进程线程协程 老生常谈进程线程协程那些事儿
人气:0一、进程与线程
1.进程
我们电脑的应用程序,都是进程,假设我们用的电脑是单核的,cpu同时只能执行一个进程。当程序出于I/O阻塞的时候,CPU如果和程序一起等待,那就太浪费了,cpu会去执行其他的程序,此时就涉及到切换,切换前要保存上一个程序运行的状态,才能恢复,所以就需要有个东西来记录这个东西,就可以引出进程的概念了。
进程就是一个程序在一个数据集上的一次动态执行过程。进程由程序,数据集,进程控制块三部分组成。程序用来描述进程哪些功能以及如何完成;数据集是程序执行过程中所使用的资源;进程控制块用来保存程序运行的状态
2.线程
一个进程中可以开多个线程,为什么要有进程,而不做成线程呢?因为一个程序中,线程共享一套数据,如果都做成进程,每个进程独占一块内存,那这套数据就要复制好几份给每个程序,不合理,所以有了线程。
线程又叫轻量级进程,是一个基本的cpu执行单元,也是程序执行过程中的最小单元。一个进程最少也会有一个主线程,在主线程中通过threading模块,在开子线程
3.进程线程的关系
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程
(2)资源分配给进程,进程是程序的主体,同一进程的所有线程共享该进程的所有资源
(3)cpu分配给线程,即真正在cpu上运行的是线程
(4)线程是最小的执行单元,进程是最小的资源管理单元
4.并行和并发
并行处理是指计算机系统中能同时执行两个或多个任务的计算方法,并行处理可同时工作于同一程序的不同方面
并发处理是同一时间段内有几个程序都在一个cpu中处于运行状态,但任一时刻只有一个程序在cpu上运行。
并发的重点在于有处理多个任务的能力,不一定要同时;而并行的重点在于就是有同时处理多个任务的能力。并行是并发的子集
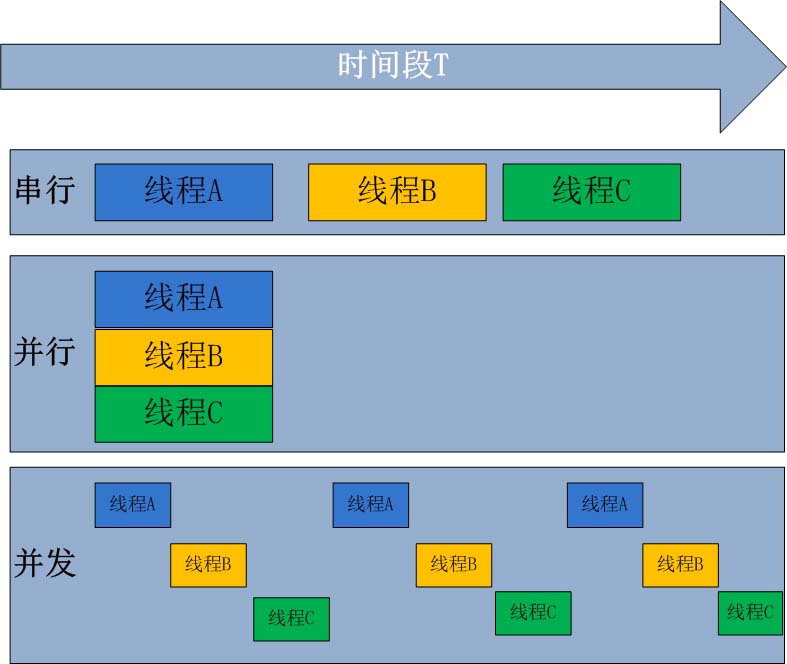
以上所说的是相对于所有语言来说的,Python的特殊之处在于Python有一把GIL锁,这把锁限制了同一时间内一个进程只能有一个线程能使用cpu
二、threading模块
这个模块的功能就是创建新的线程,有两种创建线程的方法:
1.直接创建
import threading
import time
def foo(n):
print('>>>>>>>>>>>>>>>%s'%n)
time.sleep(3)
print('tread 1')
t1=threading.Thread(target=foo,args=(2,))
#arg后面一定是元组,t1就是创建的子线程对象
t1.start()#把子进程运行起来
print('ending')
上面的代码就是在主线程中创建了一个子线程
运行结果是:先打印>>>>>>>>>>>>>2,在打印ending,然后等待3秒后打印thread 1
2.另一种方式是通过继承类创建线程对象
import threading
import time
class MyThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
print('ok')
time.sleep(2)
print('end')
t1=MyThread()#创建线程对象
t1.start()#激活线程对象
print('end again')
3.join()方法
这个方法的作用是:在子线程完成运行之前,这个子线程的父线程将一直等待子线程运行完再运行
import threading
import time
def foo(n):
print('>>>>>>>>>>>>>>>%s'%n)
time.sleep(n)
print('tread 1')
def bar(n):
print('>>>>>>>>>>>>>>>>%s'%n)
time.sleep(n)
print('thread 2')
s=time.time()
t1=threading.Thread(target=foo,args=(2,))
t1.start()#把子进程运行起来
t2=threading.Thread(target=bar,args=(5,))
t2.start()
t1.join() #只是会阻挡主线程运行,跟t2没关系
t2.join()
print(time.time()-s)
print('ending')
'''
运行结果:
>>>>>>>>>>>>>>>2
>>>>>>>>>>>>>>>>5
tread 1
thread 2
5.001286268234253
ending
'''
4.setDaemon()方法
这个方法的作用是把线程声明为守护线程,必须在start()方法调用之前设置。
默认情况下,主线程运行完会检查子线程是否完成,如果未完成,那么主线程会等待子线程完成后再退出。但是如果主线程完成后不用管子线程是否运行完都退出,就要设置setDaemon(True)
import threading
import time
class MyThread(threading.Thread):
def __init__(self):
threading.Thread.__init__(self)
def run(self):
print('ok')
