《SEMI-SUPERVISED CLASSIFICATION WITH GRAPH CONVOLUTIONAL NETWORKS》论文阅读
孔胡子 人气:2背景简介
GCN的提出是为了处理非结构化数据(相对于image像素点而言)。CNN处理规则矩形的网格像素点已经十分成熟,其最大的特点就是利用卷积进行①参数共享②局部连接,如下图:

那么类比到非结构数据图(graph),CNN能直接对非结构数据进行同样类似的操作吗?如果不能,我们又该采用其他什么方式呢?
首先思考能不能,答案是不能。至少我们无法将graph结构的数据规整到如上图所示的矩形方格中,否则结点之间的边无法很好表示。还可以考虑卷积核这一点,我们知道不管我的图(image)如何变化(图片变大或变小,图中狗数量多一只),我们设计好的提取特征的卷积核都不需要变化,但是试想,graph还能这样吗,照猫画虎(就是随意猜想),如果我们也设计和图一样的卷积核,如下图。可见怎么设计可复用发提取有效特征的卷积核就不能单纯从拓扑结构上考虑。
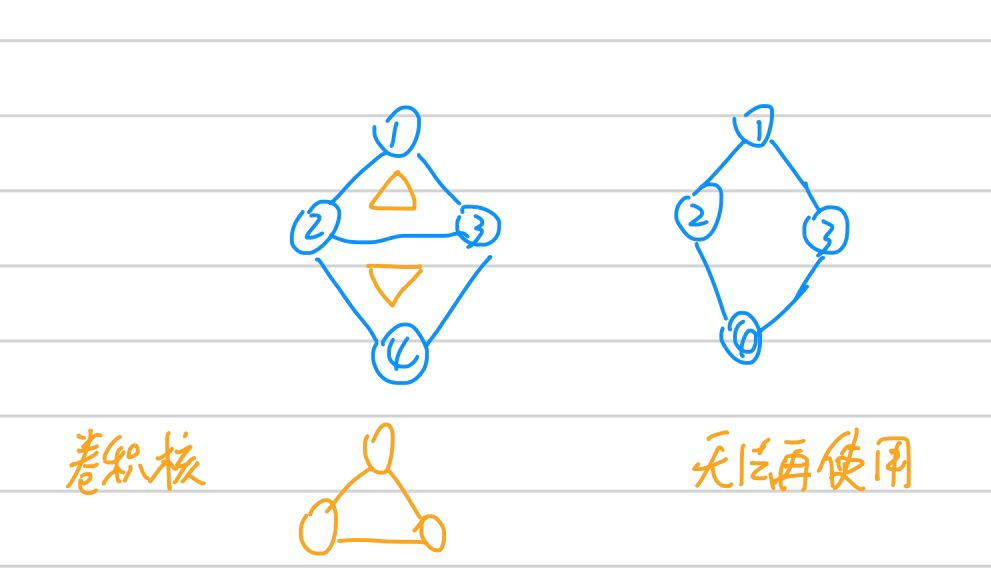
GCN卷积思路
那么人们(这方面的研究在很早之前就有,这篇文章也算是“集大成者+新的idea”)如何考虑在Graph上进行卷积呢?总的来说分为两种
①spatial domain
大致了解了下,抽象来看,和CNN算是有点异曲同工的味道。具体论文还没看过,先不展开细说。
②spectral domain
这篇论文就是从谱方法展开的,这就同spatial角度差了挺远的了。其灵感应该是从信号处理的傅里叶变换时域与频域转换而来,后文详细说明。
傅里叶变换
回顾高数中的傅里叶变换,傅里叶的理论依据就是任何周期非周期(即周期无穷)的的函数都可以由一组正交基($cosx,sinx$)函数通过线性组合表示。然后通过欧拉公式,进一步转换得到如下傅里叶变换和逆变换:

其中逆变换中$F(w)$就是$f(t)$第一个等式基函数的系数。
从信号处理角度来说,可以理解成将一个周期函数,从时域角度分解成了频域角度,如下动图


傅里叶变换函数的基
傅里叶变换的关键点就是,我们通过一组函数的基:三角函数系。类似于空间向量中,我们通过一组基的线性组合,可以表示改空间相中的任何一个向量。

以上,我们只需要知道的就是傅里叶变换是什么,使用了基本函数基的原理
卷积定理
卷积定理:卷积定理是傅立叶变换满足的一个重要性质。卷积定理指出,函数卷积的傅立叶变换是函数傅立叶变换的乘积。换句话说,$$F(f\star g)
=F(f)\cdot F(g)$$,其中符号 $\star $ 代表卷积的意思(CNN中卷积就是离散卷积,两个函数分别是卷积核和图片像素值),$F()$代表傅里叶变换。那么更进一步,两边同时傅里叶逆变换:
$$F^{-1}{\begin{Bmatrix}
F(f\star g)
\end{Bmatrix}}
=F^{-1}\begin{Bmatrix}
F(f)\cdot F(g)
\end{Bmatrix} \\
f\star g
=F^{-1}\begin{Bmatrix}
F(f)\cdot F(g)
\end{Bmatrix}$$
所以,我们求两个函数的卷积的时候,可以分别求两个函数的傅里叶变换,然后再做一次逆傅里叶变换得到

拉普拉斯矩阵
拉普拉斯矩阵的由来是从谱聚类说起,下面是几种场见的拉普拉斯矩阵形式
拉普拉斯矩阵定义
对于图$G=(V, E)$,拉普拉斯的普通形式是$$L=D-A$$,其中$D$是对角顶点度矩阵(零阶矩阵的一行和),$A$是图的邻接矩阵,如下图

$L$中的元素分别为:
$$L_{i,j}=\left\{\begin{matrix}
&diag(v_{i}) &i=j \\
&-1 &i\neq j\,\,and\,\,v_{i}\,\,is\,\,adjacent\,\,to\,\,v_{j} \\
&0 &otherwise
\end{matrix}\right.$$
对称归一化的拉普拉斯矩阵(Symmetric normalized Laplacian)
$$L^{sys}=D^{-1/2}LD^{-1/2}=I-D^{-1/2}AD^{-1/2}$$
其中$L$的各项内容为:
$$L^{sys}_{i,j}=\left\{\begin{matrix}
&1 &i=j\,and\,\,diag(v_{i})\neq 0 \\
&-\frac{1}{\sqrt{diag(v_{i})diag(v_{j})}} \,\,\,\,&i\neq j\,\,and\,\,v_{i}\,\,is\,\,adjacent\,\,to\,\,v_{j} \\
&0 &otherwise
\end{matrix}\right.$$
随机游走归一化拉普拉斯矩阵(Random walk normalized Laplacian)
$$L^{rw}=D^{-1}L=I-D^{-1}A$$
其中$L$的各项内容为:
$$L^{rw}_{i,j}=\left\{\begin{matrix}
&1 &i\neq j\,and\,\,diag(v_{i})\neq 0 \\
&-\frac{1}{diag(v_{i})} \,\,\,\,&i\neq j\,\,and\,\,v_{i}\,\,is\,\,adjacent\,\,to\,\,v_{j} \\
&0 &otherwise
\end{matrix}\right.$$
无向图拉普拉斯的性质
①拉普拉斯矩阵是实对称矩阵,可以对角化
②拉普拉斯矩阵是半正定的(谱聚类中可以根据定义证明$f(x)=x^{T}Ax$,对于任意$x\neq 0$,均有$f(x)\geq 0$)
③最小特征值是0(半正定),对于的特征向量是$1$,容易验证$L1=01$
拉普拉斯矩阵谱分解
根据上一条拉普拉斯矩阵的性质,是对称的,所以一定可以进行对角化,也就是找到一堆正交基
$$L=U\begin{pmatrix}
&\lambda _{1} & &\\
& &\ddots &\\
& & &\lambda _{n}
\end{pmatrix}U^{-1}$$
且其中$U$是单位矩阵,$$UU^{T}=I$$
拉普拉斯算子
拉普拉斯算子的定义是:
$$\bigtriangleup f=\sum \frac{\partial f}{\partial ^{2}x}$$
是由散度推导而来的,上式是$f$对$x$求二阶偏导。那么回忆数字图像处理中离散情况下:
| $f(x-1,y)$ | ||
| $f(x,y-1)$ | $f(x,y)$ | $f(x,y+1)$ |
| $f(x+1,y)$ |
$$\begin{aligned} \Delta f &= \frac{\partial f}{\partial ^{2}x} + \frac{\partial f}{\partial ^{2}y} \\ &=f(x+1,y) + f(x-1,y) - 2f(x,y) + f(x, y+1)+f(x,y-1)-2f(x,y) \\ & = f(x+1,y) + f(x-1,y) + f(x, y+1)+f(x,y-1)-4f(x,y) \end{aligned}$$
也就是说,拉普拉斯算子可以描述某个结点进行扰动之后,相邻结点变化的总收益
那么进行推广:我们希望能将拉普拉斯算子用到graph中,希望能衡量一个结点变化之后,对其他相邻结点的干扰总收益
所以,当某点发生变化时,只需要将所有相邻的点相加再减去该中心点*相邻个数(与上面方格计算二阶偏导类似) 。

