「给产品经理讲JVM」:垃圾收集算法
Vi的技术博客 人气:1纠结的我,给我的JVM系列终于起了第三个名字,害,我真是太难了。从 JVM 到 每日五分钟,玩转 JVM 再到现在的给产品经理讲 JVM ,虽然内容为王,但是标题可以让更多的人看到我的文章,所以,历经了三个选题,最终定下来了这个。
这个名字的由来,且听我给你慢慢道来,从学习知识的角度上来说,最深入的方法就是把知识讲给别人听,那么为什么我要讲给程序员的天敌——产品经理呢?
那么问题的答案很简单,因为我「老婆」就是一个「产品经理」哈哈哈哈哈哈哈(听说现在流行这样玩?
认识的时候她是 Java 开发来着,谁知道领了证就变成了产品。。小 朋 友 你 是 否 有 很 多 ???(手动摊手

废话不多说了,下面开始进入我们的正文~
背景
故事发生在一个明媚的午后,我刚看完《深入理解Java虚拟机》第三章的第三节——垃圾收集算法,我的产品大人开始了例行盘问
产品大大:你天天学的什么啊,我看着好像很眼熟??
我:???你难道忘了你曾经是一个 Java 程序员,JVM 都忘了?

产品大大:JVM 啊,基本上忘的差不多了,要不你给我讲讲,省的我们「开发天天忽悠我」
于是,我就这么做了程序员的叛徒
我:行吧,那我就来给你讲一讲这一节中我的收获吧。
接上集
我:在开始之前,我们先来回顾一下上次讲的东西,上次我们说到了如何判定一个对象是不是垃圾对象(已死),通常来说有两种算法——「引用计数法和可达性分析法」,目前市面上的虚拟机大多数采用的是第二种——可达性分析法。
产品大大:那么这两种方法是不是对应了两个类型的垃圾收集算法呢?
我:真聪明,果然「不是一家人,不进一家门」,这两种分别对应了Reference Counting GC(引用计数垃圾收集)和 Tracing GC(追踪垃圾收集),而我们今天讲的垃圾收集算法都属于追踪垃圾收集的范畴。不过在介绍垃圾收集算法之前,我首先需要向你介绍一个很关键的理论——分代收集理论。
产品大大:好嘞
分代收集理论
我:所谓分代收集理论从某种意义上来说,是一种约定俗称的规范和经验的总结,并不是一个非常严格的规则。
产品大大:嗯嗯,约定大于配置,现在这样的思想在很多地方都有体现,那么到底什么是分代收集呢?
我:且听我慢慢道来,分代收集建立在三个假说之上:
绝大多数对象都是朝生夕死的。 熬过越多次的GC的对象越难以消亡。 跨代饮用相对于同代引用仅占极少一部分。
产品大大:这三个我好像在哪见过,但是记不太清楚了,能不能说的更详细一点
我:由于绝大多数对象都是朝生夕死的,而熬过越多次GC的对象越难消灭掉,这样自然而然的就会把对象分成两个派别,一种是极易发生GC的,一种是极难发生GC的,极易发生GC的生命周期较短,所以也被称之为「新生代」,极难发生GC的对象生命周期较长,所以也可以叫他们「老年代」。
产品大大:这么一说,我好像有点明白了,但是为什么要分代呢?
我:如果我们把他们进行分代后,可以对区域进行划分,一部分用于存储新生代,新生代的对象我们只需要去关注那些不被回收的对象就可以,而不用去标注绝大多数需要回收的对象;一部分用于存储老年代,老年代发生GC的频率较低。这两个区域的GC频率是不同的,所以分开进行GC的话可以节省很多时间和存储这些对象的空间。
产品大大:原来是这样,那么为什么会有第三个假说呢?
我:如果出现新生代中存在老年代对象的引用,或者老年代对象中存在新生代对象的引用,这样的现象被我们称之为跨代引用,而我们为了确保可达性分析法的准确性,还需要去遍历老年代中的对象,这样就会造成很大的性能压力和负担。这时第三条结论就应运而生,为什么会有这条结论呢?你想一想,如果一个新生代对象在进行了几次GC后,因为跨代引用的原因,仍然没有被回收掉,那么这个新生代对象就会晋升到老年代中。于是就解决了这个跨代的问题。
产品大大:那么第三个假设对应的措施是什么呢?
