Web Scraper 高级用法——使用 CouchDB 存储数据 | 简易数据分析 18
卤代烃实验室 人气:1
这是简易数据分析系列的第 18 篇文章。
利用 web scraper 抓取数据的时候,大家一定会遇到一个问题:数据是乱序的。在之前的教程里,我建议大家利用 Excel 等工具对数据二次加工排序,但还是存在部分数据无法排序的情况。
其实解决数据乱序的方法也有,那就是换一个数据库。
web scraper 作为一个浏览器插件,数据默认保存在浏览器的 localStorage 数据库里。其实 web scraper 还支持外设数据库——CouchDB。只要切换成这个数据库,就可以在抓取过程中保证数据正序了。
1.CouchDB 下载安装
CouchDB 可以从官网下载,官网链接为:https://couchdb.apache.org/。
因为服务器在外网,国内访问可能比较慢,我存了一份云盘文件,可以公众号后台回复「CouchDB」获取下载连接,Mac 和 Win 安装包都有,版本为 3.0.0。
具体的安装过程我就忽略了,大家平常怎么安装软件就怎么安装 CouchDB。
2.配置 CouchDB
1.创建账号
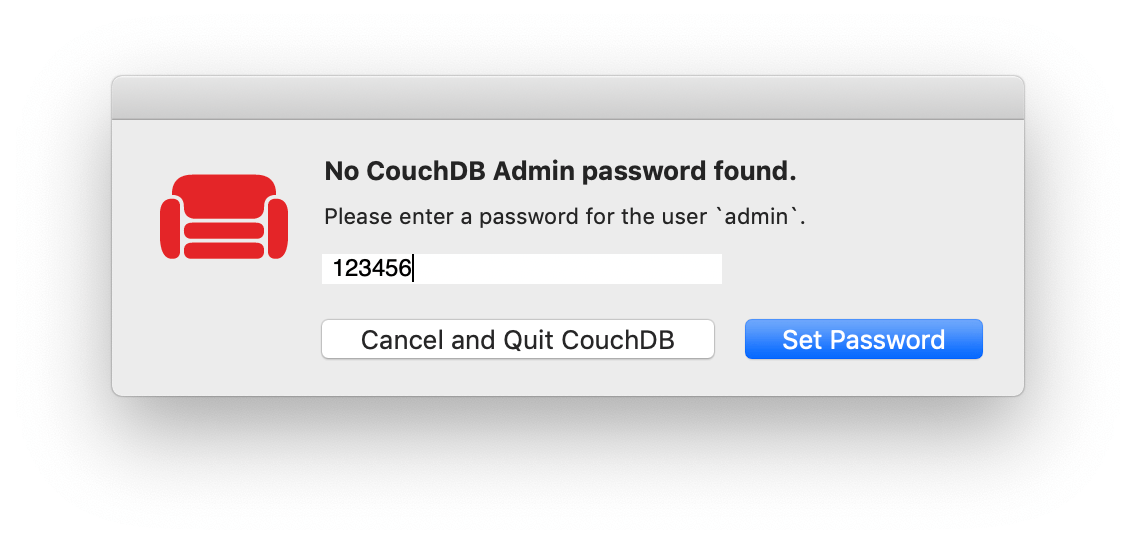
第一次打开 CouchDB,可能会要求你创建一个 CouchDB 账号(或设置账号密码),这里我为了演示方便就取个简单的密码。大家一定要记住账号密码,因为之后访问 CouchDB 都要填写。
2.访问 CouchDB
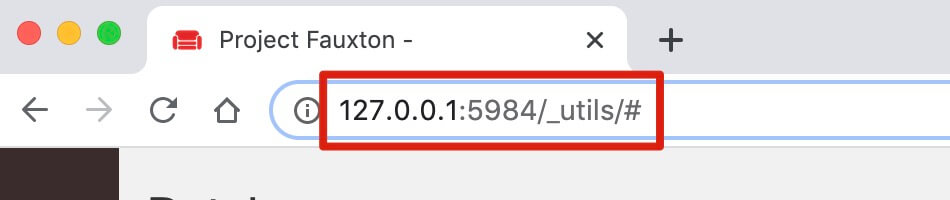
一般第一次打开 CouchDB,会自动打开一个网页,网址为:http://127.0.0.1:5984/_utils/#,如果没有自动打开,可以浏览器手动输入这个网址。
3.创建 Database
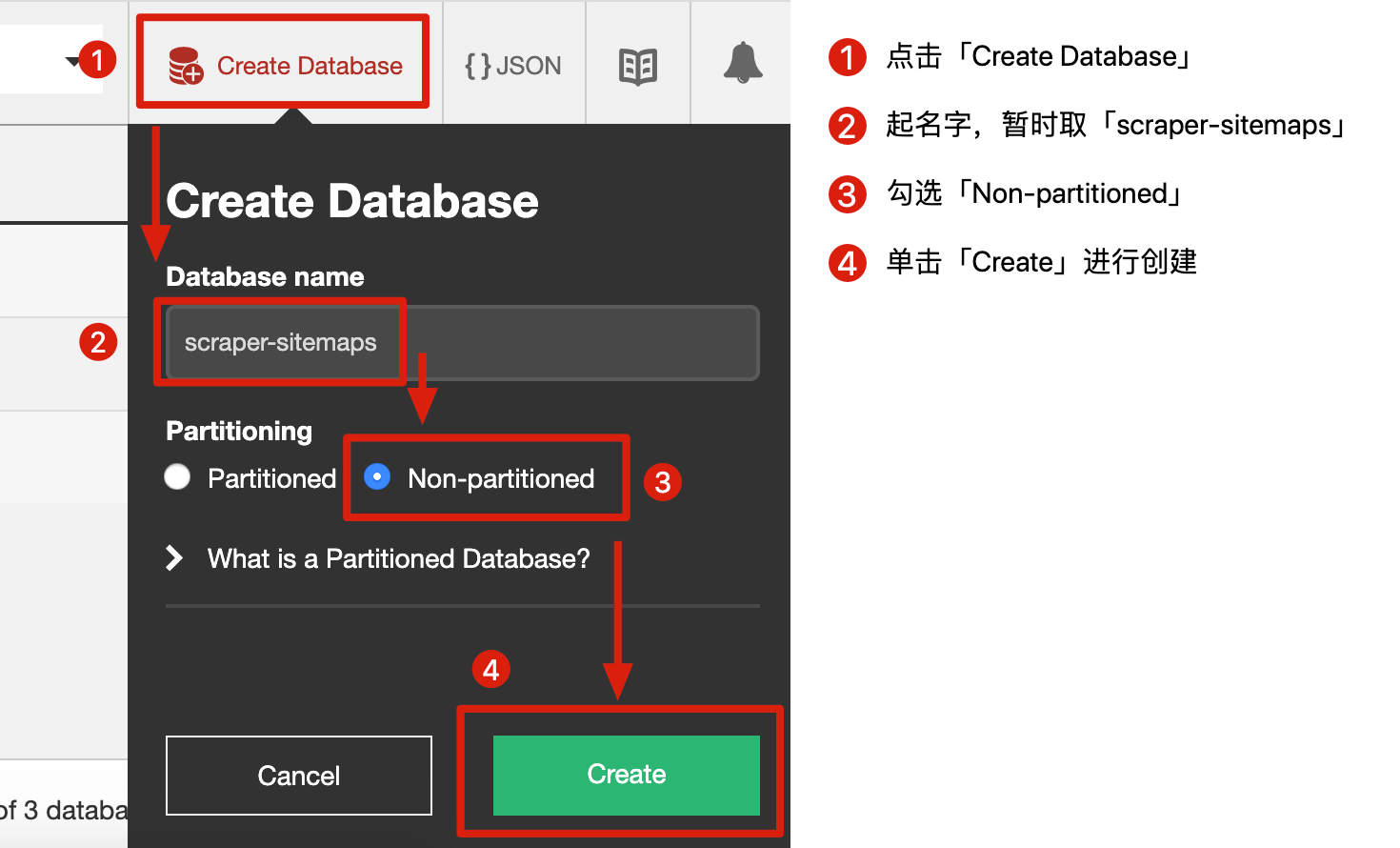
我们可以把 Database 理解为一个文件,我们要创建一个文件专门保存 sitemap,创建流程可以看下图:
- 点击「Create Database」
- 为这个文件起个名字,叫「scraper-sitemaps」
- 勾选「Non-partitioned」
- 单击「Create」创建
3.Web Scraper 切换到 CouchDB
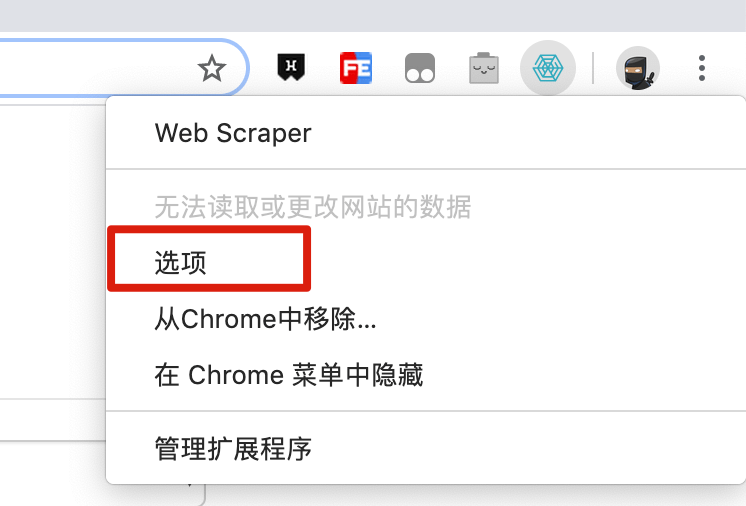
