Python爬虫_城市公交网络站点数据的爬取 Python爬虫实例_城市公交网络站点数据的爬取方法
WenWu_Both 人气:0想了解Python爬虫实例_城市公交网络站点数据的爬取方法的相关内容吗,WenWu_Both在本文为您仔细讲解Python爬虫_城市公交网络站点数据的爬取的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:Python,爬虫,城市公交,站点,爬取,下面大家一起来学习吧。
爬取的站点:http://beijing.8684.cn/
(1)环境配置,直接上代码:
# -*- coding: utf-8 -*-
import requests ##导入requests
from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup
import os
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}
all_url = 'http://beijing.8684.cn' ##开始的URL地址
start_html = requests.get(all_url, headers=headers)
#print (start_html.text)
Soup = BeautifulSoup(start_html.text, 'lxml') # 以lxml的方式解析html文档
(2)爬取站点分析
1、北京市公交线路分类方式有3种:

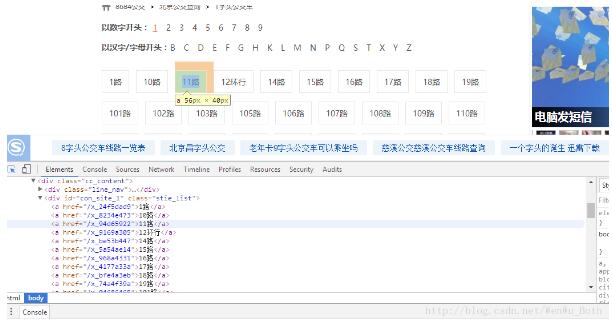
本文通过数字开头来进行爬取,“F12”启动开发者工具,点击“Elements”,点击“1”,可以发现链接保存在<div class="bus_kt_r1">里面,故只需要提取出div里的href即可:
代码:
all_a = Soup.find(‘div',class_='bus_kt_r1').find_all(‘a')
2、接着往下,发现每1路的链接都在<div id="con_site_1" class="site_list"> 的<a>里面,取出里面的herf即为线路网址,其内容即为线路名称,代码:
href = a['href'] #取出a标签的href 属性
html = all_url + href
second_html = requests.get(html,headers=headers)
#print (second_html.text)
Soup2 = BeautifulSoup(second_html.text, 'lxml')
all_a2 = Soup2.find('div',class_='cc_content').find_all('div')[-1].find_all('a') # 既有id又有class的div不知道为啥取不出来,只好迂回取了
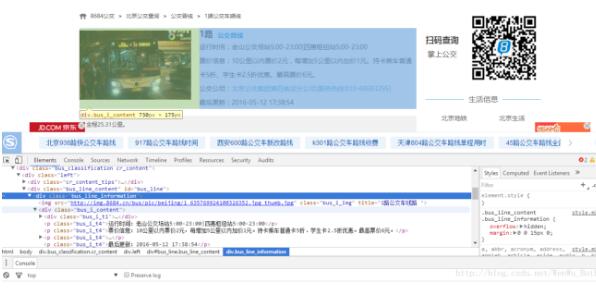
3、打开线路链接,就可以看到具体的站点信息了,打开页面分析文档结构后发现:线路的基本信息存放在<div class="bus_i_content">里面,而公交站点信息则存放在<div class="bus_line_top">及<div class="bus_line_site">里面,提取代码:
title1 = a2.get_text() #取出a1标签的文本
href1 = a2['href'] #取出a标签的href 属性
#print (title1,href1)
html_bus = all_url + href1 # 构建线路站点url
thrid_html = requests.get(html_bus,headers=headers)
Soup3 = BeautifulSoup(thrid_html.text, 'lxml')
bus_name = Soup3.find('div',class_='bus_i_t1').find('h1').get_text() # 提取线路名
bus_type = Soup3.find('div',class_='bus_i_t1').find('a').get_text() # 提取线路属性
bus_time = Soup3.find_all('p',class_='bus_i_t4')[0].get_text() # 运行时间
bus_cost = Soup3.find_all('p',class_='bus_i_t4')[1].get_text() # 票价
bus_company = Soup3.find_all('p',class_='bus_i_t4')[2].find('a').get_text() # 公交公司
bus_update = Soup3.find_all('p',class_='bus_i_t4')[3].get_text() # 更新时间
bus_label = Soup3.find('div',class_='bus_label')
if bus_label:
bus_length = bus_label.get_text() # 线路里程
else:
bus_length = []
#print (bus_name,bus_type,bus_time,bus_cost,bus_company,bus_update)
all_line = Soup3.find_all('div',class_='bus_line_top') # 线路简介
all_site = Soup3.find_all('div',class_='bus_line_site')# 公交站点
line_x = all_line[0].find('div',class_='bus_line_txt').get_text()[:-9]+all_line[0].find_all('span')[-1].get_text()
sites_x = all_site[0].find_all('a')
sites_x_list = [] # 上行线路站点
for site_x in sites_x:
sites_x_list.append(site_x.get_text())
line_num = len(all_line)
if line_num==2: # 如果存在环线,也返回两个list,只是其中一个为空
line_y = all_line[1].find('div',class_='bus_line_txt').get_text()[:-9]+all_line[1].find_all('span')[-1].get_text()
sites_y = all_site[1].find_all('a')
sites_y_list = [] # 下行线路站点
for site_y in sites_y:
sites_y_list.append(site_y.get_text())
else:
line_y,sites_y_list=[],[]
