pandas进阶教程 Python 数据处理库 pandas进阶教程
强波 人气:0前言
本文紧接着前一篇的入门教程,会介绍一些关于pandas的进阶知识。建议读者在阅读本文之前先看完pandas入门教程。
同样的,本文的测试数据和源码可以在这里获取: Github:pandas_tutorial 。
数据访问
在入门教程中,我们已经使用过访问数据的方法。这里我们再集中看一下。
注:这里的数据访问方法既适用于Series,也适用于DataFrame。
基础方法:[]和.
这是两种最直观的方法,任何有面向对象编程经验的人应该都很容易理解。下面是一个代码示例:
# select_data.py
import pandas as pd
import numpy as np
series1 = pd.Series([1, 2, 3, 4, 5, 6, 7],
index=["C", "D", "E", "F", "G", "A", "B"])
print("series1['E'] = {} \n".format(series1['E']));
print("series1.E = {} \n".format(series1.E));
这段代码输出如下:
series1['E'] = 3
series1.E = 3
注1:对于类似属性的访问方式.来说,要求索引元素必须是有效的Python标识符的时候才可以,而对于series1.1这样的索引是不行的。
注2:[]和.提供了简单和快速访问pands数据结构的方法。这种方法非常的直观。然而,由于要访问的数据类型并不是事先知道的,因此使用这两种方法方式存在一些优化限制。因此对于产品级的代码来说,pandas官方建议使用pandas库中提供的数据访问方法。
loc与iloc
在入门教程中,我们已经提到了这两个操作符:
- loc:通过行和列的索引来访问数据
- iloc:通过行和列的下标来访问数据
注意:索引的类型可能是整数。
实际上,当DataFrame通过这两个操作符访问数据,可以只指定一个索引来访问一行的数据,例如:
# select_data.py
df1 = pd.DataFrame({"note" : ["C", "D", "E", "F", "G", "A", "B"],
"weekday": ["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"]},
index=['1', '2', '3', '4', '5', '6', '7'])
print("df1.loc['2']:\n{}\n".format(df1.loc['2']))
这里通过索引'2'可以方法到第2行的所有数据,因此它的输出如下:
df1.loc['2']:
note D
weekday Tue
Name: 2, dtype: object
除此之外,通过这两个操作符我们还可以访问某个范围之内的数据,例如这样:
# select_data.py
print("series1.loc['E':'A']=\n{}\n".format(series1.loc['E':'A']));
print("df1.iloc[2:4]=\n{}\n".format(df1.iloc[2:4]))
这段代码输出如下:
series1.loc['E':'A']=
E 3
F 4
G 5
A 6
dtype: int64df1.iloc[2:3]=
note weekday
3 E Wed
4 F Thu
at与iat
这两个操作符用来访问单个的元素值(Scalar Value)。类似的:
- at:通过行和列的索引来访问数据
- iat:通过行和列的下标来访问数据
# select_data.py
print("series1.at['E']={}\n".format(series1.at['E']));
print("df1.iloc[4,1]={}\n".format(df1.iloc[4,1]))
这两行代码输出如下:
series1.at['E']=3
df1.iloc[4,1]=Fri
Index对象
在入门教程我们也已经简单介绍过Index,Index提供了查找,数据对齐和重新索引所需的基础数据结构。
最直接的,我们可以通过一个数组来创建Index对象。在创建的同时我们还可以通过name指定索引的名称:
