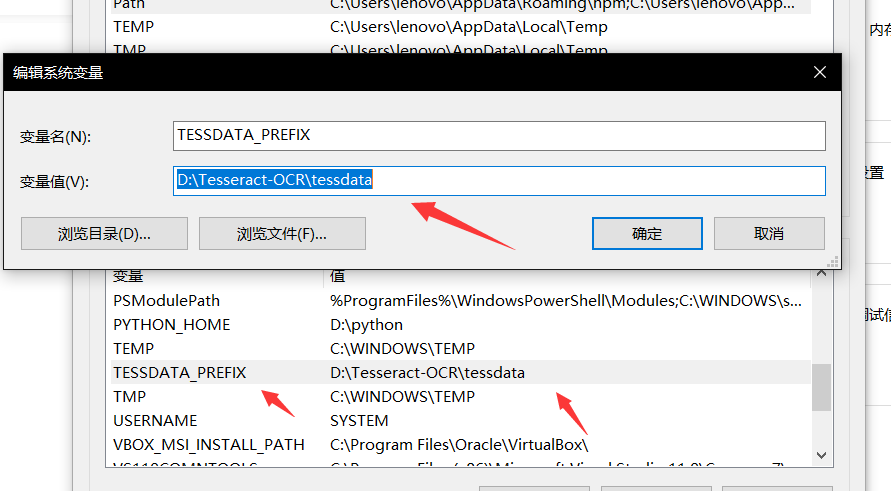
更改完成后重启就没问题了。
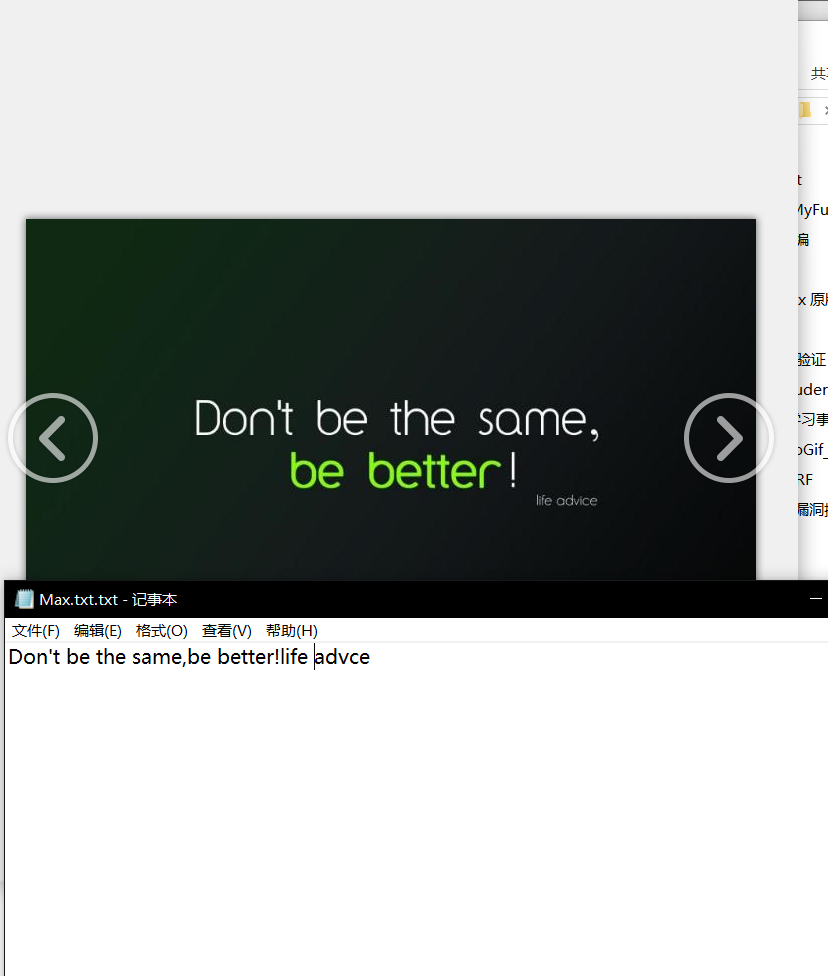
规整的中文也是可以识别的哦。
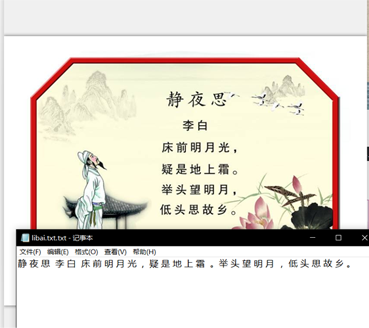
命令:tesseract C://Users\lenovo\Desktop\Tesseract-OCR\libai.png