time.sleep(2)
print('end')
t1=MyThread()#创建线程对象
t1.setDaemon(True)
t1.start()#激活线程对象
print('end again')
#运行结果是马上打印ok和 end again
#然后程序终止,不会打印end
主线程默认是非守护线程,子线程都是继承的主线程,所以默认也都是非守护线程
5.其他方法
isAlive(): 返回线程是否处于活动中
getName(): 返回线程名
setName(): 设置线程名
threading.currentThread():返回当前的线程变量
threading.enumerate():返回一个包含正在运行的线程的列表
threading.activeCount():返回正在运行的线程数量
三、各种锁
1.同步锁(用户锁,互斥锁)
先来看一个例子:
需求是有一个全局变量的值是100,我们开100个线程,每个线程执行的操作是对这个全局变量减一,最后import threading
import threading import time def sub(): global num temp=num num=temp-1 time.sleep(2) num=100 l=[]for i in range(100): t=threading.Thread(target=sub,args=()) t.start() l.append(t) for i in l: i.join() print(num)
好像一切正常,现在我们改动一下,在sub函数的temp=num,和num=temp-1 中间,加一个time.sleep(0.1),会发现出问题了,结果变成两秒后打印99了,改成time.sleep(0.0001)呢,结果不确定了,但都是90几,这是怎么回事呢?
这就要说到Python里的那把GIL锁了,我们来捋一捋:
首次定义一个全局变量num=100,然后开辟了100个子线程,但是Python的那把GIL锁限制了同一时刻只能有一个线程使用cpu,所以这100个线程是处于抢这把锁的状态,谁抢到了,谁就可以运行自己的代码。在最开始的情况下,每个线程抢到cpu,马上执行了对全局变量减一的操作,所以不会出现问题。但是我们改动后,在全局变量减一之前,让他睡了0.1秒,程序睡着了,cpu可不能一直等着这个线程,当这个线程处于I/O阻塞的时候,其他线程就又可以抢cpu了,所以其他线程抢到了,开始执行代码,要知道0.1秒对于cpu的运行来说已经很长时间了,这段时间足够让第一个线程还没睡醒的时候,其他线程都抢到过cpu一次了。他们拿到的num都是100,等他们醒来后,执行的操作都是100-1,所以最后结果是99.同样的道理,如果睡的时间短一点,变成0.001,可能情况就是当第91个线程第一次抢到cpu的时候,第一个线程已经睡醒了,并修改了全局变量。所以这第91个线程拿到的全局变量就是99,然后第二个第三个线程陆续醒过来,分别修改了全局变量,所以最后结果就是一个不可知的数了。一张图看懂这个过程
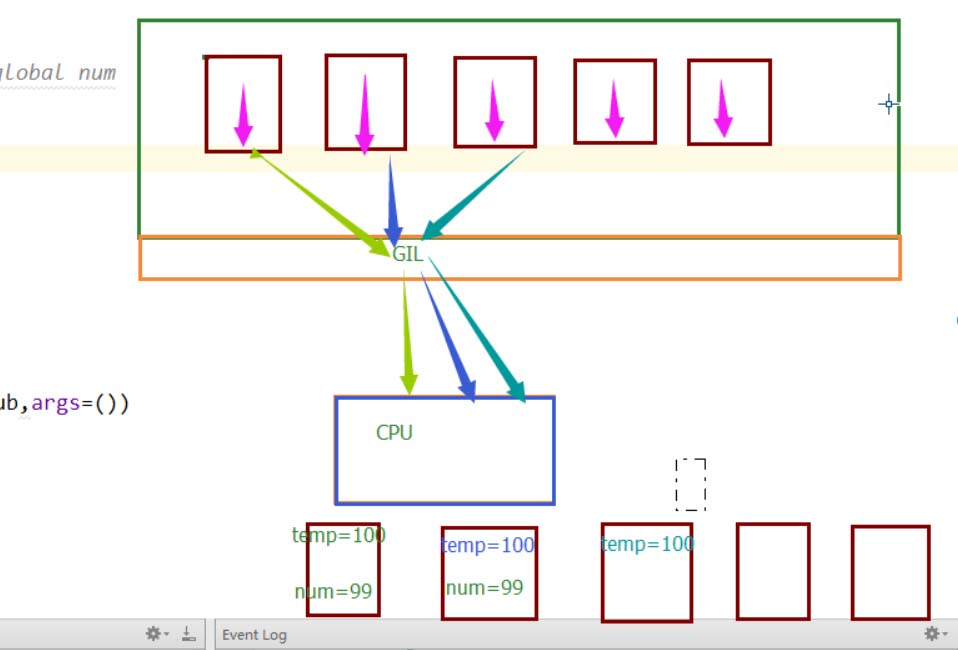
这就是线程安全问题,只要涉及到线程,都会有这个问题。解决办法就是加锁
我们在全局加一把锁,用锁把涉及到数据运算的操作锁起来,就把这段代码变成串行的了,上代码:
import threading import time def sub(): global num lock.acquire()#获取锁 temp=num time.sleep(0.001) num=temp-1 lock.release()#释放锁 time.sleep(2) num=100 l=[] lock=threading.Lock() for i in range(100): t=threading.Thread(target=sub,args=()) t.start() l.append(t) for i in l: i.join() print(num)
获取这把锁之后,必须释放掉才能再次被获取。这把锁就叫用户锁
2.死锁与递归锁
死锁就是两个及以上进程或线程在执行过程中,因相互制约造成的一种互相等待的现象,若无外力作用,他们将永远卡在那里。举个例子:
死锁示例
import threading,time
class MyThread(threading.Thread):
def __init(self):
threading.Thread.__init__(self)
def run(self):
self.foo()
self.bar()
def foo(self):
LockA.acquire()
print('i am %s GET LOCKA------%s'%(self.name,time.ctime()))
#每个线程有个默认的名字,self.name就获取这个名字
LockB.acquire()
print('i am %s GET LOCKB-----%s'%(self.name,time.ctime()))
LockB.release()
time.sleep(1)
LockA.release()
def bar(self):#与
LockB.acquire()