# index.py index = pd.Index(['C','D','E','F','G','A','B'], name='note')
Index类提供了很多的方法进行各种操作,这个建议读者直接查询API说明即可,这里不多做说明。稍微提一下的是,Index对象可以互相之间做集合操作,例如:
# index.py
a = pd.Index([1,2,3,4,5])
b = pd.Index([3,4,5,6,7])
print("a|b = {}\n".format(a|b))
print("a&b = {}\n".format(a&b))
print("a.difference(b) = {}\n".format(a.difference(b)))
这几个运算的结果如下:
a|b = Int64Index([1, 2, 3, 4, 5, 6, 7], dtype='int64')
a&b = Int64Index([3, 4, 5], dtype='int64')
a.difference(b) = Int64Index([1, 2], dtype='int64')
Index类有很多的子类,下面是最常见的一些:
MultiIndex
MultiIndex,或者称之为Hierarchical Index是指数据的行或者列通过多层次的标签来进行索引。
例如,我们要通过一个MultiIndex描述三个公司在三年内每个季度的营业额,可以这样:
# multiindex.py
import pandas as pd
import numpy as np
multiIndex = pd.MultiIndex.from_arrays([
['Geagle', 'Geagle', 'Geagle', 'Geagle',
'Epple', 'Epple', 'Epple', 'Epple', 'Macrosoft',
'Macrosoft', 'Macrosoft', 'Macrosoft', ],
['S1', 'S2', 'S3', 'S4', 'S1', 'S2', 'S3', 'S4', 'S1', 'S2', 'S3', 'S4']],
names=('Company', 'Turnover'))
这段代码输出如下:
multiIndex =
MultiIndex(levels=[['Epple', 'Geagle', 'Macrosoft'], ['S1', 'S2', 'S3', 'S4']],
labels=[[1, 1, 1, 1, 0, 0, 0, 0, 2, 2, 2, 2], [0, 1, 2, 3, 0, 1, 2, 3, 0, 1, 2, 3]],
names=['Company', 'Turnover'])
从这个输出可以看出,MultiIndex中的levels数组数量对应了索引的级别数量,labels对应了levels中元素的下标。
下面我们用一个随机数来构造一个DataFrame:
# multiindex.py
df = pd.DataFrame(data=np.random.randint(0, 1000, 36).reshape(-1, 12),
index=[2016, 2017, 2018],
columns=multiIndex)
print("df = \n{}\n".format(df))
这里创建出了36个[0, 1000)之间的随机数,然后组装成3行12列的矩阵(如果你对NumPy不熟悉可以访问NumPy官网学习,或者看一下我之前写过的:Python 机器学习库 NumPy 教程)。
上面这段代码输出如下:
df =
Company Geagle Epple Macrosoft
Turnover S1 S2 S3 S4 S1 S2 S3 S4 S1 S2 S3 S4
2016 329 25 553 852 833 710 247 990 215 991 535 846
2017 734 368 28 161 187 444 901 858 244 915 261 485
2018 769 707 458 782 948 169 927 237 279 438 738 708
这个输出很直观的可以看出三个公司在三年内每个季度的营业额。
有了多级索引,我们可以方便的进行数据的筛选,例如:
- 通过df.loc[2017, (['Geagle', 'Epple', 'Macrosoft'] ,'S1')])筛选出三个公司2017年第一季度的营业额
- 通过df.loc[2018, 'Geagle']筛选出Geagle公司2018年每个季度的营业额
