💕《给产品经理讲JVM》:垃圾收集器
Vi的技术博客 人气:0前言
在上篇中,我们把 JVM 中的垃圾收集算法有了一个大概的了解,又是一个阴雨连绵的周末,宅在家里的我们又开始了新一轮的学习:
产品大大:上周末我们说了垃圾收集算法,下面是不是要讲一下这些算法的应用呢?
我:当然,如果说垃圾收集算法是打狗棒法,那么垃圾收集器就是历届的丐帮帮主们,不同的帮主领悟到的自然也就不同,我先对这些帮主进行一个简单的介绍,看图!
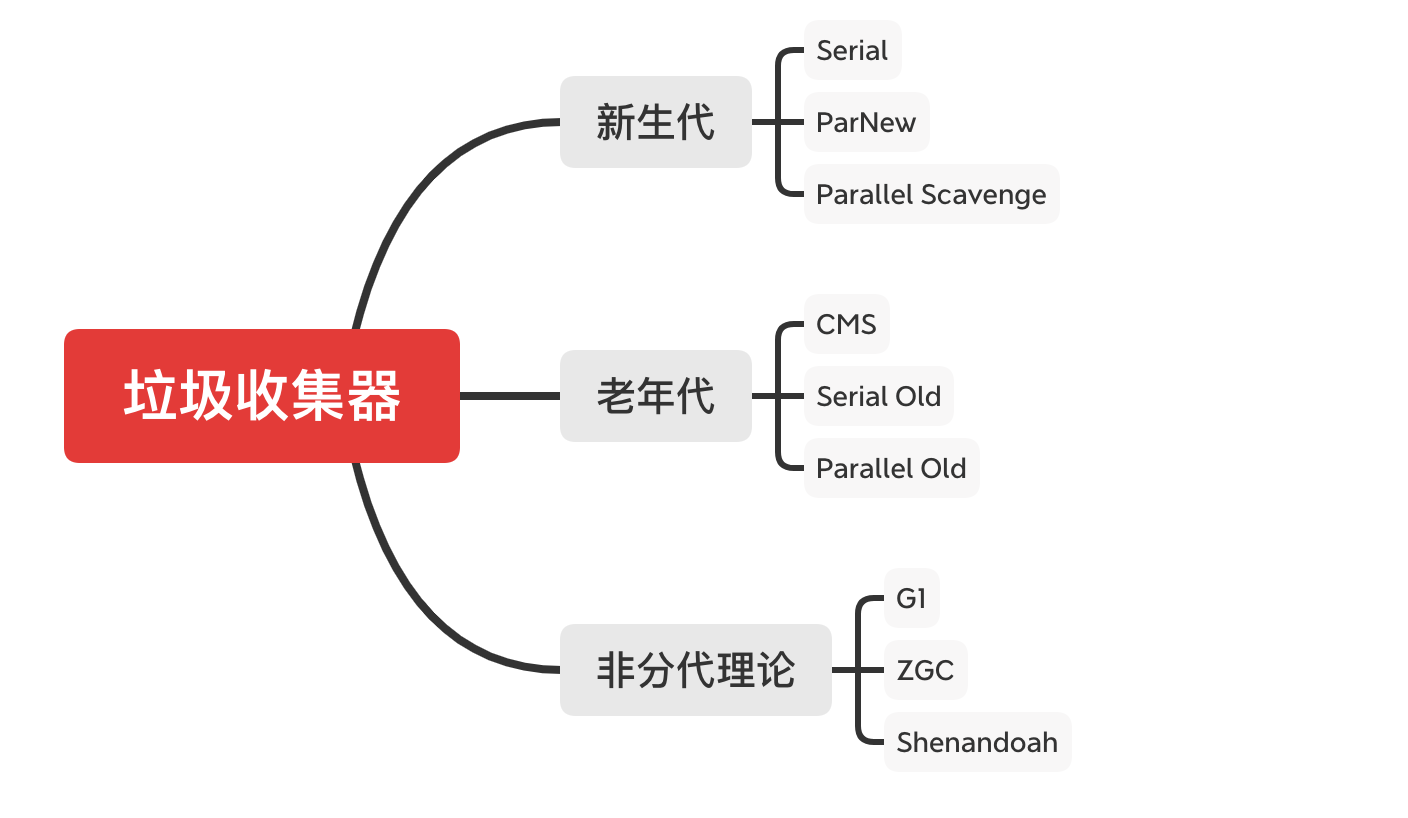
我:我从回收的区域去对垃圾收集器进行了一个简单的划分,大致可以分为这样九种,下面就且听我为你一一道来。
产品大大:好哒
Serial 收集器
我:下面要说的就是一款非常古老的「新生代收集器」—— Serial 收集器,它的历史可以追溯到 JDK 还是以1.x命名的时代(大概时间在我五岁的时候?
产品大大:从 Serial 这个名字上可以看的出,这应该是一款串行(单线程)收集器,对吧?
我:没错,Serial 收集器是一款单线程的收集器,它的收集过程也很简单(如下图),虽然它只会使用一个处理器或一条线程去收集垃圾,但是这里我不喜欢称之为单线程收集器,它更适合「串行」这个词,因为它在进行 GC 的时候,必须暂停掉其他的线程(Stop The World,STW)