print('i am %s GET LOCKB------%s'%(self.name,time.ctime()))
#每个线程有个默认的名字,self.name就获取这个名字
LockA.acquire()
print('i am %s GET LOCKA-----%s'%(self.name,time.ctime()))
LockA.release()
LockB.release()
LockA=threading.Lock()
LockB=threading.Lock()
for i in range(10):
t=MyThread()
t.start()
#运行结果:
i am Thread-1 GET LOCKA------Sun Jul 23 11:25:48 2017
i am Thread-1 GET LOCKB-----Sun Jul 23 11:25:48 2017
i am Thread-1 GET LOCKB------Sun Jul 23 11:25:49 2017
i am Thread-2 GET LOCKA------Sun Jul 23 11:25:49 2017
然后就卡住了
上面这个例子中,线程2在等待线程1释放B锁,线程1在等待线程2释放A锁,互相制约
我们在用互斥锁的时候,一旦用的锁多了,很容易就出现这种问题
在Python中,为了解决这个问题,Python提供了一个叫可重用锁(RLock)的概念,这个锁内部维护着一个lock和一个counter变量,counter记录了acquire的次数,每次acquire,counter就加1,每次release,counter就减1,只有counter的值为0的时候,其他线程才能获得资源,下面用RLock替换Lock,在运行就不会卡住了:
递归锁示例
import threading,time
class MyThread(threading.Thread):
def __init(self):
threading.Thread.__init__(self)
def run(self):
self.foo()
self.bar()
def foo(self):
RLock.acquire()
print('i am %s GET LOCKA------%s'%(self.name,time.ctime()))
#每个线程有个默认的名字,self.name就获取这个名字
RLock.acquire()
print('i am %s GET LOCKB-----%s'%(self.name,time.ctime()))
RLock.release()
time.sleep(1)
RLock.release()
def bar(self):#与
RLock.acquire()
print('i am %s GET LOCKB------%s'%(self.name,time.ctime()))
#每个线程有个默认的名字,self.name就获取这个名字
RLock.acquire()
print('i am %s GET LOCKA-----%s'%(self.name,time.ctime()))
RLock.release()
RLock.release()
LockA=threading.Lock()
LockB=threading.Lock()
RLock=threading.RLock()
for i in range(10):
t=MyThread()
t.start()
这把锁又叫递归锁
3.Semaphore(信号量)
这也是一把锁,可以指定有几个线程可以同时获得这把锁,最多是5个(前面说的互斥锁只能有一个线程获得)
import threading
import time
semaphore=threading.Semaphore(5)
def foo():
semaphore.acquire()
time.sleep(2)
print('ok')
semaphore.release()
for i in range(10):
t=threading.Thread(target=foo,args=())
t.start()
运行结果是每隔两秒就打印5个ok
4.Event对象
线程的运行是独立的,如果线程间需要通信,或者说某个线程需要根据一个线程的状态来执行下一步的操作,就需要用到Event对象。可以把Event对象看作是一个标志位,默认值为假,如果一个线程等待Event对象,而此时Event对象中的标志位为假,那么这个线程就会一直等待,直至标志位为真,为真以后,所有等待Event对象的线程将被唤醒
event.isSet():返回event的状态值; event.wait():如果 event.isSet()==False将阻塞线程; event.set(): 设置event的状态值为True,所有阻塞池的线程激活进入就绪状态, 等待操作系统调度;设置对象的时候,默认是False的 event.clear():恢复event的状态值为False。
用一个例子来演示Event对象的用法:
import threading,time
event=threading.Event() #创建一个event对象
def foo():
print('wait.......')
