python实现维吉尼亚算法 python实现维吉尼亚算法
qq_43262611 人气:01 Virginia加密算法、解密算法
Vigenenre密码是最著名的多表代换密码,是法国著名密码学家Vigenenre发明的。Vigenenre密码使用一个词组作为密钥,密钥中每一个字母用来确定一个代换表,每一个密钥字母被用来加密一个明文字母,第一个密钥字母加密第一个明文字母,第二个密钥字母加密第二个明文字母,等所有密钥字母使用完后,密钥再次循环使用,于是加解密前需先将明密文按照密钥长度进行分组。
密码算法可表示如下:。
设明文串为:
M=m1m2…mn,mi∈charset, n是明文长度
秘钥为:
K=k1k2…kd,ki∈charset, d是秘钥长度
密文为:
C=c1c2…cn,ci∈charset, n是密文长度
加密算法:
cj+td=(mj+td+kj ) mod 26
j=1…d, t=0…ceiling(n/d)-1
其中ceiling(x)函数表示不小于x最小整数
解密算法:
mj+td=(cj+td -kj ) mod 26
j=1…d, t=0…ceiling(n/d)-1
其中ceiling(x)函数表示不小于x最小整数
加解密代码如下
def VigenereEncrypto(message, key):
msLen = len(message)
keyLen = len(key)
message = message.upper()
key = key.upper()
raw = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"# 明文空间
# 定义加密后的字符串
ciphertext = ""
# 开始加密
for i in range(0, msLen):
# 轮询key的字符
j = i % keyLen
# 判断字符是否为英文字符,不是则直接向后面追加且继续
if message[i] not in raw:
ciphertext += message[i]
continue
encodechr = chr((ord(message[i]) - ord("A") + ord(key[j]) - ord("A")) % 26 + ord("A"))
# 追加字符
ciphertext += encodechr
# 返回加密后的字符串
return ciphertext
if __name__ == "__main__":
message = "Hello, World!"
key = "key"
text = VigenereEncrypto(message, key)
print(text)
def VigenereDecrypto(ciphertext, key):
msLen = len(ciphertext)
keyLen = len(key)
key = key.upper()
raw = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"# 密文空间
plaintext = ""
for i in range(0, msLen):# 开始解密
# 轮询key的字符
j = i % keyLen
# 判断字符是否为英文字符,不是则直接向后面追加且继续
if ciphertext[i] not in raw:
plaintext += ciphertext[i]
continue
decodechr = chr((ord(ciphertext[i]) - ord("A") - ord(key[j]) - ord("A")) % 26 + ord("A"))
# 追加字符
plaintext += decodechr
# 返回加密后的字符串
return plaintext
if __name__=="__main__":
ciphertext = "RIJVS, AMBPB!"
key = "key"
text = VigenereDecrypto(ciphertext, key)
print(text)
import VigenereDecrypto
import VigenereEncrypto
def main():
info = '''==========********=========='''# 开始加密
print(info, "\n------维吉尼亚加密算法------")
print(info)
# 读取测试文本文档
message = open("test.txt","r+").read()
print("读取测试文本文档:test.txt")
print("开始加密!")
# 输入key
key = input("请输入密钥:")
# 进入加密算法
CipherText = VigenereEncrypto.VigenereEncrypto(message, key)
# 写入密文文本文档
C = open("CipherText.txt", "w+")
C.write(CipherText)
C.close()
print("加密后得到的密文是: \n" + CipherText)
# 开始解密
print(info, "\n------维吉尼亚解密算法------")
print(info)
# 读取加密文本文档
print("读取密文文本文档:CipherText.txt")
Ciphertext = open("CipherText.txt", "r+").read()
# 进入解密算法
print("开始解密!")