1.首先从浏览器右上角的插件列表中找到 Web Scraper 的图标,然后右键点击,在弹出的菜单里再点击「选项」。
2.在新打开的管理页面里,要做这几步:
- Storage type 切换为 CouchDB
- Sitemap db 填入 http://127.0.0.1:5984/scraper-sitemaps
- Data db 填入 http://127.0.0.1:5984/
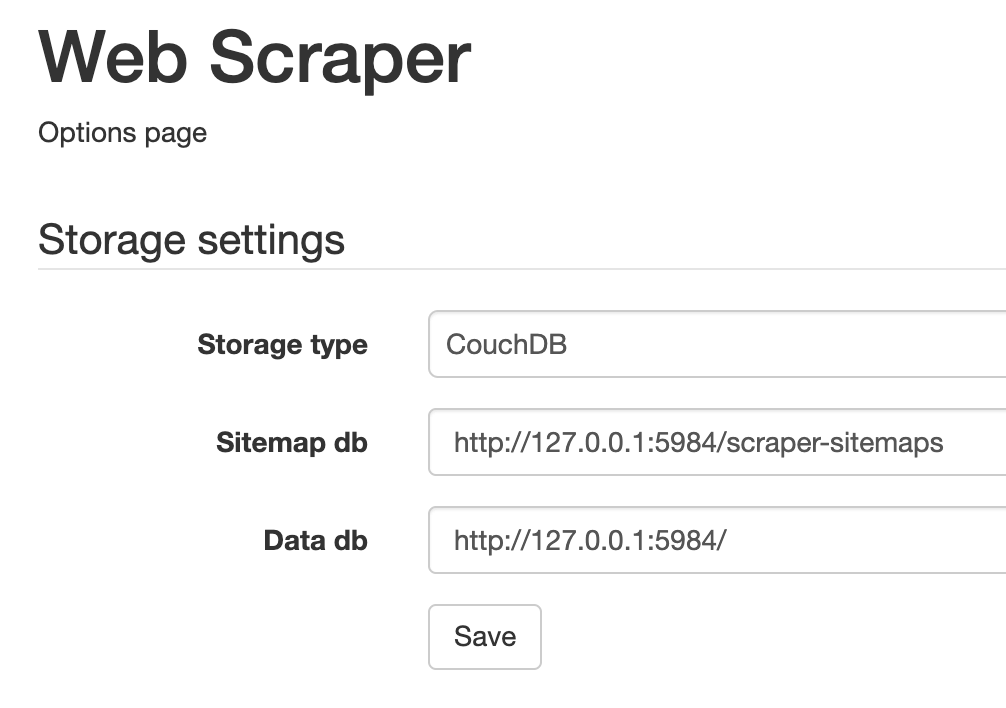
3.最后点击「Save」按钮保存配置,重启浏览器让配置生效。
4.抓取数据
抓取数据前,我们需要把电脑的各种网络代理关掉,要不然可能会连接不到 CouchDB。
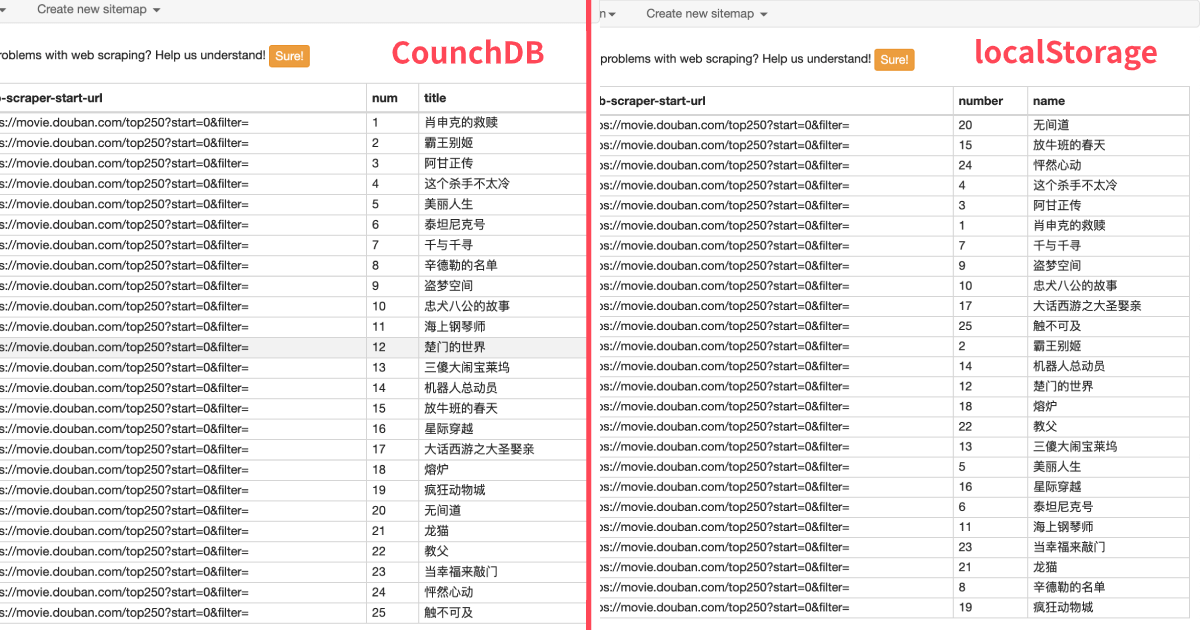
网页还是拿豆瓣 TOP250 做个简单的演示。web scraper 的操作和以前都是一样的,预览数据时我们就会发现,和 localStorage 比起来,数据都是正序的:
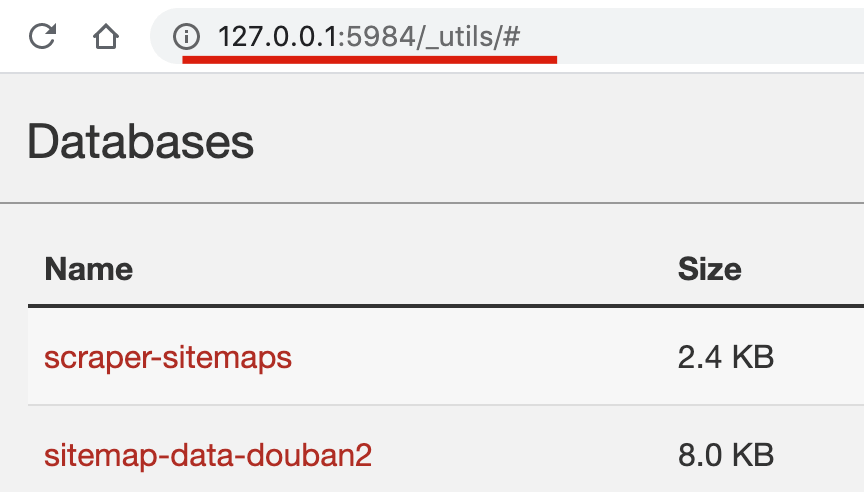
我们也可以在 CouchDB 的操作页面预览数据。http://127.0.0.1:5984/_utils/# 这个页面是主界面,我们可以看到保存 sitemap 的 database 和豆瓣数据的 database:
点击「sitemap-data-douban2」进入数据详情页,可以预览数据:

5.导出数据
导出数据也是老样子,在 web scraper 插件面板里点击「Export data as CSV」就可以导出。其实也可以从 CouchDB 里导出数据,但这样还得写一些脚本,我这里就不多介绍了,感兴趣的人可以自行搜索。
6.个人感悟
其实一开始我并不想介绍 CouchDB,因为从我的角度看,web scraper 是一个很轻量的插件,可以解决一些轻量的抓取需求。加入 CouchDB 后,这个安装下来要几百兆的软件,只是解决了 web scraper 数据乱序的问题,在我看来还是有些大炮打蚊子,也脱离了轻量抓取的初衷。但是有不少读者私信我相关内容,为了教程的完整性,我还是写下了这篇文章。
7.联系我
因为文章发在各大平台上,账号较多不能及时回复评论和私信,有问题可关注公众号 ——「卤代烃实验室」,(或 wx 搜索 sky-chx)关注上车防失联。

加载全部内容