event.wait()
#event.wait(1)#if event 对象内的标志位为Flase,则阻塞
#wait()里面的参数的意思是:只等待1秒,如果1秒后还没有把标志位改过来,就不等了,继续执行下面的代码
print('connect to redis server')
print('attempt to start redis sever)')
time.sleep(3)
event.set()
for i in range(5):
t=threading.Thread(target=foo,args=())
t.start()
#3秒之后,主线程结束,但子线程并不是守护线程,子线程还没结束,所以,程序并没有结束,应该是在3秒之后,把标志位设为true,即event.set()
5.队列
官方文档说队列在多线程中保证数据安全是非常有用的
队列可以理解为是一种数据结构,可以存储数据,读写数据。就类似列表里面加了一把锁
5.1get和put方法
import queue
#队列里读写数据只有put和get两个方法,列表的那些方法都没有
q=queue.Queue()#创建一个队列对象 FIFO先进先出
#q=queue.Queue(20)
#这里面可以有一个参数,设置最大存的数据量,可以理解为最大有几个格子
#如果设置参数为20,第21次put的时候,程序就会阻塞住,直到有空位置,也就是有数据被get走
q.put(11)#放值
q.put('hello')
q.put(3.14)
print(q.get())#取值11
print(q.get())#取值hello
print(q.get())#取值3.14
print(q.get())#阻塞,等待put一个数据
![]()
get方法中有个默认参数block=True,把这个参数改成False,取不到值的时候就会报错queue.Empty
这样写就等同于写成q.get_nowait())
5.2join和task_done方法
import queue
import threading
#队列里只有put和get两个方法,列表的那些方法都没有
q=queue.Queue()#
def foo():#存数据
# while True:
q.put(111)
q.put(222)
q.put(333)
q.join()
print('ok')#有个join,程序就停在这里
def bar():
print(q.get())
q.task_done()
print(q.get())
q.task_done()
print(q.get())
q.task_done()#要在每个get()语句后面都加上
t1=threading.Thread(target=foo,args=())
t1.start()
t2=threading.Thread(target=bar,args=())
t2.start()
#t1,t2谁先谁后无所谓,因为会阻塞住,等待信号
5.3 其他方法
q.qsize() 返回队列的大小
q.empty() 如果队列为空,返回True,反之False
q.full() 如果队列满了,返回True,反之False
q.full 与 maxsize 大小对应
5.4其他模式
前面说的队列都是先进先出(FIFO)模式,另外还有先进后出(LIFO)模式和优先级队列
先进后出模式创建队列的方式是:class queue.LifoQueue(maxsize)
优先级队列的写法是:class queue.Priorityueue(maxsize)
q=queue.PriorityQueue()
q.put([5,100])#这个方括号只是代表一个序列类型,元组列表都行,但是都必须所有的一样
q.put([7,200])
q.put([3,"hello"])
q.put([4,{"name":"alex"}])
中括号里面第一个位置就是优先级
5.5 生产者消费者模型
生产者就相当于产生数据的线程,消费者就相当于取数据的线程。我们在编写程序的时候,一定要考虑生产数据的能力和消费数据的能力是否匹配,如果不匹配,那肯定要有一方需要等待,所以引入了生产者和消费者模型。
