负载均衡服务之HAProxy基础配置(三)
Linux-1874 人气:3前文我们聊到了haproxy的代理配置段中比较常用的配置指令的用法以及说明,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/12770930.html;今天我们来说说haproxy的状态页的配置,以及基于cookie实现的会话保持配置;
haproxy和nginx一样,都有一个状态页,这个页面对于运维人员来说是一个比较重要的页面,里面包含了haproxy代理的后端服务器的各种指标,通常我们要了解后端主机是否健康,当前负载情况,我们可以通过状态页去了解;haproxy的状态页配置起来很简单,用stats enable指令去开启即可;
stats enable:开启状态页;该指令可以配置在frontend或者listen或者backend,如果定义在backend中,那么我们必须要用前端去调用该banckend才能够看到状态页,所以通常我们都定义在listen中或者frontend中;具体示例如下
示例:定义在backend中
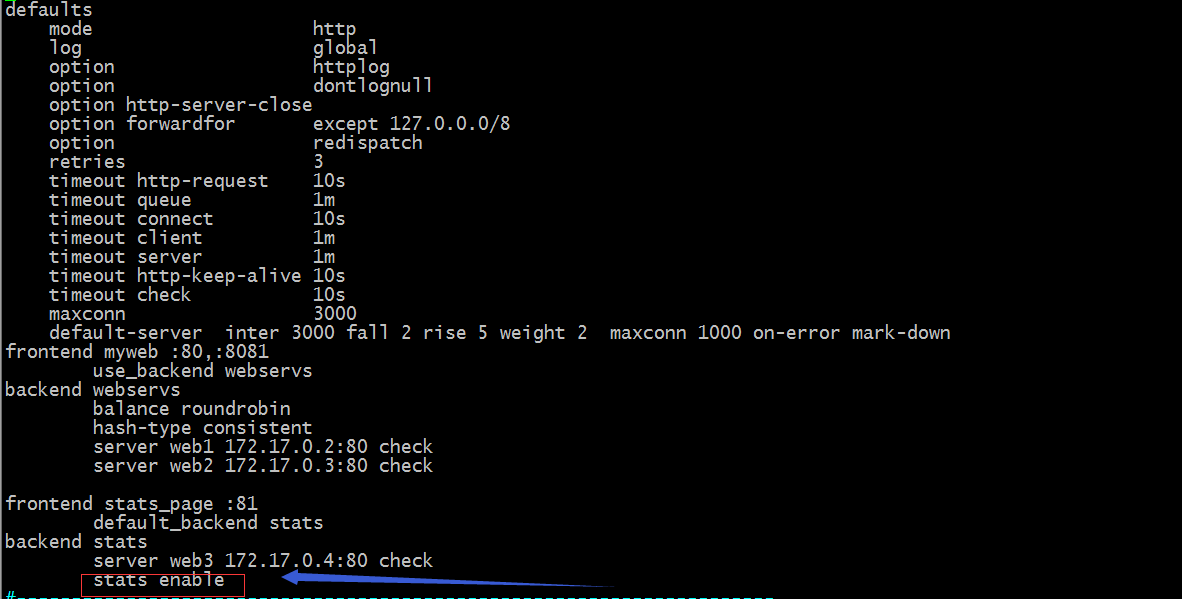
提示:定义在backend中必须要用frontend去调用该backend;
示例:定义在frontend中
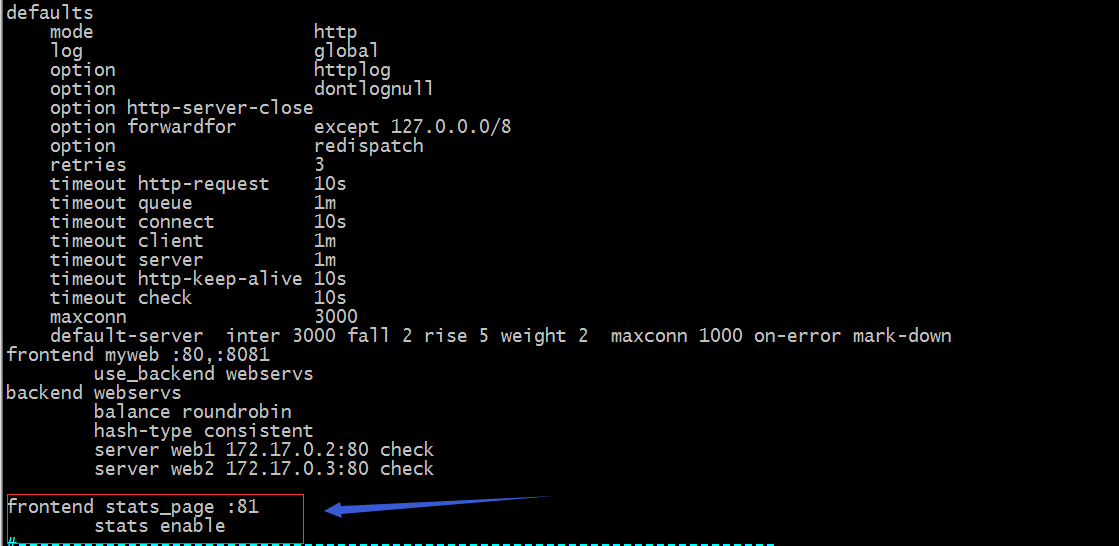
示例:定义在listen中