information = [bus_name,bus_type,bus_time,bus_cost,bus_company,bus_update,bus_length,line_x,sites_x_list,line_y,sites_y_list]
自此,我们就把一条线路的相关信息及上、下行站点信息就都解析出来了。如果想要爬取全市的公交网络站点,只需要加入循环就可以了。
完整代码:
# -*- coding: utf-8 -*-
# Python3.5
import requests ##导入requests
from bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup
import os
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0'}
all_url = 'http://beijing.8684.cn' ##开始的URL地址
start_html = requests.get(all_url, headers=headers)
#print (start_html.text)
Soup = BeautifulSoup(start_html.text, 'lxml')
all_a = Soup.find('div',class_='bus_kt_r1').find_all('a')
Network_list = []
for a in all_a:
href = a['href'] #取出a标签的href 属性
html = all_url + href
second_html = requests.get(html,headers=headers)
#print (second_html.text)
Soup2 = BeautifulSoup(second_html.text, 'lxml')
all_a2 = Soup2.find('div',class_='cc_content').find_all('div')[-1].find_all('a') # 既有id又有class的div不知道为啥取不出来,只好迂回取了
for a2 in all_a2:
title1 = a2.get_text() #取出a1标签的文本
href1 = a2['href'] #取出a标签的href 属性
#print (title1,href1)
html_bus = all_url + href1
thrid_html = requests.get(html_bus,headers=headers)
Soup3 = BeautifulSoup(thrid_html.text, 'lxml')
bus_name = Soup3.find('div',class_='bus_i_t1').find('h1').get_text()
bus_type = Soup3.find('div',class_='bus_i_t1').find('a').get_text()
bus_time = Soup3.find_all('p',class_='bus_i_t4')[0].get_text()
bus_cost = Soup3.find_all('p',class_='bus_i_t4')[1].get_text()
bus_company = Soup3.find_all('p',class_='bus_i_t4')[2].find('a').get_text()
bus_update = Soup3.find_all('p',class_='bus_i_t4')[3].get_text()
bus_label = Soup3.find('div',class_='bus_label')
if bus_label:
bus_length = bus_label.get_text()
else:
bus_length = []
#print (bus_name,bus_type,bus_time,bus_cost,bus_company,bus_update)
all_line = Soup3.find_all('div',class_='bus_line_top')
all_site = Soup3.find_all('div',class_='bus_line_site')
line_x = all_line[0].find('div',class_='bus_line_txt').get_text()[:-9]+all_line[0].find_all('span')[-1].get_text()
sites_x = all_site[0].find_all('a')
sites_x_list = []
for site_x in sites_x:
sites_x_list.append(site_x.get_text())
line_num = len(all_line)
if line_num==2: # 如果存在环线,也返回两个list,只是其中一个为空
line_y = all_line[1].find('div',class_='bus_line_txt').get_text()[:-9]+all_line[1].find_all('span')[-1].get_text()
sites_y = all_site[1].find_all('a')
sites_y_list = []
for site_y in sites_y:
sites_y_list.append(site_y.get_text())
else:
line_y,sites_y_list=[],[]
information = [bus_name,bus_type,bus_time,bus_cost,bus_company,bus_update,bus_length,line_x,sites_x_list,line_y,sites_y_list]
Network_list.append(information)
# 定义保存函数,将运算结果保存为txt文件
def text_save(content,filename,mode='a'):
# Try to save a list variable in txt file.
file = open(filename,mode)
for i in range(len(content)):
file.write(str(content[i])+'\n')
file.close()
# 输出处理后的数据
text_save(Network_list,'Network_bus.txt');
最后输出整个城市的公交网络站点信息,这次就先保存在txt文件里吧,也可以保存到数据库里,比如mysql或者MongoDB里,这里我就不写了,有兴趣的可以试一下,附上程序运行后的结果图:

以上这篇Python爬虫实例_城市公交网络站点数据的爬取方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
加载全部内容