【Elasticsearch学习】之基础概念
xiaohuoshan 人气:2Elasticsearch是一个近实时的分布式搜索引起,其底层基于开源全文搜索库Lucene;Elasticsearch对Lucene进行分装,对外提供REST API 的操作接口。基于 ES,可以快速的搭建全文搜索引擎;除了搜索功能, ES还可以对数据进行分析:如日志分析、指标分析,同时还提供了机器学习功能。同时Elasticsearch有一个完整的生态圈,Elastic提供了数据可视化组件:kibana,数据抓取组件:logstash,filebeat。
ES相关概念
1.ES集群
Elasticsearch是一个分布式系统,具有高可用性及可扩展性,当集群中有节点停止或丢失时不会影响集群的服务以及数据的丢失;同时当访问量或数据量增加时可用采用横向扩展的方式,增加节点,将请求或数据分散到集群的各个节点上。不同的集群通过不同的名字来区分,集群默认的名字为“elasticsearch“,如果节点的集群名称一样,则这些节点组成为一个集群。
集群名的设置方式:
1).es配置文件中设置cluster.name:elasticsearch集群名
2).节点启动命令中指定集群名:-E cluster.name:elasticsearch集群名
2.ES节点
一个节点是一个ElasticSearch的实例,本质上是一个Java进程。
ES节点类型列表:
|
节点类型 |
节点作用 |
节点配置参数 |
默认值 |
|
Master Node |
处理创建、删除索引等操作,决定分片被分配到哪个节点,负责索引的创建删除,维护并更新集群状态。 |
node.master |
true |
|
Data Node |
可以保存数据的节点,处理与数据相关的操作,如索引的CRUD、搜索和聚合,数据节点的操作属于I/O、内存和CPU密集型操作。 |
node.data |
true |
|
Ingest Node |
提取节点,具有数据预处理的能力,可拦截Index或Bulk Api的请求,可对数据进行转换,并重新返回Index或Bulk Api,默认配置下,所有节点都是Ingest Node。 |
node.ingest |
true |
|
Coordinating Node |
协调节点,负责接受客户端的请求,并将请求分发到合适的节点,并将各节点返回的数据汇聚到一起。每个节点都默认是Coordinating Node。 |
无 |
设置master、data、ingest全为false |
|
Maching Learning Node |
机器学习节点,用于运行作业和处理机器学习API请求。 |
node.ml |
true,需要enablex-pack |
默认情况下一个节点承担了所有的节点角色。但是在生产环境中,建议根据数据量,写入及查询的吞吐量,选择合适的部署方式,最好将节点设置为单一角色。
单一角色节点配置方式:
|
节点类型 |
单一角色配置 |
机器配置 |
|
Master Node |
node.master: true node.data: false node.ingest: false |
低配置CPU、RAM、磁盘 |
|
Data Node |
node.master: false node.data: true node.ingest: false |
高配置CPU、RAM、磁盘 |
|
Ingest Node |
node.master: false node.data: false node.ingest: true |
低配置CPU、中等配置RAM、低配置磁盘 |
|
