python 列表基础知识 Python 专题五 列表基础知识(二维list排序、获取下标和处理txt文本实例)
Eastmount 人气:0通常测试人员或公司实习人员需要处理一些txt文本内容,而此时使用Python是比较方便的语言。它不光在爬取网上资料上方便,还在NLP自然语言处理方面拥有独到的优势。这篇文章主要简单的介绍使用Python处理txt汉字文字、二维列表排序和获取list下标。希望文章对你有所帮助或提供一些见解~
一. list二维数组排序
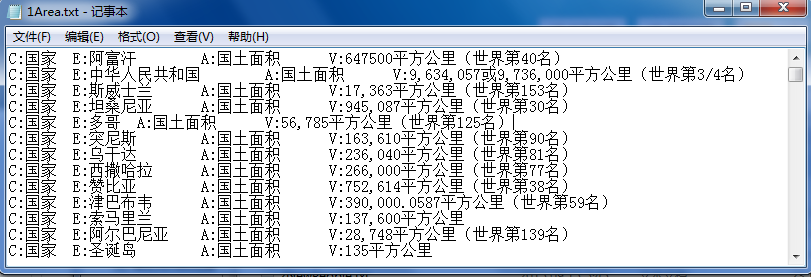
功能:已经通过Python从维基百科中获取了国家的国土面积和排名信息,此时需要获取国土面积并进行排序判断世界排名是否正确。
列表基础知识
列表类型同字符串一样也是序列式的数据类型,可以通过下标或切片操作来访问某一个或某一块连续的元素。它和字符串不同之处在于:字符串只能由字符组成而且不可变的(不能单独改变它的某个值),而列表是能保留任意数目的Python对象灵活容器。
总之,列表可以包含不同类型的对象(包括用户自定义的对象)作为元素,列表可以添加或删除元素,也可以合并或拆分列表,包括insert、update、remove、sprt、reverse等操作。
列表排序介绍
常用列表排序方法包括使用List内建函数list.sort()或序列类型函数sorted(list)排序
#list.sort(func=None, key=None, reverse=False) list = [4, 3, 9, 1, 5, 2] print list list.sort() print list #输出 [4, 3, 9, 1, 5, 2] [1, 2, 3, 4, 5, 9]
通过对比下面的代码,可以发现两种方法的区别是:list.sort()改变了原list的顺序,而sorted没有。
#sorted(list) list = ['h', 'a', 'p', 'd', 'i', 'b'] print list print sorted(list) print list #输出 ['h', 'a', 'p', 'd', 'i', 'b'] ['a', 'b', 'd', 'h', 'i', 'p'] ['h', 'a', 'p', 'd', 'i', 'b']
二维列表排序
通过lambda表达式实现二维列表排序,并且按照第二个关键字进行排序。参考文章
#list.sort(func=None, key=None, reverse=False)
list = [('Tom',4),('Jack',7),('Daly',9),('Mary',1),('God',5),('Yuri',3)]
print list
list.sort(lambda x,y:cmp(x[1],y[1]))
print list
#输出
[('Tom', 4), ('Jack', 7), ('Daly', 9), ('Mary', 1), ('God', 5), ('Yuri', 3)]
[('Mary', 1), ('Yuri', 3), ('Tom', 4), ('God', 5), ('Jack', 7), ('Daly', 9)]
题目中如果第一个数存储文件中读取的行号,第二个数存储人口数量,此时可对第二个数进行排序。需要注意的是它们一组(1,93)是tuple元组。
#list.sort(func=None, key=None, reverse=False) list = [(1,93),(2,71),(3,89),(4,93),(5,85),(6,77)] print list list.sort(key=lambda x:x[1]) print list #输出 [(1, 93), (2, 71), (3, 89), (4, 93), (5, 85), (6, 77)] [(2, 71), (6, 77), (5, 85), (3, 89), (1, 93), (4, 93)]
lambada表达式
在上述代码中,如果还不知道lambada是什么鬼东西的话?那我就来帮你回顾了。
python允许使用lambda关键字创造匿名函数,它不需要以标准的方式来声明,如def语句。然而作为函数,它们也能有参数。
lambda就是一个表达式,而不是一个代码块。而且这个表达是的定义必须和声明放在同一行,能在lambda中封装有限的逻辑进去,起到一个函数速写的作用。例如:
#lambda [arg1[, arg2, ..., argN]]:expression f = lambda x,y,z:x+y+z num = f(1,2,3) print 'lambda: ' + str(num) #等价于 def add(x,y,z): return x+y+z num = add(1,2,3) print 'function: ' + str(num) #输出 lambda: 6 function: 6
二. 处理txt文本
下面是通过txt文件按行读取,并获取面积进行排序。其中核心代码如下:
读取文件&列表添加
source = open("F:\\Student\\1Area.txt",'r')
lines = source.readlines()
L = [] #列表二维 国家行数 人口数
count = 1 #当前国家在文件中第count行
for line in lines:
line = line.rstrip('\n') #去除换行
.... #获取排名和面积
fNum = string.atof(number) #面积
L.append((count,ffNum)) #列表添加
count = count + 1
else:
print 'End While'
source.close()
列表排序
L.sort(lambda x,y:cmp(x[1],y[1]),reverse = True) #遍历过程 表示第i名 (文件第x行,面积y平方公里) #重点 L[i]输出列表 1 (46, 17075200.0) L[i][0]表示元组tuple第一个数 1 46 for i in range(len(L)): print (i+1), L[i]
获取面积字符串
line = line.rstrip('\n') #去除换行
start = line.find(r'V:')
end = line.find(r'平方公里')
number = line[start+2:end]
number = number.replace(',','') #去除','
#输出
line => C:国家 E:中华人民共和国 A:国土面积 V:9,634,057或9,736,000平方公里(世界第3/4名)
number => 9634057或9736000
最后同时需要处理各种字符串情况,如‘或'、‘万'要乘10000、删除‘[1]'等。更简单的方法是通过正则表达式或获取第一个非数字字符。
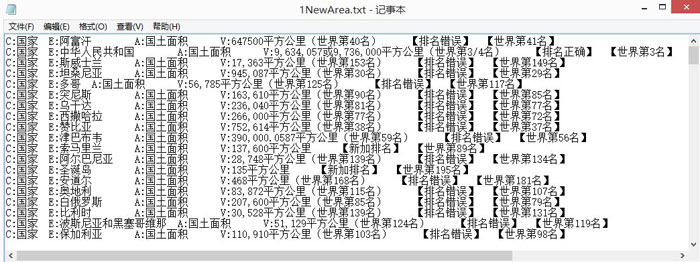
运行结果如下所示,排序后的txt和纠错txt:

代码如下:
# coding=utf-8
import time
import re
import os
import string
import sys
source = open("F:\\Student\\1Area.txt",'r')
lines = source.readlines()
count = 1
L = [] #列表二维 国家行数 人口数
'''''
第一部分 获取国土面积
'''
print 'Start!!!'