产品大大:那么这个收集器是不是已经废弃掉了啊,仅仅停留在历史中,作为一个值得去纪念的东西?
我:其实也并不能这么说,虽然它简单,但是简单有简单的好处,因为单线程,所以没有切换线程的资源开销,所以在单核CPU的环境下,它的表现反而会显得更加优秀,只能说是没有最好的收集器,只有最适合的收集器~
产品大大:酱紫哦,那么我们来说下一个收集器吧,这个我已经有一个大概的了解了~
ParNew 收集器
我:下一个收集器啊,叫做 ParNew 收集器,这个收集器和上面我们所说的 Serial 收集器基本上一模一样,除了它会启动多个GC线程去进行垃圾的收集(并行收集)
产品大大:并行?我只听过并发哦。。
我:并发指的是工作线程与垃圾收集线程之间的关系,而并行指的是多条垃圾收集线程之间的关系,这两个的概念是不一样的,并行的时候,工作线程处于等待状态。而并发的时候,工作线程处于活动状态。
产品大大:那么它和 Serial 收集器比起来有什么区别呢?
我:在单线程环境下,Serial 的 GC 效率是要优于它的,但是在多线程环境下,它对于垃圾收集时系统资源的高效利用还是很是颇有成效的。
产品大大:那么它现在还好嘛~
我:它在 HotSpot 虚拟机中是第一款退出了历史舞台的收集器,在 JDK 9 的时候,把它等于并入了 CMS 收集器中,而且来一个小小的剧透。。在 JDK 14 中 CMS也被删除掉,从辉煌到落幕,正式结束了在服务端称霸的生涯。
产品大大:好可怜,呜呜呜呜
我:???停止你的表演,我们继续
Parallel Scavenge 收集器
我:下面要说的这个也是一个新生代的收集器——Parallel Scavenge 收集器,从表面上来看,它好像和 ParNew 收集器之间没有太大的区别,但是为什么我们要它单独列出来呢?
产品大大:这是在考我嘛?
我:说说看咯
产品大大:虽然这俩货看起来差不多,但是我觉得就像微信和 QQ 的区别一样,这俩货虽然看起来也是很类似,但是它们的区别就在于侧重点不一样,细分市场的不同会让它们虽然有所冲突,但是不会有你死我活的那样恶性的竞争关系,而更偏向于互补,阴阳相生。
我:说的真好,这嘴真能忽悠,怪不得天天开发写不完的需求(默默碎碎念一百句
我:它更侧重于吞吐量,吞吐量的意思是什么呢,它并不是非常 Care 每次STW的间隔时间,而是更看重对资源的一个整体利用率。
产品大大:那么我们如何去控制吞吐量呢?
我:有这么两个参数:-XX:MaxGCPauseMillis 和 -XX:GCTimeRatio。第一个是用来控制每次 STW 的时间,第二个是直接设置吞吐量的大小,还有一个参数:-XX:+UseAdaptiveSizePolicy,这个参数是一个布尔值,如果开启这个开关,虚拟机会自动的去调节前两个参数的大小,可以达到一个自适应的效果。这个参数也是一个具有Parallel Scavenge特色的,区别于 ParNew 的所在。
Serial Old 收集器
我:新生代的收集到这就告一段落了,下面说一下老年代的三个收集器,第一个是 Serial 收集器的老年代版本——Serial Old 收集器,如其名那样,它和它的新生代收集器—— Serial 收集器一样,是一个单线程的收集器,和新生代的 Serial 不同,它采用的是标记整理算法。
产品大大:这情侣 id 啧啧,我已经想象到了看到这俩名字的程序猿,冷冷的狗粮往嘴里胡乱的塞
我:咳咳,虽然这俩是情侣 id ,但是它可以和 Parallel Scavenge 组cp,而且它还是 CMS 的一个备胎。。
产品大大:??hetui,男人没有一个好东西,下一个吧下一个
我:??(关我毛事儿。。人在家中坐,锅从天上来