Coordinating Node |
node.master: false node.data: false node.ingest: false |
中高配置CPU、中高配置RAM、低配置磁盘 |
Master eligible Node(主节点候选节点)选主过程:
Master eligible Node互ping对方,节点Id小的会被选举为Master节点,其他节点加入集群时,不会承担Master节点的角色;当集群中选举出的Master节点丢失,会重新进行选举。
选主过程脑裂问题:
脑裂问题是分布式系统集群环境中必然会遇到的问题,会引起集群存在多个主节点,如当出现网络问题,一个节点和其他节点无法连接时,会发生脑裂问题。
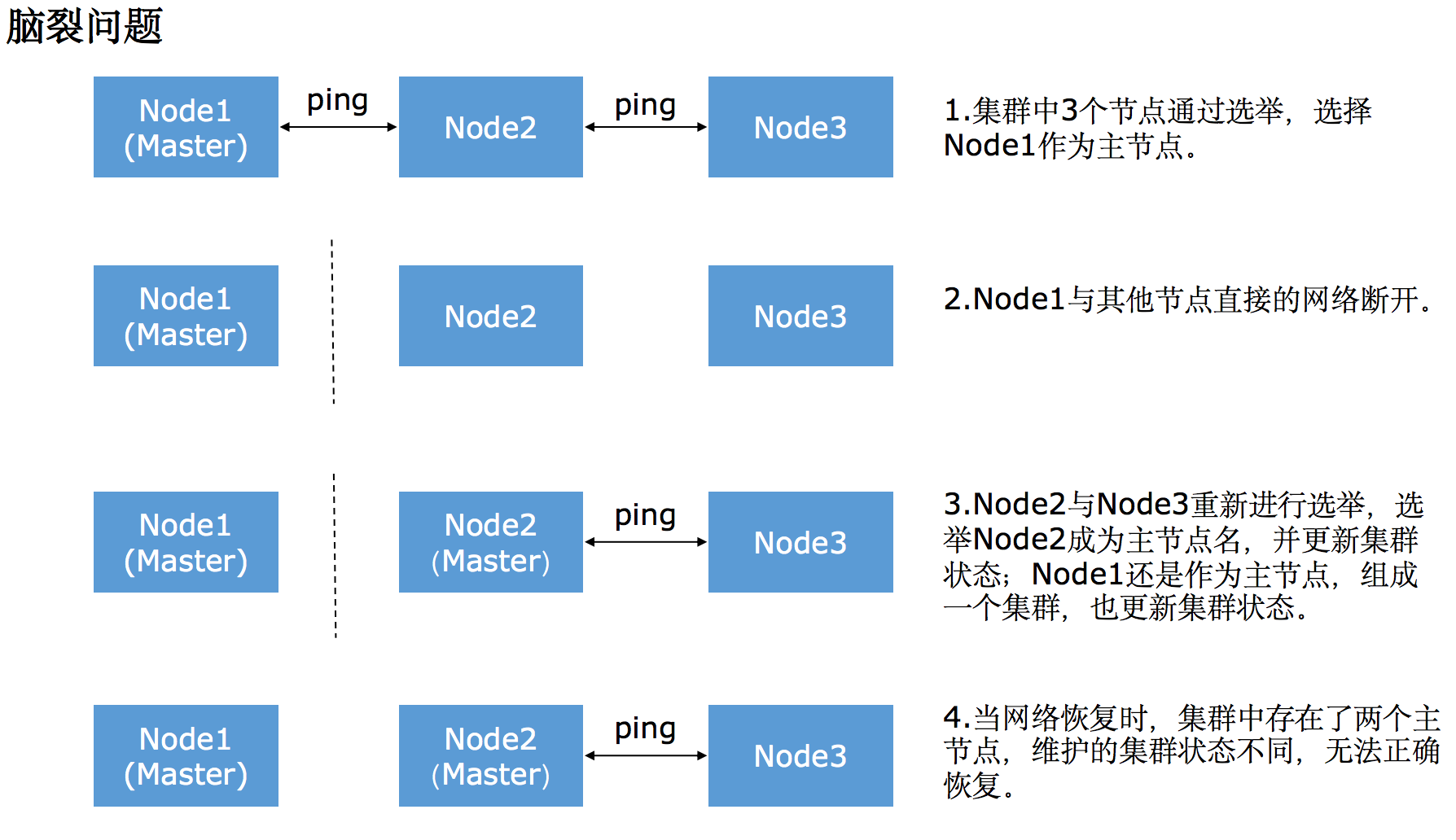
避免发送脑裂问题的方法:
1.限定集群节点的选举条件,设置quorum(仲裁),只有在Master eligible节点数大于quorum时,才能进行选举。
设置discovery.zen.minimum_master_nodes(默认为1):官方的推荐值是(N/2)+1,其中N是master eligible节点的数量。
2.设置discovery.zen.ping_timeout(默认值为3秒):默认情况下,如果master节点在3秒之内没有应答,则认为该节点宕掉,增加等待节点响应的时间,一定程度上会减少误判,降低脑裂发生的概率。
3.ES文档
文档是ES的最小单位,通常用JSON方式的数据结构表示,类似于数据库中的一条记录。文档具有以下特征:
1.自我包含,一篇文档同时包含字段和它们的取值。
2.层次型结构,文档中可以包含新的文档。
3.灵活的结构,不依赖于预先定义的模式,文档是无模式的,并非所有的文档都需要拥有相同的字段。
文档的元数据:_index:文档所属的索引名;_type:文档所属的类型名;_id文档的唯一id,_source:文档的原始json数据,_version文档的版本信 息,_score:文档的相关性打分。
4.ES类型
类型是文档的逻辑容器,类似于数据库中的表,类型在 Elasticsearch中表示一类相似的文档,每个类型中字段的定义称为映射。ES7.x已经将类型移除,7.x中一个索引只能有一个类型,默认为_doc。
5.ES映射
mapping映射, 就像数据库中的 schema ,定义索引中字段的名称,定义字段的数据类型(如 string, integer 或 date),设置字段倒排索引的相关配置。当 Elasticsearch 遇到文档中以前未遇到的字段,会使用dynamic mapping 来确定字段的数据类型,并自动把新的字段添加到类型映射。在实际生产中一般或禁用dynamic mapping,避免过多的字段导致cluster state占用过多,同时禁止自动创建索引的功能,创建索引时必须提供Mapping信息或者通过Index Template创建。
6.ES索引
索引是映射类型的容器,类似于数据库。
7.ES分片
一个分片是一个运行的Lucene的实例,是一个包含倒排索引的文件目录。一个ES索引由一个或多个主分片以及零个或多个副本分片组成,主分片数在索引创建是指定,后续不允许修改;副本分片主要用于解决数据高可用的问题,是主分片的拷贝,一定程度上提高服务的可读性。
分片的设定:生产环境中主分片数的设定,需要提前做好容量规划,因为主分片的数量是不可修改的。
分片数设置过小:无法通过增加节点实现水平扩展,单个分片的数据量太大,导致数据重新分片耗时;分片数设置过大:影响搜索结果的相关性打分,浪费资源,同时影响性能。
加载全部内容