Plaintext = VigenereDecrypto.VigenereDecrypto(Ciphertext, key)
P = open("PlainText.txt", "w+")
# 写入解密文本文档
P.write(Plaintext)
P.close()
print("解密后得到的明文是 : \n" + Plaintext)
if __name__=="__main__":
main()
2重合指数法
2.1重合指数
设x=X1X2...Xn是一个含有n个字符的字符串,x的重合指数记为Ic(x),定义为x中两个随机元素相同的概率。
设y是一个长度为n密文,即y=y1y2...ym,其中y是密文字母,同样来求从中抽到两个相同字母的概率是多少。为此,设NA为字母A在这份密文中的频数,设Nb为字母B在这份密文中的频数,依此类推
从n个密文字母中抽取两个字母的方式有𝐶_𝑛^2=n(n-1)/2,而其中NA个A组成一对A的方式有CNA2= NA(NA-1)/2,于是从y中抽到两个字母都为A的概率为[NA(NA -1)]/[n(n-1)],..因此,从y中抽到两个相同字母的概率为 (∑▒〖𝑁𝑖(𝑁𝑖−1)〗)/(𝑛(𝑛−1))
这个数据称为这份密文的重合指数,记为IC(Y)
2.2重合指数法原理
26个英文字母出现频率表 重合指数公式
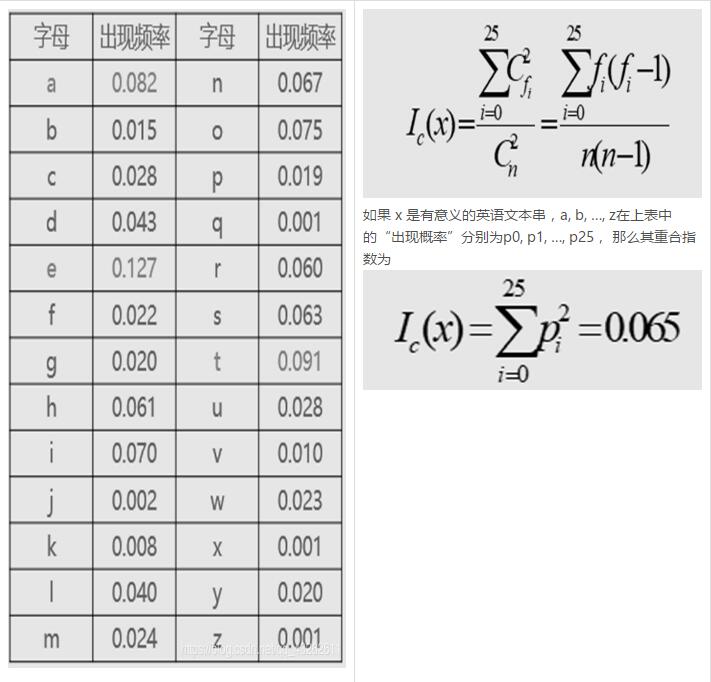
(1)根据频率表,我们可以计算出英语文本的重合指数为0.065。
(2)利用重合指数推测密钥长度的原理在于,对于一个由凯撒密码加密的序列,由于所有字母的位移程度相同,所以密文的重合指数应等于原文语言的重合指数。
(3)假设y=y1 y2...yn是由 Vigenere 密码得到的长度为n的密文。将y按列排成一个m*(n/ m)的矩形阵列,各行分别记为y1,y2...ym.如果m确实是密钥字的长度,则yi中的各个密文字母都是由同一个密钥的移位加密方式得到的。矩阵的每一行对应于子串yi,1≤i≤m。
(4)另一方面,如果m不是密钥字的长度,则 yi中的各个密文字母将是由不同密钥以移位加密方式得到的, yi 中的各个密文字母看起来更随机一些。对于一个随机的英文字母串,其重合指数为0.038。
(5)因为0.065和0.038相差较远,所以我们一般能够确定密钥字的长度,或者说我们能够确定由 Kasiski 测试法得到的密钥字的长度的正确性。
3拟重合指数测试法
拟重合指数测试法:首先子密文段重各个字母的频率进行统计(记为fi, i∈a – z),查看字母频率分布统计概率(记pi),计算子密文段长度为n,使用公式:
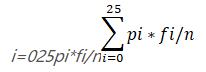
计算出M0,然后对子密文段移位25次,同样按照上述方法求出M1 — M25的值
根据重合指数的定义知:一个有意义的英文文本,M ≈0.065,所以利用这个规律,就可以确定秘钥中的每一个字母
代码实现
def main():
fo=open("cipher.txt","r")
s=fo.read()
s=str(s)
fo.close()
ic=0
max_num=len(s)//26
# while ic<0.06:
#def fenzu():
#分组
aves=[0]*max_num
for i in range(1,max_num):
count = 0
zicuan=[]
for t in range (i):
fz=s[t:len(s):i]
zicuan+=[fz]
count+=1
#print(count,'韩庚韩庚韩庚',zicuan)
for js in range (i):
zicuan[js]=zicuan[js].upper()
ics=[0]*count
#统计每个分组的IC值
for r in range(count):
ics[r]=tongjicisu(zicuan[r])
ave =sum(ics)/count
print('第{}次分片的IC值是{}'.format(i,ave))
aves[i-1]=ave
#找到最可能的密钥分组
key_index=1
max = 1
for i in range(max_num):
max1=abs(aves[i]-0.065)
if max1<max:
max=max1
key_index=i+1
print('key_length',key_index)
key = [None]*key_index
#得到密钥长度后从新按密钥长度分片计算