Parallel Old 收集器
我:好了,我们不提刚刚的那个小插曲,下面我们来说一下 Parellel Old 这款老年代的收集器,看这个名字,我们可以知道这款收集器和 Parellel Scavenge 收集器是一家子,它正是 Parallel Scanvenge 的老年代版本,在它出现之前,Serial Old 一直充当着他的角色与 Parallel Scanvenge 进行配合,但是它出来之后,算是把那个小三给赶走了,后来居上的成为了原配。
产品大大:原来这个就是原配哦,也就是说如果我们看重吞吐量的话,就可以使用它们的 ‘夫妻’ 组合去完成(夫妻搭配,干活不累
我:是这样的,没错呢,下面我们来介绍一个重量级的收集器,它在 JVM 的垃圾收集器历史中划下了一个浓墨重彩的一笔。
产品大大:好啊好啊~
CMS 收集器
我:下面要介绍的这款收集器叫做—— CMS(Concurrent Mark Sweep)收集器,为什么说它是一款划时代意义的收集器呢,它是第一款将并发这个词诠释出意义并获得大范围的应用和推广的收集器,就是说,它可以做到一边丢垃圾,一边收垃圾。
产品大大:那么它的运行流程是什么呢,一定和其他有所不同吧~
我:看图~

我:首先由它的名字我们可以知道,它是基于标记——清除算法的,而它分为了四步走:
初始标记(这一过程耗时很短,只是标记一下GC Roots 能直接关联到的对象 并发标记(和用户线程一起运行,虽然耗时较长,但是不会造成STW 重新标记(修正在并发标记过程中的变动,耗时比初始长,但是远小于并发标记时间 并发清除(和用户线程一起运行,进行并发的清除
产品大大:那么 CMS 既然这么优秀,是不是我们一直都在使用这个呢?
我:并不然,一般划时代的下场都不会很好,因为它存在了三个问题:
对处理器的资源耗费较大,比较敏感 在GC的过程中,容易产生新的垃圾,浮动垃圾的产生如果导致并发失败,就会启用Serial Old来进行,这样就很慢很慢了 由于它是基于标记——清除算法实现的,所以会产生一些碎片空间,当碎片空间不足以放下对象的时候,就会触发 Full GC
产品大大:那么它现在这么样了
我:它啊,在 JDK 9 中被标记为Deprecate,而在最新更新的 JDK 14 中彻底的退出了历史的舞台,此情可待成追忆,只是当时已惘然啊~