C://Users\lenovo\Desktop\Tesseract-OCR\libai.txt -l chi_sim
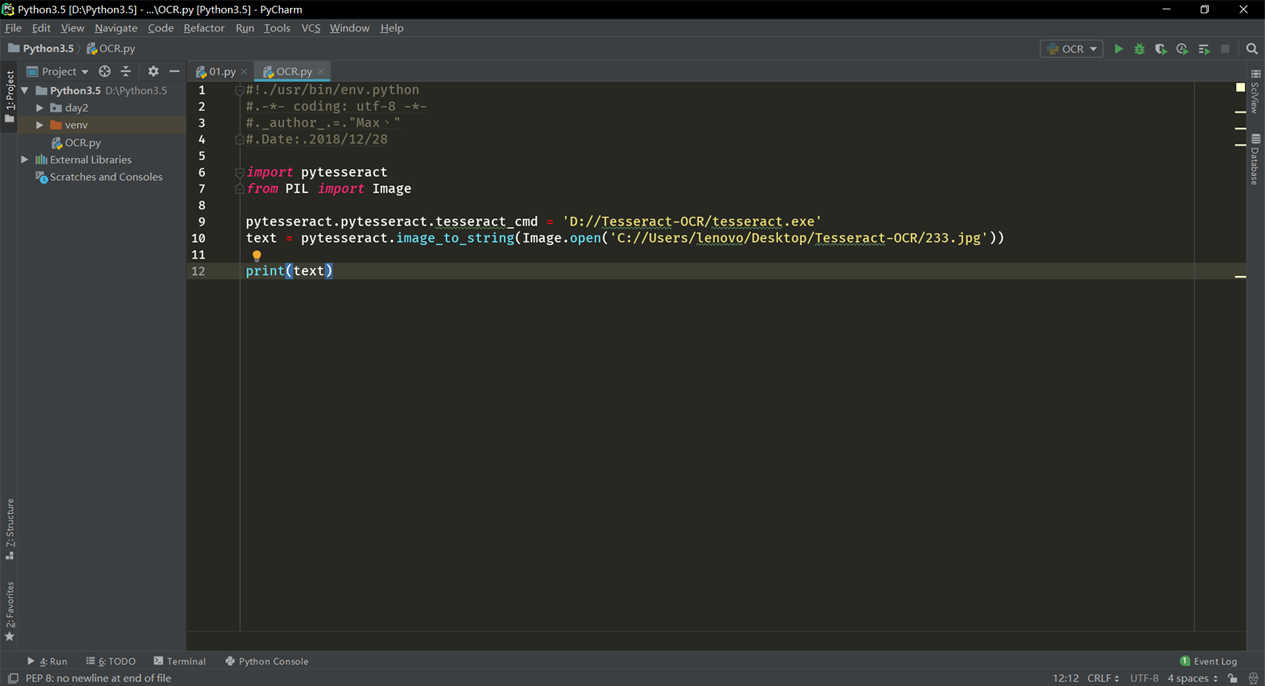
我们开始使用python编写识别小脚本了,这里我们需要一个pytesseract库使用pip install pytesseract安装。