它们输出如下:
2017 S1:
Company Turnover
Geagle S1 734
Epple S1 187
Macrosoft S1 244
Name: 2017, dtype: int64Geagle 2018:
Turnover
S1 769
S2 707
S3 458
S4 782
Name: 2018, dtype: int64
数据整合
Concat:串联,连接,级连
Append:附加,增补
Merge:融合,归并,合并
Join:合并,接合,交接
Concat与Append
concat函数的作用是将多个数据串联到一起。例如,某个多条数据分散在3个地方记录,最后我们将三个数据添加到一起。下面是一个代码示例:
# concat_append.py
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'Note': ['C', 'D'],
'Weekday': ['Mon', 'Tue']},
index=[1, 2])
df2 = pd.DataFrame({'Note': ['E', 'F'],
'Weekday': ['Wed', 'Thu']},
index=[3, 4])
df3 = pd.DataFrame({'Note': ['G', 'A', 'B'],
'Weekday': ['Fri', 'Sat', 'Sun']},
index=[5, 6, 7])
df_concat = pd.concat([df1, df2, df3], keys=['df1', 'df2', 'df3'])
print("df_concat=\n{}\n".format(df_concat))
这里我们通过keys指定了三个数据的索引划分,最后的数据中会由此存在MultiIndex。这段代码输出如下:
df_concat=
Note Weekday
df1 1 C Mon
2 D Tue
df2 3 E Wed
4 F Thu
df3 5 G Fri
6 A Sat
7 B Sun
请仔细思考一下df_concat结构与原先三个数据结构的关系:其实它就是将原先三个数据纵向串联起来了。另外,请关注一下MultiIndex结构。
concat函数默认是以axis=0(行)为主进行串联。如果需要,我们可以指定axis=1(列)为主进行串联:
# concat_append.py
df_concat_column = pd.concat([df1, df2, df3], axis=1)
print("df_concat_column=\n{}\n".format(df_concat_column))
这个结构输出如下:
df_concat_column=
Note Weekday Note Weekday Note Weekday
1 C Mon NaN NaN NaN NaN
2 D Tue NaN NaN NaN NaN
3 NaN NaN E Wed NaN NaN
4 NaN NaN F Thu NaN NaN
5 NaN NaN NaN NaN G Fri
6 NaN NaN NaN NaN A Sat
7 NaN NaN NaN NaN B Sun
请再次观察一下这里的结果和原先三个数据结构之间的关系。
concat是将多个数据串联在一起。类似的,对于某个具体的数据来说,我们可以在其数据基础上添加(append)其他数据来进行串联:
# concat_append.py
df_append = df1.append([df2, df3])
print("df_append=\n{}\n".format(df_append))
这个操作的结果和之前的concat是一样的:
df_append=
Note Weekday
1 C Mon
2 D Tue
3 E Wed
4 F Thu
5 G Fri
6 A Sat
7 B Sun
Merge与Join
pandas中的Merge操作和SQL语句中的Join操作是类似的。Join操作可以分为下面几种:
- INNER
- LEFT OUTER
- RIGHT OUTER
- FULL OUTER
- CROSS
关于这几种的Join操作的含义请参阅其他资料,例如维基百科:Join
使用pandas进行Merge操作很简单,下面是一段代码示例:
# merge_join.py
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'key': ['K1', 'K2', 'K3', 'K4'],
'A': ['A1', 'A2', 'A3', 'A8'],
'B': ['B1', 'B2', 'B3', 'B8']})
df2 = pd.DataFrame({'key': ['K3', 'K4', 'K5', 'K6'],
'A': ['A3', 'A4', 'A5', 'A6'],
'B': ['B3', 'B4', 'B5', 'B6']})
print("df1=\n{}\n".format(df1))
print("df2=\n{}\n".format(df2))
merge_df = pd.merge(df1, df2)
merge_inner = pd.merge(df1, df2, how='inner', on=['key'])
merge_left = pd.merge(df1, df2, how='left')
merge_left_on_key = pd.merge(df1, df2, how='left', on=['key'])
merge_right_on_key = pd.merge(df1, df2, how='right', on=['key'])
merge_outer = pd.merge(df1, df2, how='outer', on=['key'])
print("merge_df=\n{}\n".format(merge_df))
print("merge_inner=\n{}\n".format(merge_inner))
print("merge_left=\n{}\n".format(merge_left))
print("merge_left_on_key=\n{}\n".format(merge_left_on_key))
print("merge_right_on_key=\n{}\n".format(merge_right_on_key))
print("merge_outer=\n{}\n".format(merge_outer))
这段代码说明如下:
- merge函数的join参数的默认值是“inner”,因此merge_df是两个数据的inner join的结果。另外,在不指明的情况下,merge函数使用所有同名的列名作为key来进行运算。
- merge_inner是指定了列的名称进行inner join。
- merge_left是left outer join的结果
- merge_left_on_key是指定了列名进行left outer join的结果
- merge_right_on_key是指定了列名进行right outer join的结果
- merge_outer是full outer join的结果
这里的结果如下,请观察一下结果与你的预算是否一致:
df1=
A B key
0 A1 B1 K1
1 A2 B2 K2
2 A3 B3 K3
3 A8 B8 K4df2=
A B key
0 A3 B3 K3
1 A4 B4 K4
2 A5 B5 K5
3 A6 B6 K6merge_df=
A B key
0 A3 B3 K3merge_inner=
A_x B_x key A_y B_y
0 A3 B3 K3 A3 B3
1 A8 B8 K4 A4 B4merge_left=
A B key
0 A1 B1 K1
1 A2 B2 K2
2 A3 B3 K3
3 A8 B8 K4merge_left_on_key=
A_x B_x key A_y B_y
0 A1 B1 K1 NaN NaN
1 A2 B2 K2 NaN NaN
2 A3 B3 K3 A3 B3
3 A8 B8 K4 A4 B4merge_right_on_key=
A_x B_x key A_y B_y
0 A3 B3 K3 A3 B3
1 A8 B8 K4 A4 B4
2 NaN NaN K5 A5 B5
3 NaN NaN K6 A6 B6merge_outer=
A_x B_x key A_y B_y
0 A1 B1 K1 NaN NaN
1 A2 B2 K2 NaN NaN
2 A3 B3 K3 A3 B3
3 A8 B8 K4 A4 B4
4 NaN NaN K5 A5 B5
5 NaN NaN K6 A6 B6
