mongodb基本特性与内部构造 MongoDB的基本特性与内部构造的讲解
CODETC 人气:0MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
对于大多数的MongoDB的用户来说,MongoDB就像是一个大黑盒。但是如果你能够了解到MongoDB一些内部构造的话,将有利于你更好地理解和使用MongoDB。
BSON
在MongoDB中,文档是对数据的抽象,它被使用在Client端和Server端的交互中。所有的Client端(各种语言的Driver)都会使用这种抽象,它的表现形式就是我们常说的BSON(Binary JSON)。
BSON 是一个轻量级的二进制数据格式。MongoDB能够使用BSON,并将BSON作为数据的存储存放在磁盘中。
当Client端要将写入文档,使用查询等操作时,需要将文档编码为BSON格式,然后再发送给Server端。同样,Server端的返回结果也是编码为BSON格式再返回给Client端的。
使用BSON格式出于以下3种目的:
效率。BSON是为效率而设计的,它只需要使用很少的空间。即使在最坏的情况下,BSON格式也比JSON格式在最好的情况下存储效率高。
传输性。在某些情况下,BSON会牺牲额外的空间让数据的传输更加方便。比如,字符串的传输的前缀会标识字符串的长度,而不是在字符串的末尾打上结束的标记。这样的传输形式有利于MongoDB修改传输的数据。
性能。最后,BSON格式的编码和解码都是非常快速的。它使用了C风格的数据表现形式,这样在各种语言中都可以高效地使用。
写入协议
Client端访问Server端使用了轻量级的TCP/IP写入协议。这种协议在MongoDB Wiki中有详细介绍,它其实是在BSON数据上面做了一层简单的包装。比如说,写入数据的命令中包含了1个20字节的消息头(由消息的长度和写入命令标识组成),需要写入的Collection名称和需要写入的数据。
数据文件
在MongoDB的数据文件夹中(默认路径是/data/db)由构成数据库的所有文件。每一个数据库都包含一个.ns文件和一些数据文件,其中数据文件会随着数据量的增加而变多。所以如果有一个数据库名字叫做foo,那么构成foo这个数据库的文件就会由foo.ns,foo.0,foo.1,foo.2等等组成。
数据文件每新增一次,大小都会是上一个数据文件的2倍,每个数据文件最大2G。这样的设计有利于防止数据量较小的数据库浪费过多的空间,同时又能保证数据量较大的数据库有相应的空间使用。
MongoDB会使用预分配方式来保证写入性能的稳定(这种方式可以使用–noprealloc关闭)。预分配在后台进行,并且每个预分配的文件都用0进行填充。这会让MongoDB始终保持额外的空间和空余的数据文件,从而避免了数据增长过快而带来的分配磁盘空间引起的阻塞。
名字空间和盘区
每一个数据库都由多个名字空间组成,每一个名字空间存储了相应类型的数据。数据库中的每一个Collection都有各自对应的名字空间,索引文件同样也有名字空间。所有名字空间的元数据都存储在.ns文件中。
名字空间中的数据在磁盘中分为多个区间,这个叫做盘区。在下图中,foo这个数据库包含3个数据文件,第三个数据文件属于空的预分配文件。头两个数据文件被分为了相应的盘区对应不同的名字空间。
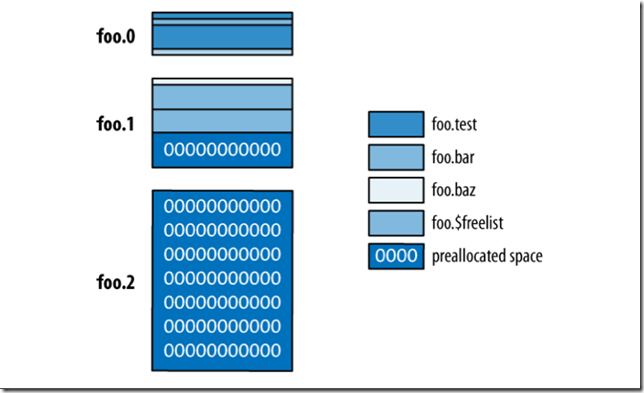
上图显示了名字空间和盘区的相关特点。每一个名字空间可以包含多个不同的盘区,这些盘区并不是连续的。与数据文件的增长相同,每一个名字空间对应的盘区大小的也是随着分配的次数不断增长的。这样做的目的是为了平衡名字空间浪费的空间与保持某一个名字空间中数据的连续性。上图中还有一个需要注意的名字空间:$freelist,这个名字空间用于记录不再使用的盘区(被删除的Collection或索引)。每当名字空间需要分配新的盘区的时候,都会先查看$freelist是否有大小合适的盘区可以使用。
内存映射存储引擎
MongoDB目前支持的存储引擎为内存映射引擎。当MongoDB启动的时候,会将所有的数据文件映射到内存中,然后操作系统会托管所有的磁盘操作。这种存储引擎有以下几种特点:
- MongoDB中关于内存管理的代码非常精简,毕竟相关的工作已经有操作系统进行托管。
- MongoDB服务器使用的虚拟内存将非常巨大,并将超过整个数据文件的大小。不用担心,操作系统会去处理这一切。要注意的是,MongoDB自己是不管理内存的,无法指定内存大小,完全交给操作系统来管理,因此有时候是不可控的,在生产环境使用必须在OS层面监控内存使用情况。
- MongoDB无法控制数据写入磁盘的顺序,这样将导致MongoDB无法实现writeahead日志的特性。所以,如果MongoDB希望提供一种durability的特性,需要实现另外一种存储引擎。
- 32位系统的MongoDB服务器每一个Mongod实例只能使用2G的数据文件。这是由于地址指针只能支持32位。
特性
它的特点是高性能、易部署、易使用,存储数据非常方便。主要功能特性有:
- 面向集合存储,易存储对象类型的数据。
- 模式自由。
- 支持动态查询。
- 支持完全索引,包含内部对象。
- 支持查询。
- 支持复制和故障恢复。
- 使用高效的二进制数据存储,包括大型对象(如视频等)。
- 自动处理碎片,以支持云计算层次的扩展性
- 支持RUBY,PYTHON,JAVA,C++,PHP等多种语言。
- 文件存储格式为BSON(一种JSON的扩展)
- 可通过网络访问
所谓“面向集合”(Collenction-Orented),意思是数据被分组存储在数据集中,被称为一个集合(Collenction)。每个 集合在数据库中都有一个唯一的标识名,并且可以包含无限数目的文档。集合的概念类似关系型数据库(RDBMS)里的表(table),不同的是它不需要定 义任何模式(schema)。
模式自由(schema-free),意味着对于存储在mongodb数据库中的文件,我们不需要知道它的任何结构定义。如果需要的话,你完全可以把不同结构的文件存储在同一个数据库里。
存储在集合中的文档,被存储为键-值对的形式。键用于唯一标识一个文档,为字符串类型,而值则可以是各中复杂的文件类型。我们称这种存储形式为BSON(Binary Serialized dOcument Format)。
其它
在《MongoDB The Definitive Guide》中介绍的MongoDB内部构造只有这么多,如果真要把它说清楚,可能需要另外一本书来专门讲述了。比如内部的JS解析,查询的优化,索引的建立等等。
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对的支持。如果你想了解更多相关内容请查看下面相关链接
加载全部内容