提示:以上三种方式都不影响访问状态页面,推荐配置在fonrtend或listen中;
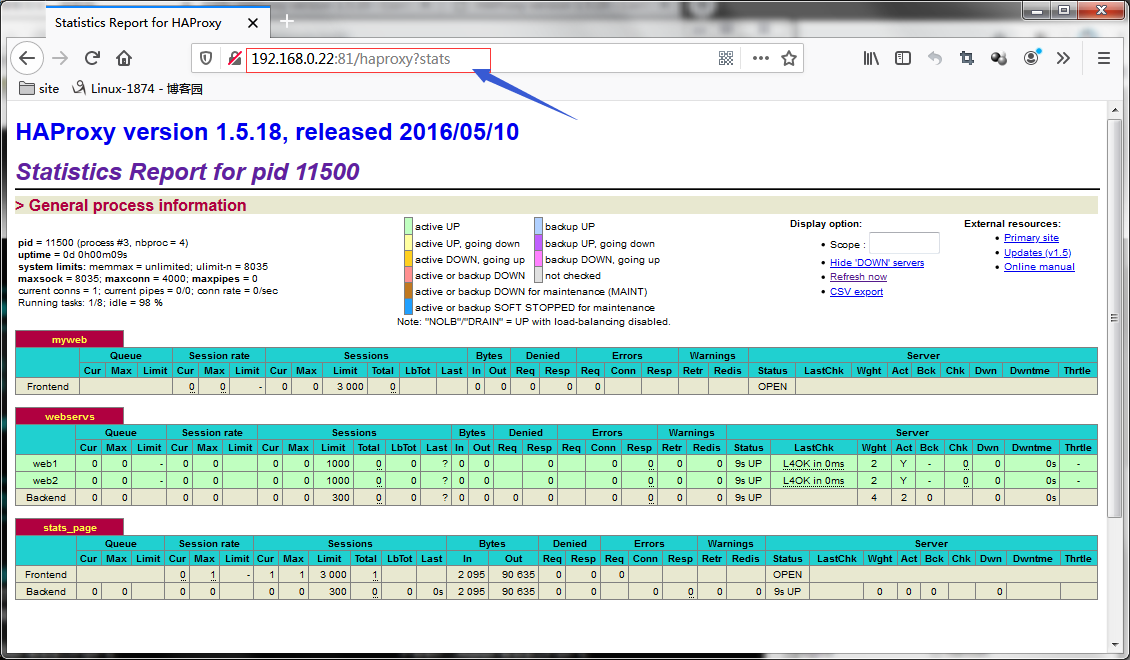
配置好stats enable参数后,重启haproxy,我们就可以通过浏览器访问haproxy所在主机的对应端口,我这里监听在81端口上,所以访问http://192.168.0.22:81/haporxy?stats就可以访问到状态页;如下
提示:之所以访问/haproxy?stats这个uri才能够访问到状态页,是因为我们没有在配置文件中明确指定把状态页绑定到那个uri上,默认情况不指定就是这个/haproxy?stats,当然我们如果要指定需要用stats uri <prefix>来指定对应的rui即可,如下
stats uri <prefix>:自定义stats page uri,默认值:/haproxy?stats
示例:更改状态也都uri

提示:以上配置表示访问状态页,的uri为/admin??status
测试:用浏览器访问81端口上的/admin??status这个uri看看是否能够访问到状态页?
提示:可以看到我们更改了uri后,默认的uri就不可以访问了,必须键入我们指定uri才可以被访问到,这在一定程度上降低了任何人访问状态页的风险;
stats auth <user>:<passwd>:配置状态页面认证的账号和密码,可使用多次;默认:no authentication,表示不验证
示例:配置状态页只允许admin用户访问并且密码为admin123.com

提示:以上配置表示开启状态页的认证功能,并且添加admin为用户名,admin123.com为密码
测试:现在我们访问状态页,看看是否需要验证?

