数据挖掘比赛/项目全流程介绍
FinTecher 人气:0【说在前面】本人博客新手一枚,象牙塔的老白,职业场的小白。以下内容仅为个人见解,欢迎批评指正,不喜勿喷![握手][握手]
1. 数据预处理
1.1 选择数据样本(企业级应用)
- 例如客观选择某一时间段内的所有样本集合等(避免人为主观选择)
- 例如在评价样本中去除恶意/随意评价样本等(避免错误样本的干扰)
1.2 可视化特征分布
- dataframe.infohttps://img.qb5200.com/download-x/dataframe.describe等(查看数据样本的整体分布情况)
- dataframe.plot/matplotlib/seaborn等(包括柱状图/散点图/折线图等)
1.3 缺失值处理
- 如果某样本的缺失记录占比较大:
- 可统计为“缺失量”
- 可直接删除该样本
- 如果某特征的缺失记录占比较大:
- 可二值化为“有/无”
- 可直接删除该样本
- 如果某样本/特征的缺失记录占比较小:
- 可根据领域知识补全
- 数值型:可根据均值/众数/模型预测等补全
- 类别型:可以定义为新的类别等
- 可不处理,有些模型对缺失值不敏感:例如树模型/神经网络等
1.4 异常值处理
- 异常值判定:需根据数据分布/业务场景等
- RobustScaler/robust_scale等
- 之后会推出异常值检测专题
- 可直接删除该样本
- 可采用缺失值的处理方式
- 注意数据不一致问题
- 注意数值型可用盖帽/对数变换等压缩
- 可不处理,有些模型对异常值不敏感:例如KNN/随机森林等

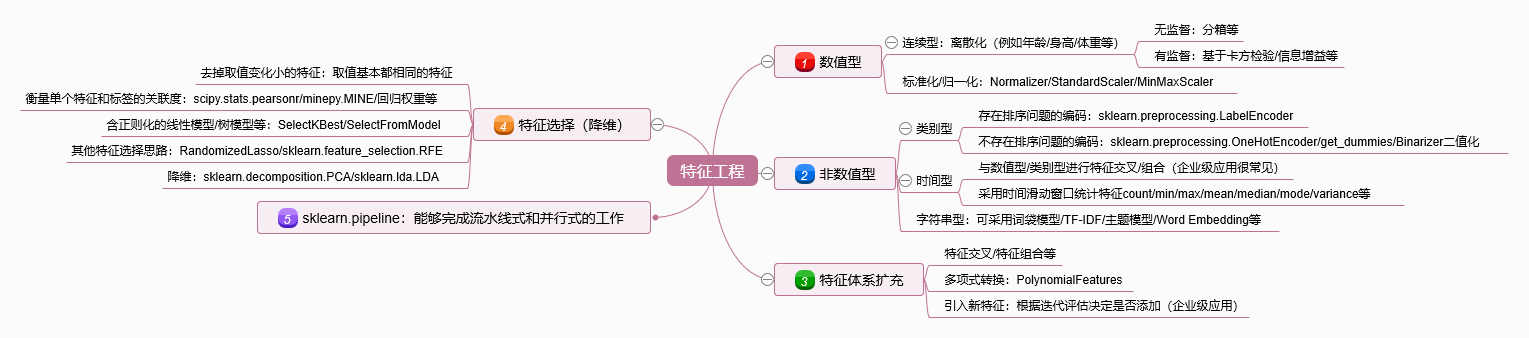
2. 特征工程
2.1 数值型
- 连续型:离散化(例如年龄/身高/体重等)
- 无监督:分箱等
- 有监督:基于卡方检验/信息增益等
- 标准化/归一化:Normalizer/StandardScaler/MinMaxScaler
2.2 非数值型
- 类别型
- 存在排序问题的编码:sklearn.preprocessing.LabelEncoder
- 不存在排序问题的编码:sklearn.preprocessing.OneHotEncoder/get_dummies/Binarizer二值化
- 时间型
- 与数值型/类别型进行特征交叉/组合(企业级应用很常见)
- 采用时间滑动窗口统计特征count/min/max/mean/median/mode/variance等
- 字符串型
- 可采用词袋模型/TF-IDF/主题模型/Word Embedding等
2.3 特征体系扩充
- 特征交叉/特征组合等
- 多项式转换:PolynomialFeatures
- 引入新特征:根据迭代评估决定是否添加(企业级应用)
2.4 特征选择(降维)
- 去掉取值变化小的特征:取值基本都相同的特征
- 衡量单个特征和标签的关联度:scipy.stats.pearsonr/minepy.MINE/回归权重等
- 含正则化的线性模型/树模型等:SelectKBest/SelectFromModel
- 其他特征选择思路:RandomizedLasso/sklearn.feature_selection.RFE
- 降维:sklearn.decomposition.PCA/sklearn.lda.LDA
2.5 sklearn.pipeline
- 能够完成流水线式和并行式的工作
3. 模型选择/融合
3.1 常见的机器学习算法
- lr/svm/rf/GBDT/xgboost/lightgbm等
3.2 模型融合
- 回归预测的boosting思路:各模型的加权平均融合
- 分类识别的bagging思路:各模型的投票融合
- Stacking/Blending等模型融合方法
3.3 企业级模型应用思路
- lr/xgboost/gbdt+lr/引入DNN等

4. 模型训练/测试
4.1 数据集划分
- 按比例划分:sklearn.model_selection.train_test_split
- K折交叉验证:KFold/GroupKFold/StratifiedKFold
4.2 调参
- 网格搜索/贝叶斯优化等(sklearn.grid_search.GridSearchCV)

5. 其他问题
5.1 样本不均衡问题
- 数据角度:欠采样/过采样/SMOTE算法等
- 模型角度:调整lr的阈值/采用树模型等
- 评估角度:采用F1值/ROC曲线等
5.2 无标签样本问题
- 半监督学习方法/聚类思考等
5.3 欠拟合/过拟合问题
- 欠拟合
- 特征扩充/非线性模型等
- 过拟合
- 扩充数据集/正则化/early stoppping/交叉验证
- Dropout/batch normalization

6. 模型评估
6.1 回归问题
- 平均绝对误差MAE/平均平方误差MSE/均方根误差RMSE/决定系数R2等
6.2 分类问题
- 混淆矩阵/准确率/召回率/F1/ROC曲线/AUC/PR曲线/交叉熵损失等
6.3 上线问题
- 线下预估/流量分配/ABtesting/业务评估指标等(企业级应用)

老规矩,最后直接上完整的思维导图!

如果您对人工智能算法感兴趣,欢迎浏览我的另一篇博客:人工智能新手入门学习路线和学习资源合集(含AI综述/python/机器学习/深度学习/tensorflow)
如果你是计算机专业的应届毕业生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的应届生,你如何准备求职面试?
如果你是计算机专业的本科生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的本科生,你可以选择学习什么?
如果你是计算机专业的研究生,欢迎浏览我的另外一篇博客:如果你是一个计算机领域的研究生,你可以选择学习什么?
如果你对金融科技感兴趣,欢迎浏览我的另一篇博客:如果你想了解金融科技,不妨先了解金融科技有哪些可能?
之后博主将持续分享各大算法的学习思路和学习笔记:hello world: 我的博客写作思路
加载全部内容