DataFrame也提供了join函数来根据索引进行数据合并。它可以被用于合并多个DataFrame,这些DataFrame有相同的或者类似的索引,但是没有重复的列名。默认情况下,join函数执行left join。另外,假设两个数据有相同的列名,我们可以通过lsuffix和rsuffix来指定结果中列名的前缀。下面是一段代码示例:
# merge_join.py
df3 = pd.DataFrame({'key': ['K1', 'K2', 'K3', 'K4'],
'A': ['A1', 'A2', 'A3', 'A8'],
'B': ['B1', 'B2', 'B3', 'B8']},
index=[0, 1, 2, 3])
df4 = pd.DataFrame({'key': ['K3', 'K4', 'K5', 'K6'],
'C': ['A3', 'A4', 'A5', 'A6'],
'D': ['B3', 'B4', 'B5', 'B6']},
index=[1, 2, 3, 4])
print("df3=\n{}\n".format(df3))
print("df4=\n{}\n".format(df4))
join_df = df3.join(df4, lsuffix='_self', rsuffix='_other')
join_left = df3.join(df4, how='left', lsuffix='_self', rsuffix='_other')
join_right = df1.join(df4, how='outer', lsuffix='_self', rsuffix='_other')
print("join_df=\n{}\n".format(join_df))
print("join_left=\n{}\n".format(join_left))
print("join_right=\n{}\n".format(join_right))
这段代码输出如下:
df3=
A B key
0 A1 B1 K1
1 A2 B2 K2
2 A3 B3 K3
3 A8 B8 K4df4=
C D key
1 A3 B3 K3
2 A4 B4 K4
3 A5 B5 K5
4 A6 B6 K6join_df=
A B key_self C D key_other
0 A1 B1 K1 NaN NaN NaN
1 A2 B2 K2 A3 B3 K3
2 A3 B3 K3 A4 B4 K4
3 A8 B8 K4 A5 B5 K5join_left=
A B key_self C D key_other
0 A1 B1 K1 NaN NaN NaN
1 A2 B2 K2 A3 B3 K3
2 A3 B3 K3 A4 B4 K4
3 A8 B8 K4 A5 B5 K5join_right=
A B key_self C D key_other
0 A1 B1 K1 NaN NaN NaN
1 A2 B2 K2 A3 B3 K3
2 A3 B3 K3 A4 B4 K4
3 A8 B8 K4 A5 B5 K5
4 NaN NaN NaN A6 B6 K6
数据集合和分组操作
很多时候,我们会需要对批量的数据进行分组统计或者再处理,groupby,agg,apply就是用来做这件事的。
- groupby将数据分组,分组后得到pandas.core.groupby.DataFrameGroupBy类型的数据。
- agg用来进行合计操作,agg是aggregate的别名。
- apply用来将函数func分组化并将结果组合在一起。
这些概念都很抽象,我们还是通过代码来进行说明。
# groupby.py
import pandas as pd
import numpy as np
df = pd.DataFrame({
'Name': ['A','A','A','B','B','B','C','C','C'],
'Data': np.random.randint(0, 100, 9)})
print('df=\n{}\n'.format(df))
groupby = df.groupby('Name')
print("Print GroupBy:")
for name, group in groupby:
print("Name: {}\nGroup:\n{}\n".format(name, group))