zicuan2 = []
for t in range(key_index):
fz = s[t:len(s):key_index]
zicuan2 += [fz]
for i in range(key_index):
key[i]=decode(zicuan2[i])
print(key)
di = {}.fromkeys(key)
key=di.keys()
keys=""
for i in key:
keys+=i
print(keys,"密钥")
mc = VigenereDecrypto(s,keys)
print(mc,'ecewew')
# 统计次数IC值
def tongjicisu(s):
tongjicisu = [0] * 26
zff = ""
ic=-0
for t in s:
if 65 <= ord(t) <= 90:
zff += t
for cisu in zff:
tongjicisu[ord(cisu) - 65] += 1
for i in range (len(tongjicisu)):
xic=tongjicisu[i]*(tongjicisu[i]-1)/len(zff)/(len(zff)-1)
ic+=xic
return ic
def decode(s):
nicos=[0]*26
for i in range(26):
nicos[i]=tongjinichonghe(i,s)
list1=sorted(nicos)
num = nicos.index(list1[-1])
ch = chr(num+65)
#print(ch)
return ch
#计算拟重合指数
def tongjinichonghe(key,s):
sniic=0
p = [0.08167, 0.01492, 0.02782, 0.04253, 0.12702, 0.02228, 0.02015, 0.06094, 0.06966, 0.00153, 0.00772, 0.04025,
0.02406, 0.06749, 0.07507, 0.01929, 0.00095, 0.05987, 0.06327, 0.09056, 0.02758, 0.00978, 0.02360, 0.00150,
0.01974, 0.00074]
tongjinichonghe = [0] * 26
zff = ""
#ic=-0
#转换为只有大写字母的字符串
for t in s:
if 65 <= ord(t) <= 90:
zff += t
#统计每个字母出现的次数
for cisu in zff:
tongjinichonghe[ord(cisu) - 65] += 1
#求出每个凯撒加密的解密,根据拟重合指数找到正确的密钥
list0=tongjinichonghe
list1=[0]*26
for i in range (26):
list1[i]=list0[(i+key)%26]
tongjinichonghe=list1
for i in range (len(tongjinichonghe)):
niic=tongjinichonghe[i]/len(tongjinichonghe)*p[i]
sniic+=niic
return sniic
def VigenereDecrypto(ciphertext, key):
msLen = len(ciphertext)
keyLen = len(key)
key = key.upper()
raw = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"# 密文空间
plaintext = ""
for i in range(0, msLen):# 开始解密
# 轮询key的字符
j = i % keyLen
# 判断字符是否为英文字符,不是则直接向后面追加且继续
if ciphertext[i] not in raw:
plaintext += ciphertext[i]
continue
decodechr = chr((ord(ciphertext[i]) - ord("A") - ord(key[j]) - ord("A")) % 26 + ord("A"))
# 追加字符
plaintext += decodechr
# 返回加密后的字符串
return plaintext
if __name__ == '__main__':
main()
加载全部内容