提示:可以看到我们现在访问状态页,需要我们提供用户名和密码了,这相对于前面的配置,对于状态页的获取更加安全了;
stats realm <realm>:设置认证时弹出输入用户名密码的提示信息;
tats refresh <delay>:设置自动刷新时长;
示例:

提示:以上配置表示设定弹出输入用户名和密码的提示,设置自动刷新时长为每4秒自动刷新一次
测试:重启haproxy,看看对应配置是否生效

提示:可以看到我们配置的输入用户名和密码提示的字符串和自动刷新页都实现了,这里说一下,设定提示字符串需要把空白字符通过“\”转义,否则不会生效,加引号好像都不可以;
stats admin { if | unless } <cond>:启用stats page中的管理功能
示例:配置可以在状态页管理后端主机的权限;通常会通过后面的acl去控制,我这里为了演示方便,就用TRUE这个内置的ACL

提示:以上配置表示开启状态页管理功能,在条件为真的情况下,if TRUE表示一直为真,这意味着只要登录状态页,就有管理后端主机的权限;
测试:

提示:可以看到我们可以把后端主机的状态任意调整;
stats hide-version:隐藏版本
示例:隐藏haproxy状态也的版本信息

测试:登录状态页看看是否还有版本信息?
到此状态页的配置相关指令说完了,接下来我们来说说状态页里边的内容;

提示:pid = 11712 (process #4, nbproc = 4) #pid为当前pid号,process为当前进程号,nbproc和nbthread为一共多少进程和每个进程多少个线程(多线程需要在1.7以上的版本才支持);uptime = 0d 0h08m17s #启动了多长时间;system limits: memmax = unlimited; ulimit-n = 8035表示系统资源限制:内存/最大打开文件数/;maxsock = 8035; maxconn = 4000; maxpipes = 0表示最大socket连接数/单进程最大连接数/最大管道数maxpipes;current conns = 1; current pipes = 0/0; conn rate = 1/sec;表示当前连接数/当前管道数/当前连接速率;Running tasks: 1/8; idle = 100 %表示运行的任务/当前空闲率;
active UP:绿色表示在线服务器; backup UP:天蓝色表示标记为backup的服务器;active UP, going down:淡黄色表示监测未通过正在进入down过程;backup UP, going down:深紫色表示备份服务器正在进入down过程;active DOWN, going up:黄色表示down的服务器正在进入up过程;backup DOWN, going up:浅紫色表示备份服务器正在进入up过程;active or backup DOWN:粉红色表示在线的服务器或者是backup的服务器已经转换成了down状态; not checked:灰色表示标记为不监测的服务器(没有对它做健康状态监测);active or backup DOWN for maintenance (MAINT) :棕色表示active或者backup服务器认为下线的;active or backup SOFT STOPPED for maintenance :深蓝色表示active或者backup被认为软下线(人为将weight改成0);
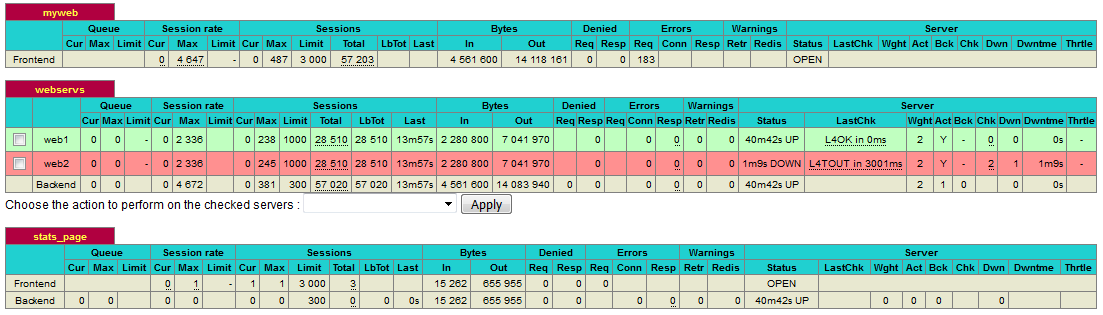
提示:session rate(每秒的连接会话信息)中的指标有cur,max,limit;其中cur表示每秒的当前会话数量;max表示每秒的最大会话数量;limit表示每秒新的会话限制量;sessions(会话信息),cur:表示当前会话量;max:表示最大会话量;limit: 表示限制会话量;Total:表示总共会话量;LBTot:表示选中一台服务器所用的总时间;Last:表示和服务器的持续连接时间;Bytes(流量统计):In表示网络的字节输入总量;Out表示网络的字节输出总量;Denied(拒绝统计信息):Req表示拒绝请求量;Resp表示拒绝恢复量;Errors(错误统计信息):Req表示错误请求量;conn表示错误连接量;Resp表示错误响应量;Warnings(警告统计信息):Retr表示重新尝试次数;Redis表示再次发送次数;Server(real server信息):Status表示后端server的状态,包含UP和DOWN;LastChk表示持续监测后端服务器的时间,其中L4OK表示基于4层tcp检查OK,L7OK表示基于7层应用层检查OK;Wght表示权重;Act表示活动链接数量;Bck表示备份的服务器数量;Chk表示心跳监测时间;Dwn表示后端服务器连接后都是DOWN的数量;Dwntme表示总的downtime时间;Thrtle表示server的状态;
了解了上面的状态页信息说明后,接下来我们来聊一聊haproxy基于cookie做会话保持;
首先我们要清楚什么叫cookie?它的主要作用是干什么的?众所周知http是无状态的,所谓无状态就是前一秒客户端访问服务端,后一秒同一客户端访问服务端,服务端是无法判断是不是同一客户端;就相当于服务端没有任何能力记住客户端;这样一来就存在一个问题;如果是一需要验证的网站,如果服务端不能辨别客户端身份,这意味着它不能够辨认到底是哪个客户端登录了,这样一来用户每刷新一次网页,服务端就会要求客户端重新登录;这很显然不是正常的逻辑;为了解决这样的问题,服务端每当客户端登录的时候,就会检查请求报文中是否携带cookie信息;如果没有携带cookie服务端在响应客户端的时候就会在响应报文中添加一个set-cookie的首部,意思是告诉客户端,这是你的cookie;客户端拿到服务端的响应的同时,它会自动的把服务端发来的cookie保存到一个特定的地方,下次客户端再次访问服务端的时候,就会把上次服务器发送过来的cookie信息带上去访问服务器;这样一来服务端收到客户端的请求,一看请求报文中的cookie信息,服务端就知道这个请求是那个用户发送过来的;这样一来服务端就通过cookie来辨认客户端了;这也是cookie的主要作用;通常情况下保存在客户端的叫cookie;在服务端一侧类似cookie的功能的东西我们叫session;通常两者通过某些信息来对应的;比如在客户端cookie信息里记录了服务端上的session的号码;当客户端再次访问服务端时,就会把cookie中的信息发送给服务端;服务端收到客户端发送过来的cookie就会去找对应的session;从而实现了,服务端知道对应客户端上次的操作;cookie是有时限性的;通常在有效的时间内去访问服务端,服务端都能够准确的辨认客户端;过期以后,服务端会重新给客户端发送cookie信息;
从上面的描述,我们不难理解,cookie就是用来让服务端辨识客户端的一种机制;而对于haproxy来讲,基于cookie来做会话保持的原理就是通过对后端服务器响应报文中的cookie信息中添加(或覆盖的方式)一个键值对,在客户端下次访问时,检查对应cookie首部的信息,从而让haproxy能够判断把该请求调度在那个后端服务器上;通常我们会在server上设置一个cookie的值,在listen或backend中设置一个cookie的键,明确说明以怎样的方式设置cookie的键;通过listen或backend中设置的cookie的键结合server后面的cookie的值组成的cookie信息,从而实现不同的cookie信息调度到不同的server上去;
示例:

提示:以上cookie COOKIE insert nocache表示在后端服务器响应报文首部中添加一个cookie的名称为COOKIE,而对应cookie的值就来源于后面server中的cookie的值;nocache表示该cookie不被共有缓存系统缓存;
测试:重启haproxy,用浏览器访问看看响应首部有什么变化
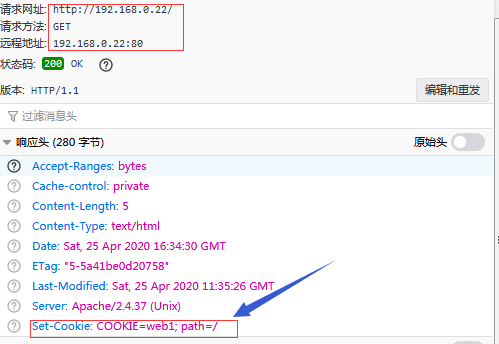
提示:可以看到当客户端第一次访问时,响应首部set-Cookie中就会设置一个COOKIE=web1的值;这个值就是我们刚才在haproxy配置的,从这个值上看,我们本次访问被调度到web1上了,之后我们再次访问时,就不会被调度到其他服务器上,在cookie过期之前始终都会被调度到web1上响应;这是因为下次我们访问时,会自动把这个cookie信息携带上;如下

提示:正是因为我们携带的cookie信息是COOKIE=web1和haproxy上的web1上的cookie的值相同,所以我们只要携带COOKIE=web1就会被调度到web1上;
用curl 模拟cookie信息访问不同后端服务器

提示:通过不同的cookie信息,就可以访问到不同后端server了;这样就实现了基于cookie信息来把相同cookie的请求发送给同一后端server的目的;实现了会话保持;
加载全部内容