Python读取和处理文件后缀为.sqlite的数据文件 Python读取和处理文件后缀为.sqlite的数据文件(实例讲解)
人气:0最近在弄一个项目分析的时候,看到有一个后缀为”.sqlite”的数据文件,由于以前没怎么接触过,就想着怎么用python来打开并进行数据分析与处理,于是稍微研究了一下。
SQLite是一款非常流行的关系型数据库,由于它非常轻盈,因此被大量应用程序采用。
像csv文件一样,SQLite可以将数据存储于单个数据文件,以便方便的分享给其他人员。许多编程语言都支持SQLite数据的处理,python语言也不例外。
sqlite3是python的一个标准库,可以用于处理SQLite数据库。
用sqlite3创建和操作数据库文件
对于数据库的SQL语句,本文会用到最基础的SQL语句,应该不影响阅读。如果想进一步了解,可参考如下网址:
http://www.w3school.com.cn/sql/index.asp
下面,我们来应用salite3模块来创建SQLite数据文件,以及进行数据读写操作。
主要的步骤如下:
与数据库建立连接,创建数据库文件(.sqlite文件)
创建游标(cursor)
创建数据表(table)
向数据表中插入数据
查询数据
演示代码如下:
import sqlite3
with sqlite3.connect('test_database.sqlite') as con:
c = con.cursor()
c.execute('''CREATE TABLE test_table
(date text, city text, value real)''')
for table in c.execute("SELECT name FROM sqlite_master WHERE type='table'"):
print("Table", table[0])
c.execute('''INSERT INTO test_table VALUES
('2017-6-25', 'bj', 100)''')
c.execute('''INSERT INTO test_table VALUES
('2017-6-25', 'pydataroad', 150)''')
c.execute("SELECT * FROM test_table")
print(c.fetchall())
Table test_table
[('2017-6-25', 'bj', 100.0), ('2017-6-25', 'pydataroad', 150.0)]
关于SQLite数据库中数据的可视化预览,有很多的工具可以实现,我这里使用的是SQLite Studio,是一个免费使用的工具,不需要安装,下载下来就可以使用,有兴趣的同学可以参考下面的链接。
https://sqlitestudio.pl/index.rvt?act=download
数据预览的效果如下:
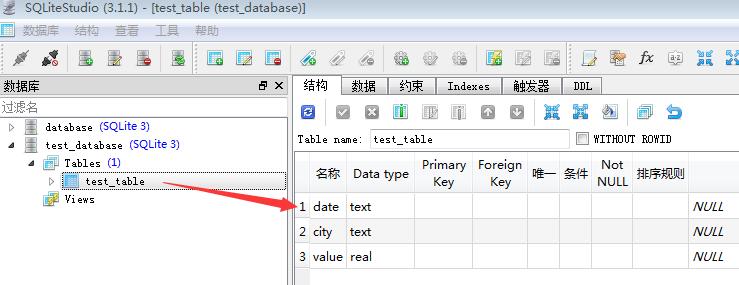
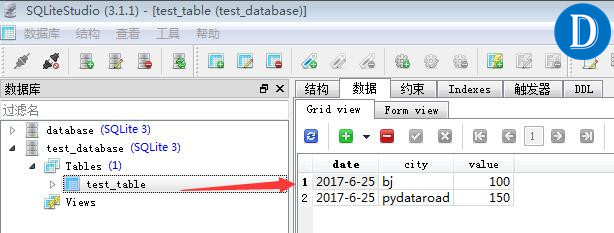
用pandas来读取sqlite数据文件
从上面代码的运行结果可以看出,数据查询的结果是一个由tuple组成的list。python的list数据在进行进一步的数据处理与分析时,可能会不太方便。可以想象一下,假设如果数据库的表格中一共有100万行或者更多数据,从list中循环遍历获取数据,效率会比较低。
这时,我们可以考虑用pandas提供的函数来从SQLite数据库文件中读取相关数据信息,并保存在DataFrame中,方便后续进一步处理。
Pandas提供了两个函数,均可以读取后缀为“.sqlite”数据文件的信息。
read_sql()
read_sql_query()
import pandas as pd
with sqlite3.connect('test_database.sqlite') as con:
# read_sql_query和read_sql都能通过SQL语句从数据库文件中获取数据信息
df = pd.read_sql_query("SELECT * FROM test_table", con=con)
# df = pd.read_sql("SELECT * FROM test_table", con=con)
print(df.shape)
print(df.dtypes)
print(df.head())
(2, 3)
date object
city object
value float64
dtype: object
date city value
0 2017-6-25 bj 100.0
1 2017-6-25 pydataroad 150.0
以上这篇Python读取和处理文件后缀为.sqlite的数据文件(实例讲解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
加载全部内容