我:下面我来介绍一款当下我们在用的收集器吧,也就是鼎鼎大名的 G1 收集器 ~
G1 收集器
我:Garbage First 也称 G1,冷酷的外表,无情的性能,超前的设计,简直就是一个木得感情的杀手(biu~
产品大大:说人话(手动微笑脸

我: G1 收集器是又一个里程碑意义的收集器,它开创了收集器面向局部收集的设计思路和基于Region的内存布局方式。
产品大大:此话怎解?
我:在我们之前所了解的收集器中,我们都是基于内存分代理论,把内存区域分为老年代和新生代,不同区域的采用不同的收集器去完成,而G1颠覆了这个概念,它不再去区分所谓的老年代和新生代,而是面向全堆进行收集,把 Java 堆划分为多个大小相等的独立区域,在进行垃圾回收的时候,会将需要回收的区域组合成回收集(Collection Set),哪块儿内存存放的垃圾数量最多,回收收益最大,优先去回收那些收益最大的区域,这也是Garbage First 这个名字的由来~
产品大大:那么我有一个疑问,如果对象的大小过于庞大,一个区域无法放下这个对象的时候该怎么办呢?
我:首先说明一下,虽然化整为零,但是仍然保存了老年代和新生代的概念,只不过这一块儿不是一个固定的区域了,而是一系列区域的动态集合,而这些大对象会被存放在 N 个连续的 Humongous Region 中,这些 Region 被视为老年代的一部分~
产品大大:那么和CMS相比起来,它的优势在于什么地方呢?
我:相对于CMS来说,最根本的一点,CMS是基于「标记——清除」算法实现的,而 G1 是通过「标记——整理」算法,每个区域之间又是通过「标记——复制」算法,这样的做法不会产生大量的内存碎片,可以使程序更加长时间的稳定运行,省的因为出现大对象无法分配而去进行下一次 Full GC。
产品大大:那么 G1 的缺点其实也很明显,它的功能很强大,带来的是对内存的负荷和对CPU的压力,毕竟世界上没有免费的午餐~
我:没错呢,因为在处理跨 Region 引用的时候使用的卡表技术,标记——复制算法这些都会导致它的内存压力要比CMS高20%,但是不论是对于它所带来的提升和红利来说,还是对于一代新人换旧人的历史发展来说,我们无疑是更倾向于去选择 G1 的~
产品大大:嗯呐,下面还有嘛~
我:下面简单的介绍两款实验过程中的收集器吧,虽然不知道未来它们会怎么样,但是它们就像当年的 G1 的一样,未来可期~
产品大大:好的呢~

Shenandoah 收集器 && ZGC 收集器
我:下面简单介绍一下这两款低延迟收集器,在我们的收集器中,一般主要评判的标准有三种:内存占用。吞吐量。延迟,在这三者之中,我们最多可以在两个之间做到极致,随着我们计算机硬件的发展,内存占用慢慢没有那么重要,人们越来越看重延迟,所以低延迟就称为我们追求的目标,而这两款收集器就是为了达到GC只需 10ms 的目标去的~
产品大大:那么它们到底是什么呢?
我:一个叫做Shenandoah收集器,一个叫做ZGC收集器,它们两个功能非常相似,只不过 ZGC 是亲生的,而Shenandoah是抱养的,它们都可以看作是 G1 的继承者,G1 在一定程度上也对这两个代码有所借鉴和改进。
我:ZGC 收集器是一款基于 Region 内存布局的,(暂时)不设分代的,使用了读屏障,染色指针和内存多重映射等技术来实现可并发的标记——整理算法的,以低延迟为首要目标的一款垃圾收集器。它的技术实现,我这里就不再详细去讲了,等到它应用的比较广泛的时候,再去研究也不晚~

产品大大:行吧~ 那我们今天到这里,下次我们继续,我们现在出去撸串~
加载全部内容