Python批处理文件夹txt文件 浅谈Python批处理文件夹中的txt文件
edj_13 人气:01 文件处理形式
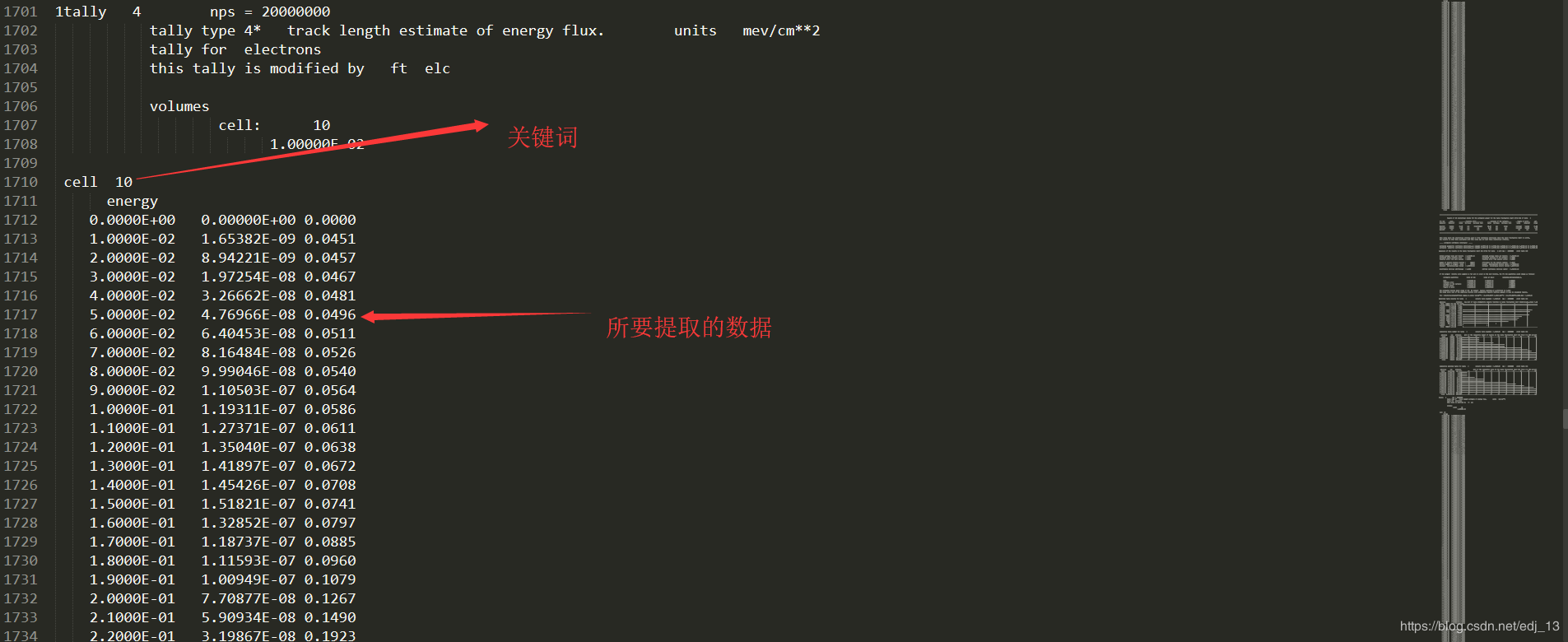
近期由于处理大量数据,所以对于采用python进行处理文件的一些操作也打算整理一下;接下来主要说一下如何处理目录下的一系列txt文件。首先看一下我们将要处理目录下的15个类似的数据文件,其中提取的数据如图所示,以及在读写文件时所需要的关键词,可以让程序正确读写相应的数据

2.代码段-python
接下来就是贴出相应的python代码,具体一些关键的注释我已经标注好了,具体数据结果就不展示了,如果大家想拿我的数据进行测试联系我就好,但是一般情况下在我标注的地方进行相应的修改就好,希望有啥不懂得大家可以一起交流。
import os
import numpy as np
def eachFile(filepath):
j=0
pathDir = os.listdir(filepath) #获取当前路径下的文件名,返回list
for s in pathDir:
newDir=os.path.join(filepath,s) #将文件名写入到当前文件路径后面
if os.path.isfile(newDir): #如果是文件
if os.path.splitext(newDir)[1]==".txt": #判断是否是txt
readFile(newDir)
j=j+1
print(j)
pass
else:
break
def readFile(filepath):
index=0 #控制数据存入不同的list
with open(filepath,"r") as f:
line=f.readline()
# print(line)
while line:
if line[:9]==' cell 10': #根据关键词抽取数据
f.readline()
index=index+1
for i in range(126): #抽取的数据格式
energy,f4,error=f.readline().split()
if(index==1):
list_total.append(f4)
elif(index==2):
list_electron.append(f4)
else:
list_positron.append(f4)
line=f.readline()
def main():
global list_total,list_electron,list_positron #定义全局变量,可以将所有数据都存入list中
fp=r'F:\\MCwork\\MCCM\\scripts\\filesworks' #存放数据的目录
os.chdir(fp)
eachFile(fp)
output =open("flux.txt",'w') #将list存入相应的文件中,便于后期处理数据
listdata_total=list(np.reshape(list_total,(15,126)).T) #改变数组维度,存储
for i in range(126): #数据读入相应文件的第一种方法,第一篇博客有介绍
for j in range(15):
output.write(listdata_total[i][j]+' ')
output.write('\t')
output.write('\n')
output.close()
if __name__ == '__main__':
list_electron=[]
list_total=[]
list_positron=[]
main()
以上所述是小编给大家介绍的Python批处理文件夹中的txt文件详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对网站的支持!
加载全部内容