我:文字未免太过苍白,这个适合用图来表达,看好咯

我:这样的话,会不会很清晰(得意脸
产品大大:明白了,那我们继续吧,是不是要进入正题了
我:嗯哼,下面我就来介绍最基础的一种算法——标记清除算法
标记-清除
产品大大:这个我知道,就像它名字那样,标记,然后清除,见名知意嘛哈哈哈哈。
我:厉害了,不愧是技术出身的产品,佩服佩服,确实像你所说的那样,就很简单的两步,标记——清除。
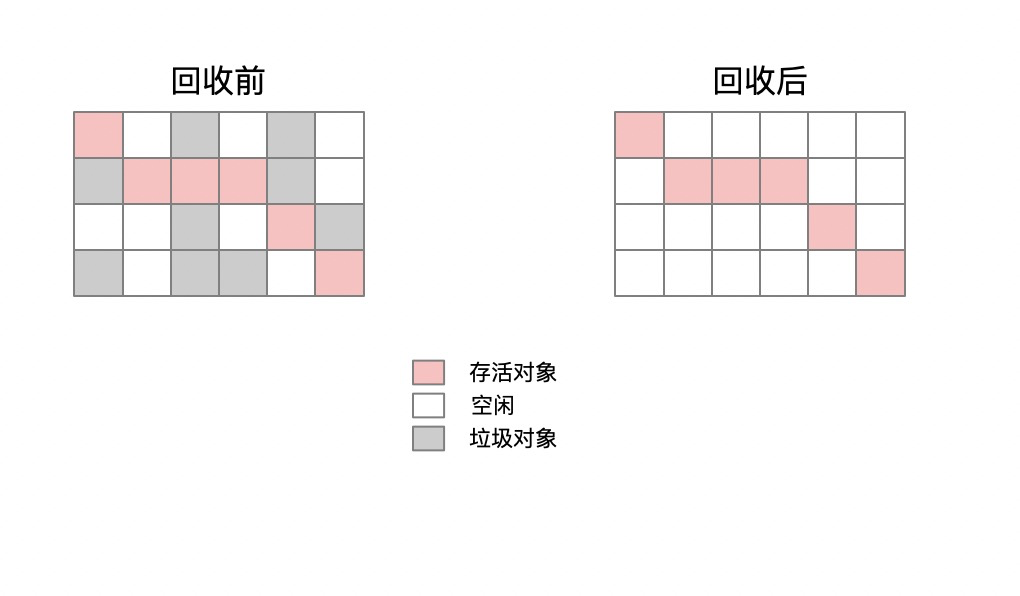
我:但是这样的方式由于过于简陋,虽然在对象较少的时候,效率比较快,但是当对象一多起来的话,标记和清除的效率都会有所下降,而且这样的方式会造成一个问题——产生内存碎片,如果剩下的空白格无法放下一个较大的对象时,就会提前触发另外一个GC。
产品大大:说到这里,好像还漏了点东西,GC针对不同的分代是不是有不同的GC叫法来着?
我:对的,我疏忽了,针对新生代的GC一般称之为(Young GC),针对老年代的GC一般称之为(Old GC),如果是堆和方法区全部回收的话,则被称之为Full GC。
产品大大:这样倒也算好记,OK,我们来进入下一个算法吧。
我:下一个算法,可以看作是第一个算法的升级版本,叫做「标记——复制算法」。
标记-复制
我:标记复制算法,最开始形态是半区复制,就是把之前的内容按照容量划分成等量的两部分,一部分用完之后,就把剩余存活的对象丢到另一半,然后把这一半进行清除,变成预留的另一块。如果是绝大多数对象需要回收(例如新生代)的情况下,这样的方法就会很便捷高效,但是这是一种牺牲空间来换取时间的做法,我们仅仅有效利用了一半的空间,有一半的空间被浪费掉了。

产品大大:所以后来一定会有所改进的,对吗?(期盼脸
我:没错,新的复制算法不能称之为半区复制了,因为新生代内存范围被分割成了三个部分,一个Eden区和两个Survivor区,他们之间的比例是8:1:1。在进行GC的时候,使用一个Eden和一个Survivor区,然后把剩余的存活对象放到另一个Survior区域中,清理掉剩下的区域,就可以完成一次收集的过程,这样仅仅有百分之十的空间被浪费,相对于优点来说,这样的缺点,我们是完全可以接受的,
产品大大:那如果剩下的Survivor不足以放下剩下存活的对象该怎么办呢?
我:问的好,这个时候就要谈到一个新的概念——「内存担保」了,如果不够,就会去找老年代,如果老年代的「连续空间」大于新生代对象总大小或历次晋升的平均值,就可以借给Survivor区使用,至于为什么是这样,且待我卖个关子(其实是我也不知道哈哈哈哈哈
产品大大:那么这种算法听起来好像没有什么缺点的亚子?
