大流量大负载的Kafka集群优化实战
李志涛 人气:3前言背景
算法优化改版有大需求要上线,在线特征dump数据逐步放量,最终达到现有Kafka集群5倍的流量,预计峰值达到万兆网卡80%左右(集群有几十个物理节点,有几PB的容量,网卡峰值流出流量会达到800MB左右/sec、写入消息QPS为100w+ msgs/sec)。上下游服务需要做扩容评估,提前做好容量规划,保障服务持续稳定运行
- L3层 dump特征 @xxx
- 1.依赖文章特征公共服务
- 2.依赖用户特征公共服务 前期可以一起共建
- 评估dump特征数据量 @xxx
- kafka新增Topic接收dump数据,评估kafka是否需要扩容 @xxx
- 新增拼接数据流支撑dump特征,需要评估新增机器 @xxx
经过对Kafka集群软硬件资源及利用率综合分析与评估,决定不扩容机器,完全可以应对流量扩大5倍的性能挑战
流量灰度时间表
- 2020-02-21放量进度 流量灰度10%
- 2020-02-24放量进度 流量灰度30%
- 2020-03-02放量进度 流量灰度50%
- 2020-03-02放量进度 流量灰度70%
- 2020-03-03放量进度 流量灰度85%
- 2020-03-05放量进度 流量灰度100%
优化纪实
预先优化在topics创建的情况下,没有流量时做的优化工作
本次在线特征dump放量topics列表如下:
onlinefeedback indata_str_onlinefeedback_mixxxbrowser indata_str_onlinefeedback_oppoxxxbrowser indata_str_onlinefeedback_3rd
......
violet集群的topics为indata_str_click_s3rd 和 indata_str_video_3rd_cjv 完成扩容并rebalance找出其他流量大的topics列表
以上topic都已经创建,但是只覆盖了少数磁盘挂载点,violet集群有21个节点252磁盘挂载点,但有些topics的partitions数量不到30,造成磁盘利用率不高,IO不均衡。
优化点:扩容partitions数量,覆盖更多磁盘挂载点
现状&优化旅程
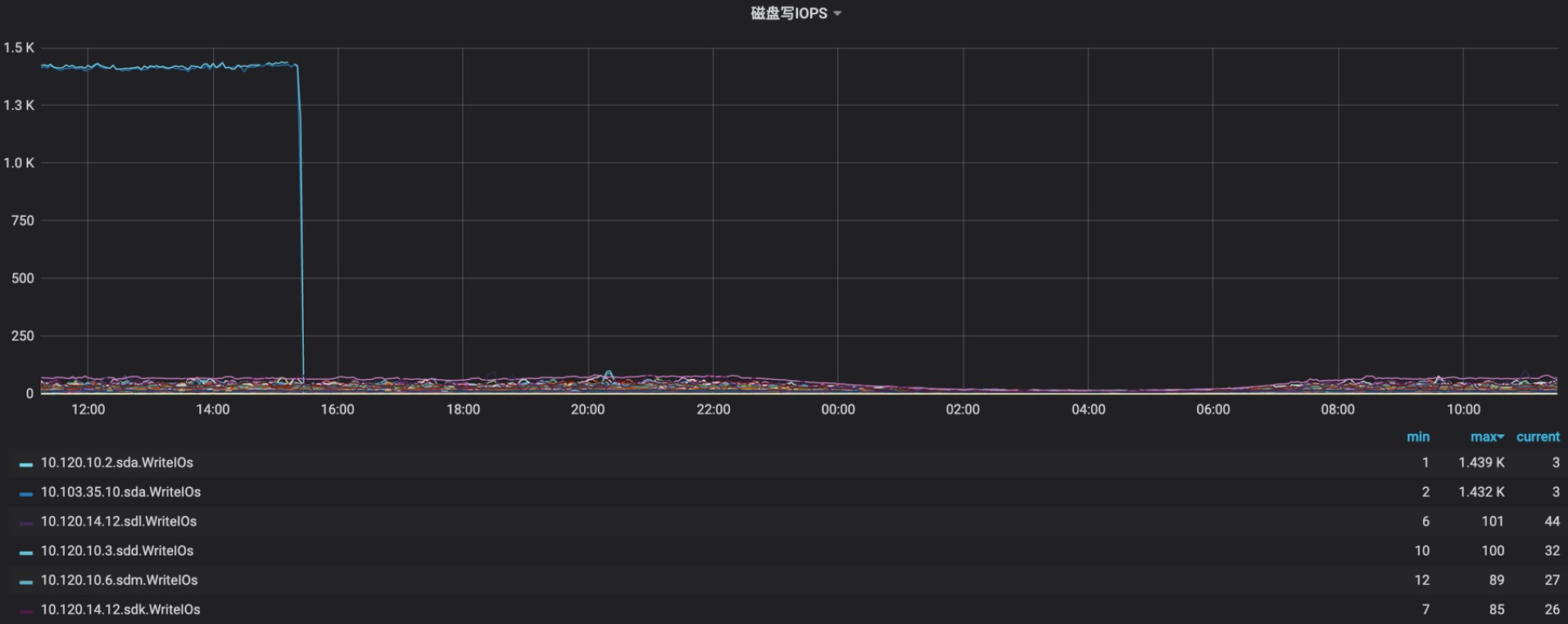
2020-02-21日 开始放量 topics均值流量小于20%,以下是放量后22~23日监控数据(读写IOPS、IOutil)