而拉普拉斯矩阵$L=D-W$,所以$$\Delta f=(D-W)f=L\cdot f$$,其中$f$是$N*M$代表$N$个结点和每个结点$M$维特征。
而图$D-W=L$恰好是拉普拉斯矩阵。这就是为什么GCN中使用拉普拉斯矩阵$L=D-W$(差负号)的原因:需要对图$f$做拉普拉斯变换,等同于$L\cdot f$
$\Delta = L = D-W$
图上的傅里叶变换
首先,我们的目标始终是要对图 $f$ 做卷积操作,假设卷积核为 $g$,而根据卷积定理有$$ f\star g =F^{-1}\begin{Bmatrix} F(f)\cdot F(g) \end{Bmatrix}$$所以,我们重点需要计算$F(f)$,而$F(g)$就可以当作参数去训练,那么如何计算出前者呢?
类比数学上傅里叶的思路,是需要找到一组正交的函数基,那么同理现在对于图(graph) $f$ , 我们也需要找到一组定义在图上的正交基,而上文已经解释了图上的拉普拉斯矩阵$L$ 天然可谱分解,也就是对角化找到一组正交基
$$LU=\lambda U \,\,\,\,\,\,\,UU^{T}=UU^{-1}=I$$
同时可以证明$$\Delta e^{-iwt} = \frac{\partial e^{-iwt}}{\partial ^{2}t} = - w^2 e^{-iwt} $$
$e^{-iwt}$ 就是变换 $\Delta $ 的特征函数,$w$和特征值密切相关。而又因为$LU=\lambda U$,所以我们类比 $U$ 等同于 $e^{-iwt} $,也就是找到了图上的一组正交基($L$的特征向量)。
$$ F(\lambda _{l})=\hat{f}(\lambda _{l})=\sum_{i=1}^{N}f(i)u^{*}_{l}(i)$$
$f$ 是 graph 上的 $N$ 维向量,$f(i)$ 与graph的顶点一一对应,$u_{l}(i)$ 表示第 $l$ 个特征向量的第 $i$ 个分量。那么特征值(频率)$\lambda _{l}$ 下的,$f$ 的graph 傅里叶变换就是与 $\lambda _{l}$ 对于的特征向量 $u_{l}$ 进行内积运算。所以图$f*u^{*}_{l}$ 得到一个离散的值,如我们常见到的频域下的一个幅度值。
===>推广到矩阵下形式:

其中左边的是傅里叶变换,右边的$u_{i}(j) $表示第 $i$ 个特征向量的第 $j$ 维,所以图 $f$ 的傅里叶变换可以写成$$\hat{f} = U^{T} f$$,其中$U^T$是$L$的特征向量,也即是当前空间的一组基
图上的逆傅里叶变换