我:并不然,复制的操作会降低回收的效率,而且,如果是老年代进行回收的话,你向谁去借呢?所以又出现了第三种算法——标记整理算法。
标记-整理
产品大大:那么什么是标记整理呢?
我:标记-整理算法是一种移动型的算法,通过将存活对象向一边移动,然后直接清除掉边界外的内存以达到不会产生内存碎片的回收算法。
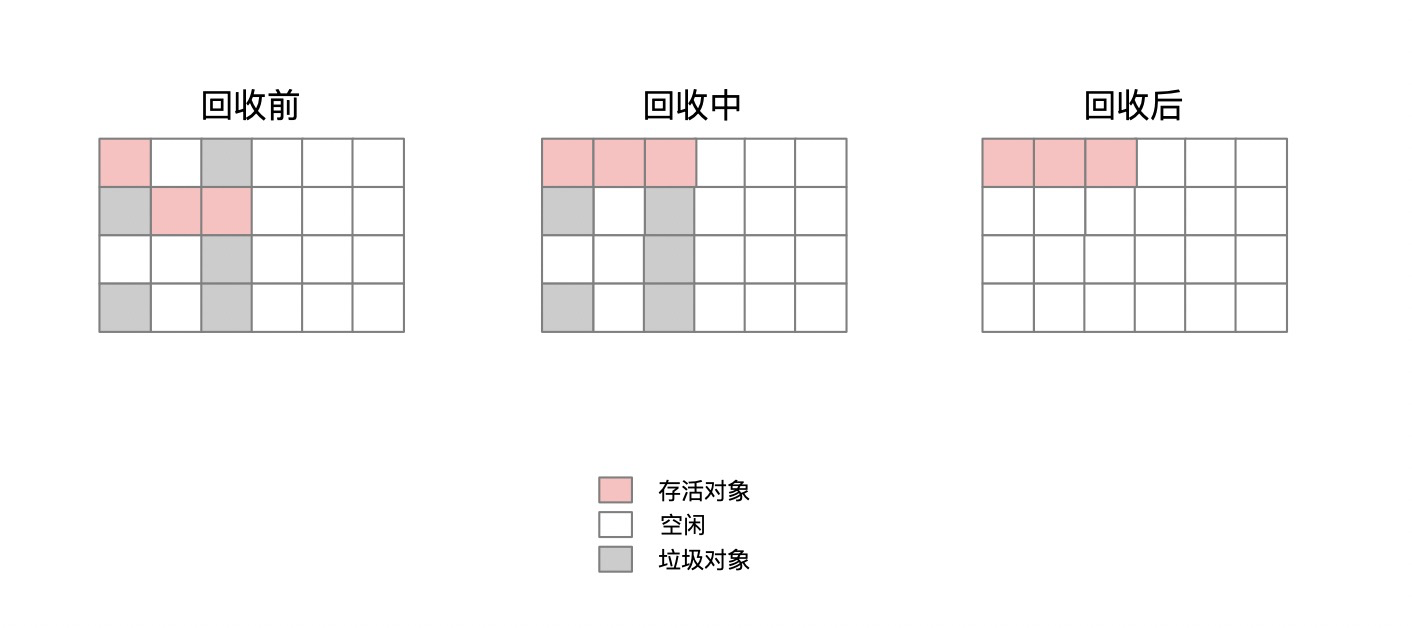
产品大大:那么这个算法的优点就是在于它不会产生内存碎片,减少了回收的次数,那么它和标记-整理相比孰优孰劣呢?
我:对的,虽然在它移动对象的时候会花费不少的时间和资源,但是相对于标记-清除算法来说,频繁的GC所消耗的时间会更多,当然在实际的使用过程中,这三种算法会在不同的应用场景下结合去使用,比如先使用标记-清除算法,当内存碎片达到一定程度后,再使用标记-整理算法去清除,不同的组合会有不同的效果,具体什么效果,我会在给你介绍一些常见的垃圾收集器时进行讲解(下一节哟
产品大大:好的~ 那今天就先到这里吧,讲的差不多够我吸收个三五天的了,过两天你再给我讲吧~
我:好哒。
最后的最后
咳咳,如果知识无法让你吃饱,那你可以多吃点狗粮哈哈哈哈哈哈(太皮会不会挨打嘻嘻
晒一张产品大大给我的备注。
下面又是「精彩」的恰
加载全部内容
- 猜你喜欢
- 用户评论