安装完后,就可以使用Python调用Tesseract这里我们还需要安装一个Python的图片处理模块,可以安装pillow.
输入以下代码,可以实现同上述Tesseract命令一样的效果:
我们的图片里面内容是:
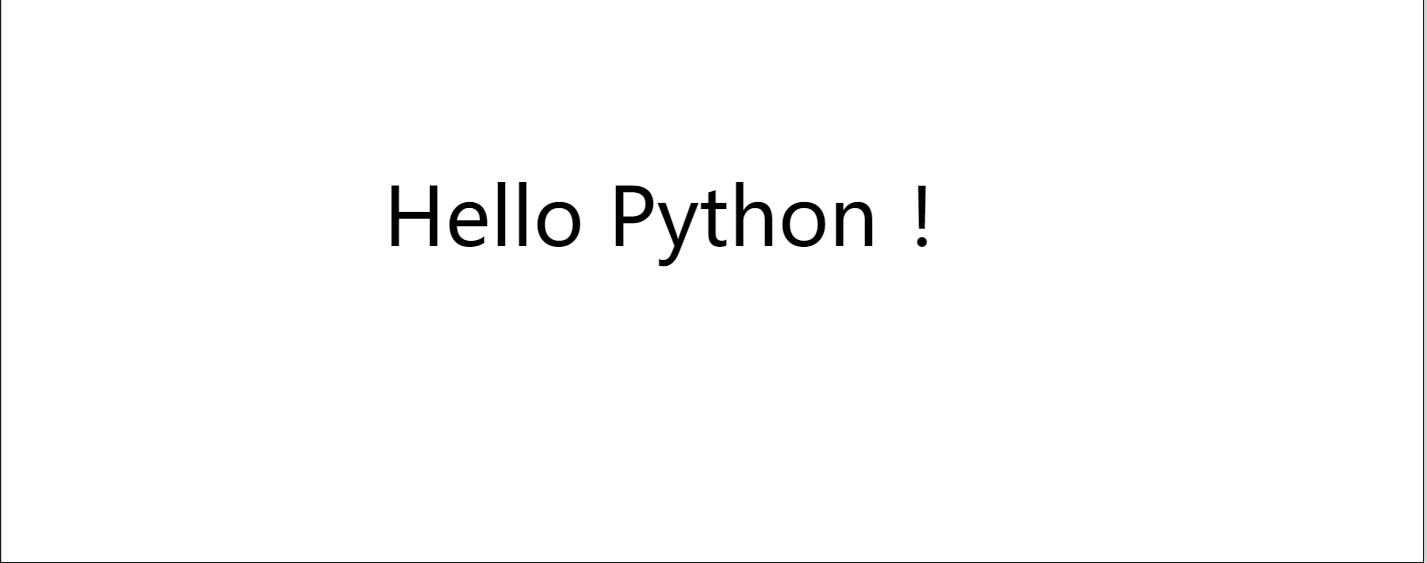
运行程序:
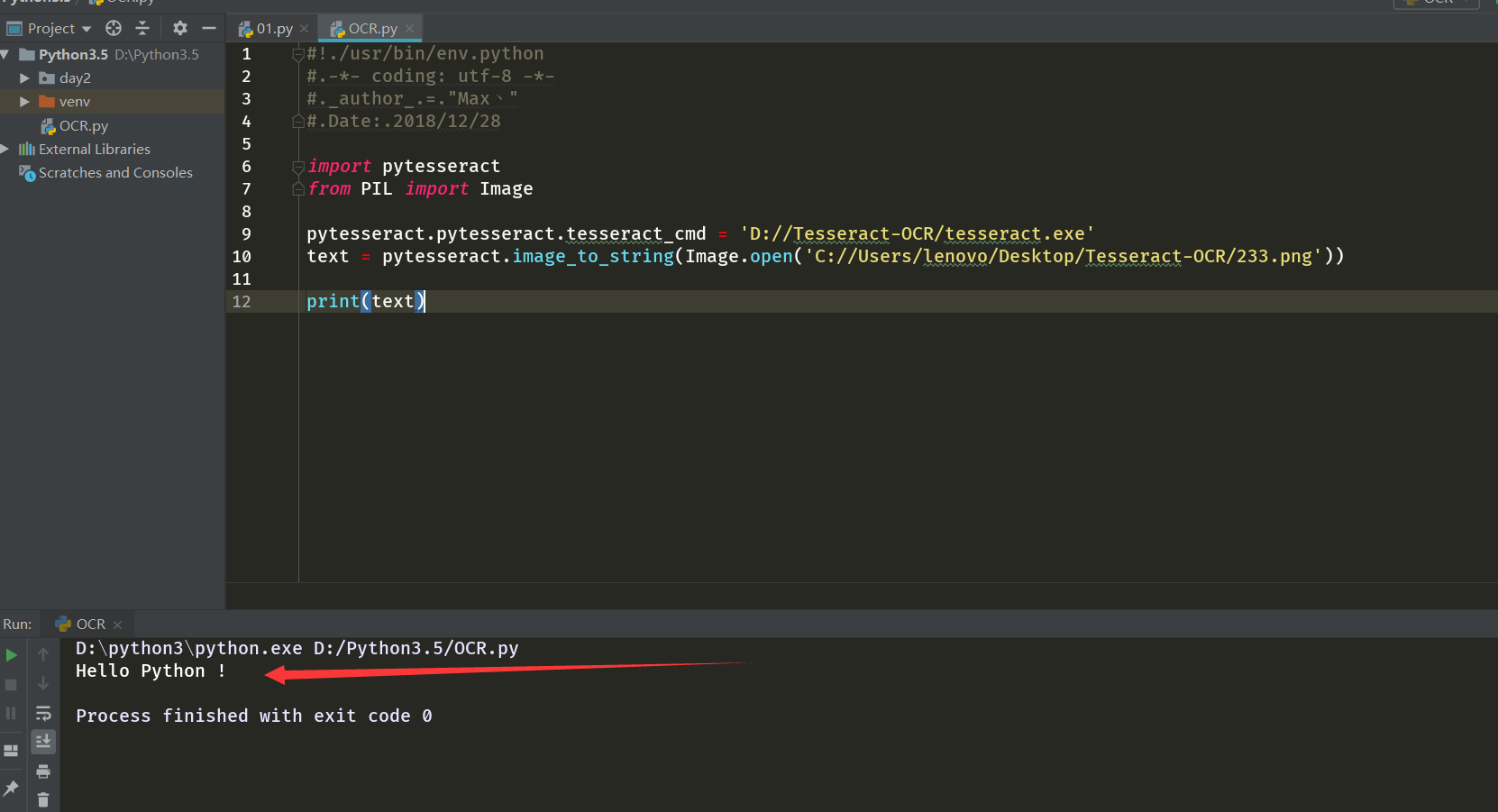
识别!!
加载全部内容