在这段代码中,我们生成了9个[0, 100)之间的随机数,数据的第一列是['A','A','A','B','B','B','C','C','C']。然后我们以Name列进行groupby,得到的结果会根据将Name列值一样的分组在一起,我们将得到的结果进行了打印。这段代码的输出如下:
df=
Data Name
0 34 A
1 44 A
2 57 A
3 81 B
4 78 B
5 65 B
6 73 C
7 16 C
8 1 CPrint GroupBy:
Name: A
Group:
Data Name
0 34 A
1 44 A
2 57 AName: B
Group:
Data Name
3 81 B
4 78 B
5 65 BName: C
Group:
Data Name
6 73 C
7 16 C
8 1 C
groupby并不是我们的最终目的,我们的目的是希望分组后还要对这些数据进行进一步的统计或者处理。pandas库本身就提供了很多进行操作的函数,例如:count,sum,mean,median,std,var,min,max,prod,first,last。这些函数的名称很容易明白它的作用。
例如:groupby.sum()就是对结果进行求和运行。
除了直接调用这些函数之外,我们也可以通过agg函数来达到这个目的,这个函数接收其他函数的名称,例如这样:groupby.agg(['sum'])。
通过agg函数,可以一次性调用多个函数,并且可以为结果列指定名称。
像这样:groupby.agg([('Total', 'sum'), ('Min', 'min')])。
这里的三个调用输出结果如下:
# groupby.py Sum: Data Name A 135 B 224 C 90 Agg Sum: Data sum Name A 135 B 224 C 90 Agg Map: Data Total Min Name A 135 34 B 224 65 C 90 1
除了对数据集合进行统计,我们也可以通过apply函数进行分组数据的处理。像这样:
# groupby.py
def sort(df):
return df.sort_values(by='Data', ascending=False)
print("Sort Group: \n{}\n".format(groupby.apply(sort)))
在这段代码中,我们定义了一个排序函数,并应用在分组数据上,这里最终的输出如下:
Sort Group:
Data
Name
A 2 57
1 44
0 34
B 3 81
4 78
5 65
C 6 73
7 16
8 1
时间相关
时间是应用程序中很频繁需要处理的逻辑,尤其是对于金融,科技,商业等领域。
当我们在讨论时间,我们讨论的可能是下面三种情况中的一种:
- 某个具体的时间点(Timestamp),例如:今天下午一点整
- 某个时间范围(Period),例如:整个这个月
- 某个时间间隔(Interval),例如:每周二上午七点整
Python语言提供了时间日期相关的基本API,它们位于datetime, time, calendar几个模块中。下面是一个代码示例:
# time.py
import datetime as dt
import numpy as np
import pandas as pd
now = dt.datetime.now();
print("Now is {}".format(now))
yesterday = now - dt.timedelta(1);
print("Yesterday is {}\n".format(yesterday.strftime('%Y-%m-%d')))
在这段代码中,我们打印了今天的日期,并通过timedelta进行了日期的减法运算。这段代码输出如下:
借助pandas提供的接口,我们可以很方便的获得以某个时间间隔的时间序列,例如这样:
# time.py
this_year = pd.date_range(dt.datetime(2018, 1, 1),
dt.datetime(2018, 12, 31), freq='5D')
print("Selected days in 2018: \n{}\n".format(this_year))
这段代码获取了整个2018年中从元旦开始,每隔5天的日期序列。
date_range函数的详细说明见这里:pandas.date_range
这段代码的输出如下:
Selected days in 2018:
DatetimeIndex(['2018-01-01', '2018-01-06', '2018-01-11', '2018-01-16',
'2018-01-21', '2018-01-26', '2018-01-31', '2018-02-05',
'2018-02-10', '2018-02-15', '2018-02-20', '2018-02-25',
'2018-03-02', '2018-03-07', '2018-03-12', '2018-03-17',
'2018-03-22', '2018-03-27', '2018-04-01', '2018-04-06',
'2018-04-11', '2018-04-16', '2018-04-21', '2018-04-26',
'2018-05-01', '2018-05-06', '2018-05-11', '2018-05-16',
'2018-05-21', '2018-05-26', '2018-05-31', '2018-06-05',
'2018-06-10', '2018-06-15', '2018-06-20', '2018-06-25',
'2018-06-30', '2018-07-05', '2018-07-10', '2018-07-15',
'2018-07-20', '2018-07-25', '2018-07-30', '2018-08-04',
'2018-08-09', '2018-08-14', '2018-08-19', '2018-08-24',
'2018-08-29', '2018-09-03', '2018-09-08', '2018-09-13',
'2018-09-18', '2018-09-23', '2018-09-28', '2018-10-03',
'2018-10-08', '2018-10-13', '2018-10-18', '2018-10-23',
'2018-10-28', '2018-11-02', '2018-11-07', '2018-11-12',
'2018-11-17', '2018-11-22', '2018-11-27', '2018-12-02',
'2018-12-07', '2018-12-12', '2018-12-17', '2018-12-22',
'2018-12-27'],
dtype='datetime64[ns]', freq='5D')
我们得到的返回值是DatetimeIndex类型的,我们可以创建一个DataFrame并以此作为索引:
# time.py
df = pd.DataFrame(np.random.randint(0, 100, this_year.size), index=this_year)
print("Jan: \n{}\n".format(df['2018-01']))
在这段代码中,我们创建了与索引数量一样多的[0, 100)间的随机整数,并用this_year作为索引。用DatetimeIndex作索引的好处是,我们可以直接指定某个范围来选择数据,例如,通过df['2018-01']选出所有1月份的数据。
这段代码输出如下:
图形展示
pandas的图形展示依赖于matplotlib库。对于这个库,我们在后面会专门讲解,因为这里仅仅提供一个简单的代码示例,让大家感受一下图形展示的样子。
代码示例如下:
# plot.py
import matplotlib.pyplot as plt
import pandas as pd
data = pd.read_csv("data/housing.csv")
data.hist(bins=50, figsize=(15, 12))
plt.show()
这段代码读取了一个CSV文件,这个文件中包含了一些关于房价的信息。在读取完之后,通过直方图(hist)将其展示了出来。
该CSV文件的内容见这里:pandas_tutorial/data/housing.csv
直方图结果如下所示:
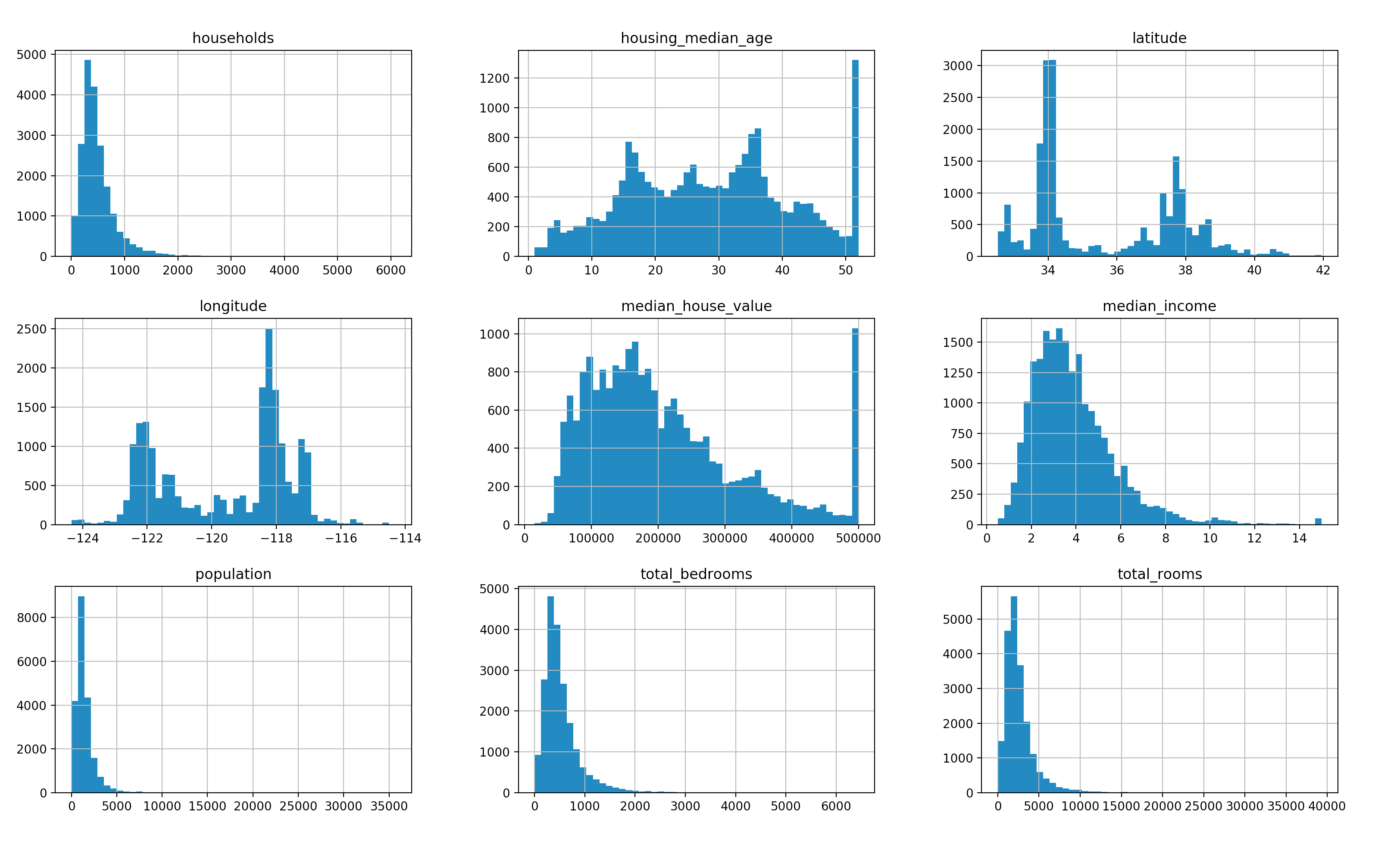
结束语
虽然本文的标题是“进阶篇”,我们也讨论了一些更深入的知识。但很显然,这对于pandas来说,仍然是很皮毛的东西。由于篇幅所限,更多的内容在今后的时候,有机会我们再来一起探讨。
读者朋友也可以根据官网上的文档进行更深入的学习。
参考资料与推荐读物
加载全部内容