这个模型是通过一个容器来解决生产者和消费者之间的 强耦合问题。有了这个容器,他们不用直接通信,而是通过这个容器,这个容器就是一个阻塞队列,相当于一个缓冲区,平衡了生产者和消费者的能力。我们写程序时用的目录结构,不也是为了解耦和吗
除了解决强耦合问题,生产者消费者模型还能实现并发
当生产者消费者能力不匹配的时候,就考虑加限制,类似if q.qsize()<20,这种
四、多进程
python 中有一把全局锁(GIL)使得多线程无法使用多核,但是如果是多进程,这把锁就限制不了了。如何开多个进程呢,需要导入一个multiprocessing模块
import multiprocessing
import time
def foo():
print('ok')
time.sleep(2)
if __name__ == '__main__':#必须是这个格式
p=multiprocessing.Process(target=foo,args=())
p.start()
print('ending')
虽然可以开多进程,但是一定注意不能开太多,因为进程间切换非常消耗系统资源,如果开上千个子进程,系统会崩溃的,而且进程间的通信也是个问题。所以,进程能不用就不用,能少用就少用
1.进程间的通信
进程间通信有两种方式,队列和管道
1.1进程间的队列
每个进程在内存中都是独立的一块空间,不项线程那样可以共享数据,所以只能由父进程通过传参的方式把队列传给子进程
import multiprocessing import threading def foo(q): q.put([12,'hello',True]) if __name__ =='__main__': q=multiprocessing.Queue()#创建进程队列 #创建一个子线程 p=multiprocessing.Process(target=foo,args=(q,)) #通过传参的方式把这个队列对象传给父进程 p.start() print(q.get())
1.2管道
之前学过的socket其实就是管道,客户端 的sock和服务端的conn是管道 的两端,在进程中也是这个玩法,也要有管道的两头
from multiprocessing import Pipe,Process
def foo(sk):
sk.send('hello')#主进程发消息
print(sk.recv())#主进程收消息
sock,conn=Pipe()#创建了管道的两头
if __name__ == '__main__':
p=Process(target=foo,args=(sock,))
p.start()
print(conn.recv())#子进程接收消息
conn.send('hi son')#子进程发消息
2.进程间的数据共享
我们已经通过进程队列和管道两种方式实现了进程间的通信,但是还没有实现数据共享
进程间的数据共享需要引用一个manager对象实现,使用的所有的数据类型都要通过manager点的方式去创建
from multiprocessing import Process from multiprocessing import Manager def foo(l,i): l.append(i*i) if __name__ == '__main__': manager = Manager() Mlist = manager.list([11,22,33])#创建一个共享的列表 l=[] for i in range(5): #开辟5个子进程 p = Process(target=foo, args=(Mlist,i)) p.start() l.append(p) for i in l: i.join()#join 方法是等待进程结束后再执行下一个 print(Mlist)
3.进程池
进程池的作用是维护一个最大的进程量,如果超出设置的最大值,程序就会阻塞,知道有可用的进程为止
from multiprocessing import Pool