内容汇总:拉普拉斯矩阵/算子,傅里叶变换,GCN
前面介绍了傅里叶变换,又提到了拉普拉斯矩阵/算子,这和GCN有什么关系呢?
现在我们可以进一步考虑具体的卷积了,也就是 $$ f\star g =F^{-1}\begin{Bmatrix} F(f)\cdot F(g) \end{Bmatrix}$$
其中$$F(f) = \hat{f} = U^Tf$$
而 $F(g)$ 是卷积核$g$ 的傅里叶变换,我们可以写成对角线形式(为了矩阵相乘),$\bigl(\begin{smallmatrix}
\hat{h}(\lambda 1) & & &\\
& & \ddots & \\
& & &\hat{h}(\lambda n)
\end{smallmatrix}\bigr)$
其中
所以两者的傅里叶变换乘机为:
再照顾最外层的$F^{-1}{}$,那就是再左乘$U$:$$(f\star g)=U\begin{pmatrix}
&\hat{h}(\lambda_{1}) & \\
& &\ddots \\
& & &\hat{h}(\lambda_{n})
\end{pmatrix}U^{T}f$$

以上,我们算是完整得到了如何再图上做卷积的公式:先得到图的拉普拉斯矩阵$L$,得到$L$的对应特征向量$U$
图卷积的改进
上文我们已经知道了 $f\star g$的计算,但是其中一个问题就是$L$矩阵的特征向量$U$计算是费时的复杂度太高
所以提出如下近似多项式形式$$\hat{h}(\lambda_{l})\approx \sum_{K}^{j=0}\alpha _{j}\lambda^{j}_{l}$$
也就是:

最后卷积变成了:
$$y_{out}= \sigma(\sum_{j=0}^{K-1} \alpha _{j}L^{j}x)$$
这样就不需要进行特征值分解,直接使用$L^{j}$,即拉普拉斯矩阵的阶数
改进一
其实是进一步简化,将上式$L^{j}$使用切比雪夫展开式来近似,首先将上式$$\boldsymbol{g}_{\boldsymbol{\theta^{\prime}}}(\boldsymbol{\Lambda}) \approx \sum_{k=0}^K \theta_k^{\prime} T_k(\tilde{\boldsymbol{\Lambda}})$$
其中$\tilde{\boldsymbol{\Lambda}}=\frac{2}{\lambda_{max}}\boldsymbol{\Lambda}-\boldsymbol{I}_n$,$\lambda _{max}$ 是矩阵$L$的最大特征值(谱半径)。再利用切比雪夫多项式递推公式:
$$T_k(x)=2xT_{k-1}(x)-T_{k-2}(x)$$
$$T_0(x)=1,T_1(x)=x$$
所以有因为$L^{j}x$,那么
$$\begin{aligned} \boldsymbol{g(\wedge )}_{\boldsymbol{\theta^{\prime}}} * \boldsymbol{x} &\approx \boldsymbol{U} \sum_{k=0}^K \theta_k^{\prime} T_k(\tilde{\boldsymbol{\Lambda}}) \boldsymbol{U}^T \boldsymbol{x} \ \\ &= \sum_{k=0}^K \theta_k^{\prime} (\boldsymbol{U} T_k(\tilde{\boldsymbol{\Lambda}}) \boldsymbol{U}^T) \boldsymbol{x} \\ &=\sum_{k=0}^K \theta_k^{\prime} T_k(\tilde{\boldsymbol{L}}) \boldsymbol{x} \end{aligned}$$
其中$\tilde{\boldsymbol{L}}=\frac{2}{\lambda_{max}} \boldsymbol{L}- \boldsymbol{I}_n$
所以有$$\boldsymbol{y}_{output} = \sigma(\sum_{k=0}^K \theta_k^{\prime} T_k(\tilde{\boldsymbol{L}}) \boldsymbol{x})$$
改进二
主要对上式做了简化处理,取 $K=1$,设置$\lambda_{max}\approx 2$,带入简化模型:
$$\begin{aligned} \boldsymbol{g}_{\boldsymbol{\theta^{\prime}}} * \boldsymbol{x} &\approx \theta_0^{\prime} \boldsymbol{x} + \theta_1^{\prime}(\boldsymbol{L}- \boldsymbol{I}_n) \boldsymbol{x} \\ &= \theta_0^{\prime} \boldsymbol{x} - \theta_1^{\prime}(\boldsymbol{D}^{-1/2} \boldsymbol{W} \boldsymbol{D}^{-1/2}) \boldsymbol{x} \end{aligned}$$
上述用到了归一化的拉普拉斯矩阵,$$\boldsymbol{L}=\boldsymbol{D}^{-1/2}(\boldsymbol{D}-\boldsymbol{W})\boldsymbol{D}^{-1/2}=\boldsymbol{I_n}-\boldsymbol{D}^{-1/2} \boldsymbol{W} \boldsymbol{D}^{-1/2}$$
进一步假设$\theta_0^{\prime}=-\theta_1^{\prime}$
$$\boldsymbol{g}_{\boldsymbol{\theta^{\prime}}} * \boldsymbol{x} = \theta(\boldsymbol{I_n} + \boldsymbol{D}^{-1/2} \boldsymbol{W} \boldsymbol{D}^{-1/2}) \boldsymbol{x}$$
但是考虑到$\boldsymbol{I_n} + \boldsymbol{D}^{-1/2} \boldsymbol{W} \boldsymbol{D}^{-1/2}$的特征值范围是$[0, 2]$,会引起梯度消失问题(这点暂不清楚why),所以再修改为:
$$\boldsymbol{I_n} + \boldsymbol{D}^{-1/2} \boldsymbol{W} \boldsymbol{D}^{-1/2} \rightarrow \tilde{\boldsymbol{D}}^{-1/2}\tilde{\boldsymbol{W}} \tilde{\boldsymbol{D}}^{-1/2}$$
$\tilde{\boldsymbol{W}}=\boldsymbol{W}+\boldsymbol{I}_n$ 相当于邻接矩阵中对叫上加了$1$
最后就是论文中提到的形式:
$$\boldsymbol{Z}_{\mathbb{R}^{N \times F}} = (\tilde{\boldsymbol{D}}^{-1/2}\tilde{\boldsymbol{W}} \tilde{\boldsymbol{D}}^{-1/2})_{\mathbb{R}^{N \times N}} \boldsymbol{X}_{\mathbb{R}^{N \times C}} \ \ \boldsymbol{\Theta}_{\mathbb{R}^{C \times F}}$$
GCN定义
简单来说,网络的输入是$\mathcal{G}=(\mathcal{V}, \mathcal{E})$,可以得到$N\times D$的输入矩阵$X$($N$个顶点,每个结点$D$维),和邻接矩阵$A$,一层的输出是$Z$($N\times F$,F是输出结点的维度),其中每一层可以写成一个非线性函数:

一种简单的形式
直觉来说如果没有上文复杂的$ (\tilde{\boldsymbol{D}}^{-1/2}\tilde{\boldsymbol{W}} \tilde{\boldsymbol{D}}^{-1/2})_{\mathbb{R}^{N \times N}}$ 推导,那么我们会设计成如下形式,$A$为邻接矩阵,$H^{(l)}$为结点再$l$层的特征表示。

这种设计一个明显可以提到的地方就是$A$矩阵对角为0(导致每下一层丢失了自己的信息),所以可以改进为,$\tilde{A}=A+I$。还有一个不好的是,没有归一化$A$,会出现对$W$求导的时候,$A$的元素≥1,有梯度消失的隐患——那么就做一个归一化咯,得到$D^{-1}A$,(我觉得可以了),但是作者说:dynamics get more interesting when we use a symmetric normalization——所以使用了$D^{-\frac{1}{2}}AD^{-\frac{1}{2}}$的归一化形式。【$D^{-1}A$当然不等同于$D^{-1/2}AD^{-1/2}$,不要被两个$-1/2$就是$-1$迷惑。是容易验证的】
所以,直觉上,有了:$$f(H^{(l)}, A) = \sigma\left( \hat{D}^{-\frac{1}{2}}\hat{A}\hat{D}^{-\frac{1}{2}}H^{(l)}W^{(l)}\right) \, $$
但是理论的推导其实是从上文大篇幅的介绍而来的。
参考文献:
https://www.zhihu.com/question/54504471
http://tkipf.github.io/graph-convolutional-networks/
https://www.davidbieber.com/post/2019-05-10-weisfeiler-lehman-isomorphism-test/#
https://arxiv.org/abs/1609.02907
加载全部内容