for line in lines:
line = line.rstrip('\n') #去除换行
start = line.find(r'V:')
end = line.find(r'平方公里')
number = line[start+2:end]
number = number.replace(',','') #去除','
fNum = 0.0
if '万' in number:
end = line.find(r'万')
newNum = line[start+2:end]
fNum = string.atof(newNum)*10000
else: #如何优化代码 全局变量
if '/' in number:
end = line.find(r'/')
newNum = line[start+2:end]
newNum = newNum.replace(',','')
fNum = string.atof(newNum)
elif '(' in number:
end = line.find(r'(')
newNum = line[start+2:end]
newNum = newNum.replace(',','')
fNum = string.atof(newNum)
elif '[' in number:
end = line.find(r'[')
newNum = line[start+2:end]
newNum = newNum.replace(',','')
fNum = string.atof(newNum)
elif '或' in number:
end = line.find(r'或')
newNum = line[start+2:end]
newNum = newNum.replace(',','')
fNum = string.atof(newNum)
elif ' ' in number:
end = line.find(r' ')
newNum = line[start+2:end]
newNum = newNum.replace(',','')
fNum = string.atof(newNum)
else:
fNum = string.atof(number)
#print line
#print number
#print fNum
L.append((count,fNum))
count = count + 1
else:
print 'End While'
source.close()
'''''
第二部分 从大到小排序
参看 http://blog.chinaunix.net/uid-20775448-id-4222915.html
'''
L.sort(lambda x,y:cmp(x[1],y[1]),reverse = True)
#print L
#遍历过程 表示第i名 (文件第x行,面积y平方公里)
#重点 L[i]输出列表 1 (46, 17075200.0) L[i][0]表示元组tuple第一个数 1 46
for i in range(len(L)):
print (i+1), L[i]
'''''
第三部分 读写文件
'''
source = open("F:\\Student\\1Area.txt",'r')
lines = source.readlines()
result = open("F:\\Student\\1NewArea.txt",'w')
count = 1
for line in lines:
line = line.rstrip('\n')
#获取列表L中排名位置pm
pm = 0
for i in range(len(L)):
if count==L[i][0]:
pm = i+1
break
#获取文件中名次
if '世界第' in line:
start = line.find(r'世界第')
end = line.find(r'名')
number = line[start+9:end]
if '/' in number: #防止中国第3/4名
end = line.find(r'/')
number = line[start+9:end]
if '包括海外' in number:
number = '41'
print number,pm,type(number),type(pm)
if string.atoi(number)==pm:
line = line + ' 【排名正确】 【世界第' + str(pm) + '名】'
result.write(line+'\n')
else:
line = line + ' 【排名错误】 【世界第' + str(pm) + '名】'
result.write(line+'\n')
else: #文件中没有排名
line = line + ' 【新加排名】 【世界第' + str(pm) + '名】'
result.write(line+'\n')
count = count + 1
else:
print 'End Sorted'
source.close()
result.close()
'''''
第四部分 输出一个排序好的文件 便于观察
'''
source = open("F:\\Student\\1Area.txt",'r')
lines = source.readlines()
result = open("F:\\Student\\1NewSortArea.txt",'w')
#i表示第i名 L[i][0]表示行数
pm = 0
for i in range(len(L)):
pm = L[i][0]
count = 1
for line in lines:
line = line.rstrip('\n')
if count==pm:
line = line + ' 【世界第' + str(i+1) + '名】'
result.write(line+'\n')
break
else:
count = count + 1
else:
print 'End Sorted Second'
source.close()
result.close()
最后希望文章对你有所帮助,文章主要通过讲述一个实际操作,帮你巩固学习liet列表的二维排序和字符串txt处理。如果文中有错误或不足之处,还请海涵~
以上就是本文的全部内容,希望本文的内容对大家的学习或者工作能带来一定的帮助,同时也希望多多支持!
加载全部内容