import time
def foo(n):
print(n)
time.sleep(2)
if __name__ == '__main__':
pool_obj=Pool(5)#创建进程池
#通过进程池创建进程
for i in range(5):
p=pool_obj.apply_async(func=foo,args=(i,))
#p是创建的池对象
# pool 的使用是先close(),在join(),记住就行了
pool_obj.close()
pool_obj.join()
print('ending')
进程池中有以下几个方法:
1.apply:从进程池里取一个进程并执行 2.apply_async:apply的异步版本 3.terminate:立刻关闭线程池 4.join:主进程等待所有子进程执行完毕,必须在close或terminate之后 5.close:等待所有进程结束后,才关闭线程池
五、协程
协程在手,天下我有,说走就走。知道了协程,前面说的进程线程就都忘记吧
协程可以开很多很多,没有上限,切换之间的消耗可以忽略不计
1.yield
先来回想一下yield这个词,熟悉不,对,就是生成器那用的那个。yield是个挺神奇的东西,这是Python的一个特点。
一般的函数,是遇到return就停止,然后返回return 后面的值,默认是None,yield和return很像,但是遇到yield不会立刻停止,而是暂停住,直到遇到next(),(for循环的原理也是next())才会继续执行。yield 前面还可以跟一个变量,通过send()函数给yield传值,把值保存在yield前边的变量中
import time
def consumer():#有yield,是一个生成器
r=""
while True:
n=yield r#程序暂停,等待next()信号
# if not n:
# return
print('consumer <--%s..'%n)
time.sleep(1)
r='200 ok'
def producer(c):
next(c)#激活生成器c
n=0
while n<5:
n=n+1
print('produer-->%s..'%n)
cr = c.send(n)#向生成器发送数据
print('consumer return :',cr)
c.close() #生产过程结束,关闭生成器
if __name__ == '__main__':
c=consumer()
producer(c)
看上面的例子,整个过程没有锁的出现,还能保证数据安全,更要命的是还可以控制顺序,优雅的实现了并发,甩多线程几条街
线程叫微进程,而协程又叫微线程。协程拥有自己的寄存器上下文和栈,因此能保留上一次调用的状态。
2.greenlet模块
这个模块封装了yield,使得程序切换非常方便,但是没法实现传值的功能
from greenlet import greenlet
def foo():
print('ok1')
gr2.switch()
print('ok3')
gr2.switch()
def bar():
print('ok2')
gr1.switch()
print('ok4')
gr1=greenlet(foo)
gr2=greenlet(bar)
gr1.switch()#启动
3.gevent模块
在greenlet模块的基础上,开发出了更牛的模块gevent
gevent为Python提供了更完善的协程支持,其基本原理是:
当一个greenlet遇到IO操作时,就会自动切换到其他的greenlet,等IO操作完成,再切换回来,这样就保证了总有greenlet在运行,而不是等待
import requests
import gevent
import time
def foo(url):
response=requests.get(url)
response_str=response.text
print('get data %s'%len(response_str))
s=time.time()
gevent.joinall([gevent.spawn(foo,"https://itk.org/"),
gevent.spawn(foo, "https://www.github.com/"),
gevent.spawn(foo, "https://zhihu.com/"),])
# foo("https://itk.org/")
# foo("https://www.github.com/")
# foo("https://zhihu.com/")
print(time.time()-s)
4.协程的优缺点:
优点:
上下文切换消耗小
方便切换控制流,简化编程模型
高并发,高扩展性,低成本
缺点:
无法利用多核
进行阻塞操作时会阻塞掉整个程序
六、IO模型
我们下面会比较四种IO模型
1.blocking IO
2.nonblocking IO
3.IO multiplexing
4.asynchronous IO
我们以网络传输数据的IO为例,它会涉及到两个系统对象,一个是调用这个IO 的线程或者进程,另一个是系统内核,而当读取数据的时候,又会经历两个阶段:
等待数据准备
将数据从内核态拷贝到用户态的进程中(因为网络的数据传输是靠物理设备实现的,物理设备是硬件,只能有操作系统的内核态才能处理,但是读数据是程序使用的,所以需要这一步的切换)
1.blocking IO(阻塞IO)
典型的read操作如下图
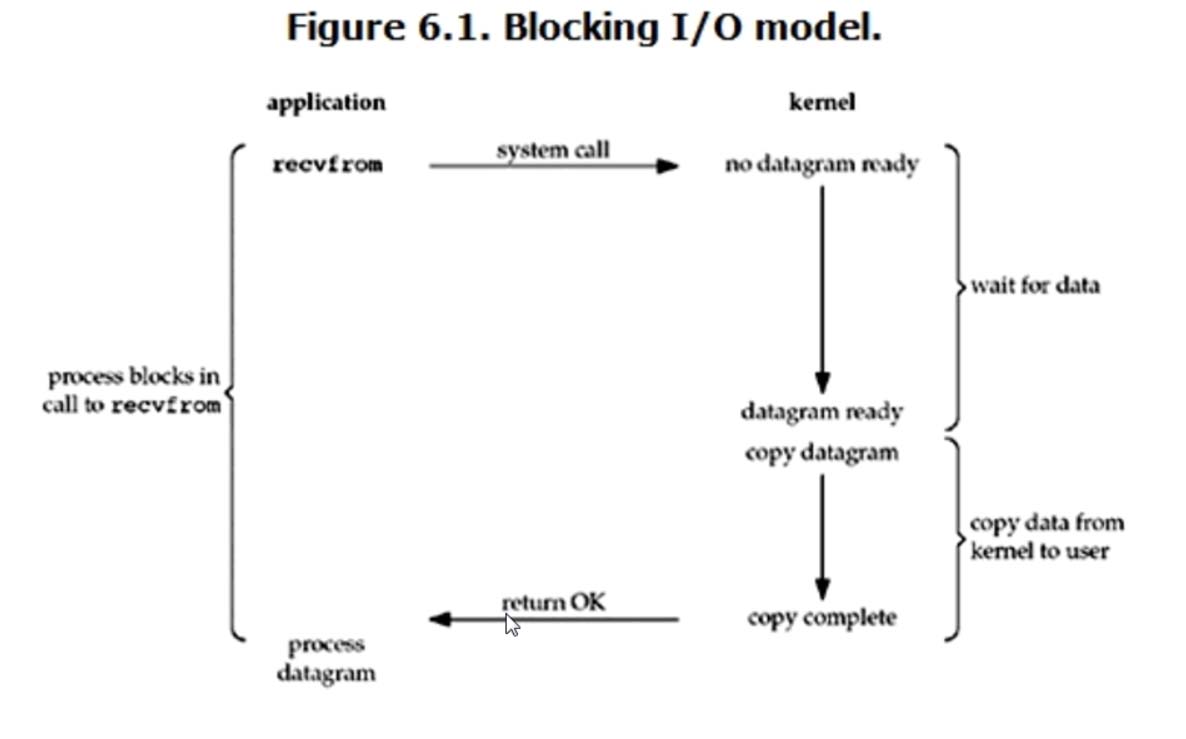
linux下,默认情况的socket都是blocking,回想我们之前用的socket,sock和conn是两个连接,服务端同时只能监听一个连接,所以如果服务端在等待客户端发送消息的时候,其他连接是不能连接到服务端的。
在这种模式下,等待数据和复制数据都需要等待,所以是全程阻塞的
2.nonlocking IO (非阻塞IO)
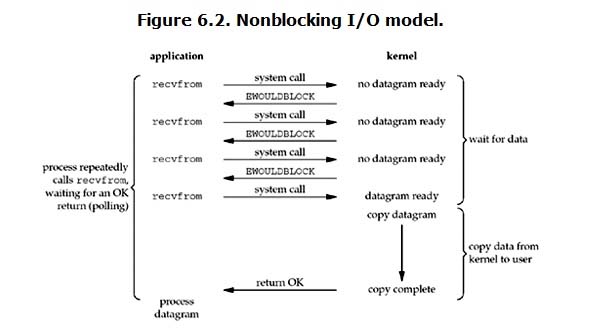
在服务端建立连接之后,加上这个命令,就变成了非阻塞IO模式
这种模式,有数据就取,没有就报错,可以加一个异常捕捉。在等待数据的时候不阻塞,但是在copy数据的时候还是会阻塞,
优点是可以把等待连接的这段时间利用上,但是缺点也很明显:有很多次系统调用,消耗很大;而且当程序去做别的事的时候,数据到了,虽然不会丢失,但是程序收到的数据也不具有实时性
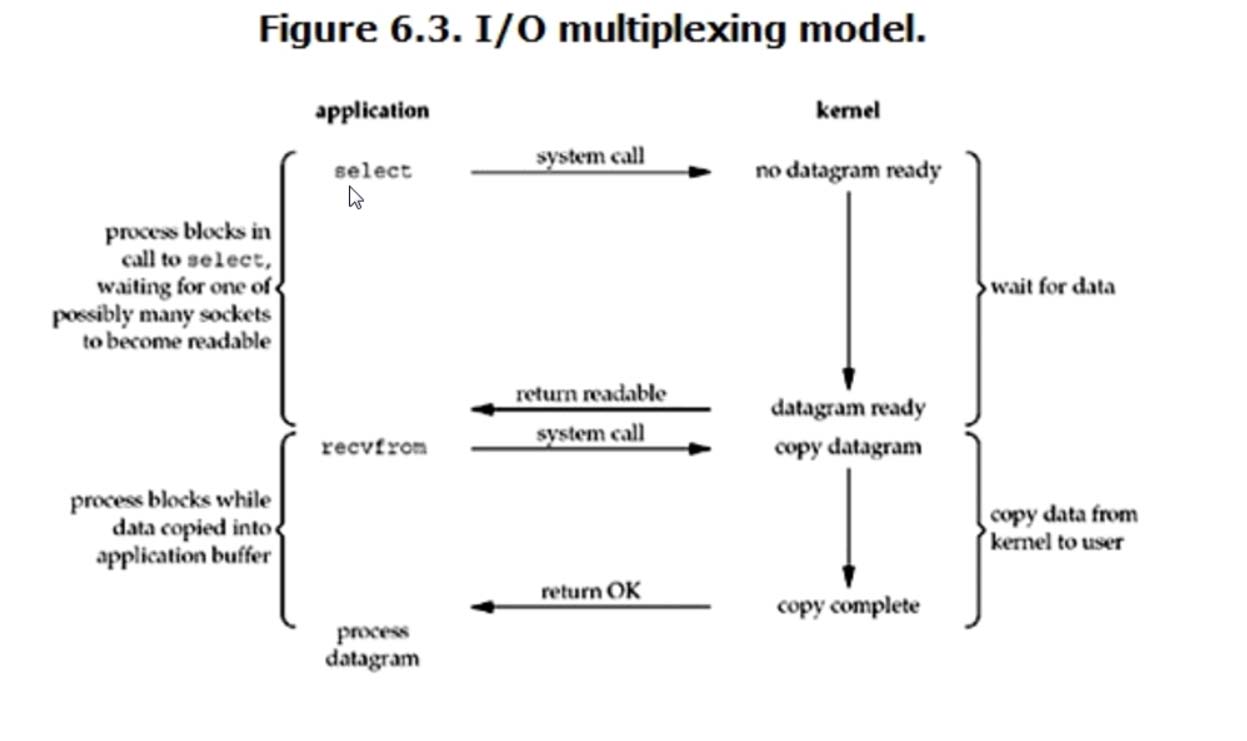
3.IO multiplexing(IO多路复用)
这个比较常用,我们以前用的accept(),有两个作用:
1.监听,等待连接
2.建立连接
现在我们用select来替代accept的第一个作用,select的优点在于可以监听很多对象,无论哪个对象活动,都能做出反应,并将活动的对象收集到一个列表
import socket
import select
sock=socket.socket()
sock.bind(('127.0.0.1',8080))
sock.listen(5)
inp=[sock,]
while True:
r=select.select(inp,[],[])
print('r',r[0])
for obj in r[0]:
if obj == sock:
conn,addr=obj.accept()
但是建立连接的功能还是accept做,有了这个,我们就可以用并发的方式实现tcp的聊天了
# 服务端
import socket
import time
import select
sock=socket.socket()
sock.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
sock.bind(('127.0.0.1',8080))
sock.listen(5)
inp=[sock,]#监听套接字对象的列表
while True:
r=select.select(inp,[],[])
print('r',r[0])
for obj in r[0]:
if obj == sock:
conn,addr=obj.accept()
inp.append(conn)
else:
data=obj.recv(1024)
print(data.decode('utf8'))
response=input('>>>>:')
obj.send(response.encode('utf8'))
只有在建立连接的时候,sock才是活动的,列表中才会有这个对象,如果是在建立连接之后,收发消息的过程中,活动对象就不是sock,而是conn了,所以在实际操作中要判断列表中的对象是不是sock
在这个模型中,等待数据与copy数据的过程都是阻塞的,所以也叫全程阻塞,与阻塞IO模型相比,这个模型优势在于处理多个连接
IO 多路复用除了select,还有两种方式,poll 和 epoll
在windows下只支持select,而在linux中,这三个都有。epoll是最好的,select唯一的优点是多平台都可以用,但是缺点也很明显,就是效率很差。poll是epoll和select的中间过渡,与select相比,poll可以监听的数量没有限制。epoll没有最大连接上限,另外监听机制也完全发生变化,select的机制是轮询(每个数据都检查一遍,即使找到有变化的也会继续检查),epoll的机制是用回调函数,哪个对象有变化,那个就调用这个回调函数
4. Asynchronous IO (异步IO)
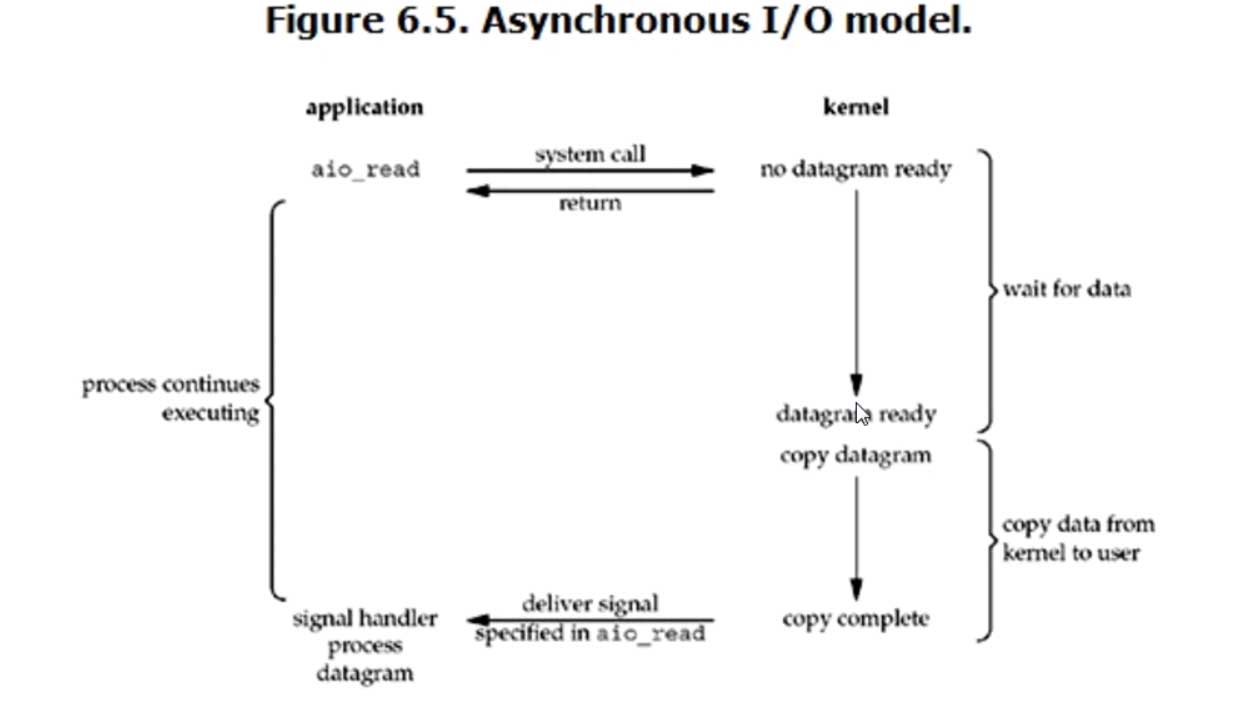
这个模式是全程无阻塞,只有全程无阻塞才能叫异步,这个模式虽然看起来不错,但是实际操作起来,如果请求量很大,效率会很低,而且操作系统的任务很重
七、selectors 模块
学会了这个模块,就不用在乎用的是select,还是poll,或者是epoll了,他们的接口都是这个模块。我们只需要知道这个接口怎么用,它里面封装的是什么,就不用考虑了
在这个模块中,套接字与函数的绑定是用的一个regesier()的方法,模块的用法很固定,服务端示例如下:
import selectors,socket
sel=selectors.DefaultSelector()
sock=socket.socket()
sock.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
sock.bind(('127.0.0.1',8080))
sock.listen(5)
sock.setblocking(False)
def read(conn,mask):
data=conn.recv(1024)
print(data.decode('utf8'))
res=input('>>>>>>:')
conn.send(res.encode('utf8'))
def accept(sock,mask):
conn,addr=sock.accept()
sel.register(conn,selectors.EVENT_READ,read)#conn和read函数绑定
#绑定套接字对象和函数
#绑定(register)的意思就是,套接字对象conn发生变化时,绑定的函数能执行
sel.register(sock,selectors.EVENT_READ,accept)#中间那个是固定写法
while True:
events=sel.select() #监听套接字对象(注册的那个)
#下面几行代码基本上就固定写法了
# print('events',events)
for key,mask in events:
callback = key.data#绑定的函数,
# key.fileobj就是活动的套接字对象
# print('callback',callable)
#mask是固定的
callback(key.fileobj,mask)#callback是回调函数
# print('key.fileobj',key.fileobj)
以上这篇老生常谈进程线程协程那些事儿就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
加载全部内容