从以上数据分析,读写IOPS和ioutil极其不均衡,而且其中写IOPS走向极端上下两条线,后来查明原因是zk事务日志是实时单条commit,大量flink使用0.8.x版本,消费状态用zk存储造成的。另外还发现violet出口流量不均衡,高的70%、低的10%左右,当时flink消费出现阻塞现象,原因为上线前Flink未及时调大fetch.message.max.bytes的大小,引发violet集群部分broker网络出口流量飙升。
2020-02-26日 在线特征dump数据的topics均值放量到50%左右
优化zk集群写入性能从1.5k降到100以内,单事务写强制刷盘改为事务批量定期刷盘,在线Dump特征流量放量,排查violet集群线上隐患,由于消费端flink还是依赖的较低kafka-0.8.x版本,消费状态存储zk,导致写入频繁。此外zk的日志数据和事务数据目录从数据盘调整到系统盘,数据盘统一Kafka使用
客户端使用优化
serving使用kafka按key进行hash分配出现生产倾斜导致消费出现lag,和业务方商定修改消费逻辑解决此问题
2020-03-02日 在线特征dump放量75%,优化violet集群IO完成了80%以上,支撑在线特征100%放量应该没有问题,主要对10.120.14.11、10.103.35.7、10.103.35.2、10.120.10.8等4个节点IO削峰均衡化,热点挂载点IO峰值下降30~60%不等,操作策略如下:
- 扩容partitions,topics数据量大,partitions数量少,与业务沟通,扩partitions分配到低IO挂载点上
- 迁移partitions,partitions目录迁移和节点迁移,找出热点挂载点,分析出高读写的partitions,迁移到使用率低的磁盘挂载点上
- 调整topic保留时间,保证业务磁盘容量够用不浪费,与业务沟通,设置topics最小保留时间
优化前监控(3.02~3.03区间数据)

ioutil被打满,磁盘非常繁忙,响应变慢等待时间变长
优化后效果如下(3.06日区间数据)

红框部分IO持续高位为当时部分partition迁移导致的,可以忽略不计,由于2020-03-02、2020-03-03、2020-03-05持续放量直到100%,优化效果不明显
2020-03-04日 客户端参数优化
jstorm

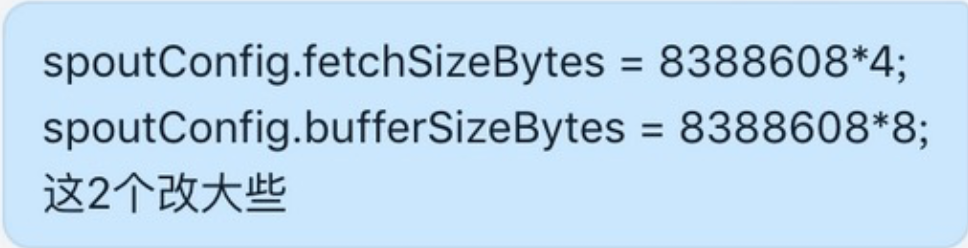
flink

03-06日 优化violet集群IO完成了95%以上,主要对10.120.14.11、10.103.35.7、10.103.35.2、10.103.35.3、10.103.35.10、10.120.10.2、10.120.10.3、10.120.10.5、10.120.10.6、10.120.10.7、10.120.10.8、10.120.10.9、10.120.10.11等13个节点IO削峰均衡化和磁盘使用率均衡化
下面是3.07~3.08日区间监控数据

3.08日 内时间点监控数据

3.08日 是周日 通过监控获知indata_str_onlinefeedback_mibrowser和indata_str_onlinefeedback_3rd-small消费流量比较大,需要做IO均衡化
indata_str_onlinefeedback_mibrowser每秒消费流量

indata_str_onlinefeedback_3rd-small每秒消费流量2.5GB

03.09日 截止下午17:00最近6小时数据(3.08日晚优化后效果)
内核参数优化
sudo blockdev --setra 16384 https://img.qb5200.com/download-x/dev/sdx sudo sh -c 'echo "4096" > /sys/block/sdx/queue/nr_requests' sudo sh -c 'echo "500" > /proc/sys/vmhttps://img.qb5200.com/download-x/dirty_writeback_centisecs' sudo sh -c 'echo "35" > /proc/sys/vmhttps://img.qb5200.com/download-x/dirty_ratio' sudo sh -c 'echo "5" > /proc/sys/vmhttps://img.qb5200.com/download-x/dirty_background_ratio'
sudo sh -c 'echo "2000" > /proc/sys/vmhttps://img.qb5200.com/download-x/dirty_expire_centisecs'
2020-03-11日 截止下午17:00最近6小时数据

能否完全磁盘IO均衡,比较困难,但还可以降低,因为这跟客户端生产/消费策略及消费历史数据有关,有些不可控因素。
2020-03-11日 kafka jvm heap优化 通过Kafka集群业务监控发现利用率低
减少jvm heap大小,让渡给pagecache做系统级数据缓存


另外Apache Kafka PMC大神王国璋回复:Kafka对内存要求不大,但是如果客户端版本较低会需要down convert version,这个过程是非常消耗CPU和内存的。原因是Producer向Kafka写入数据时,占用的堆外内存NIO Buffer,当消费读数据时,Kafka并不维护内存数据,因为使用系统函数sendfile将数据直接从磁盘文件复制到网卡设备中,而不需要经由应用程序之手。采集监控数据如下:
NIO Buffer

non-heap memory



早期jvm heap配置为32GB,后来优化为16GB,现在降到10GB,既保证了kafka进程稳定,又不浪费内存
优化能否一次性解决到位
性能优化能否预先或提前一次性全部搞定?
一般性topics的partitions扩容可以提前做,jvm heap也可以提前修改,但是有些参数就没法确定了,因为集群流量不大,负载不高,没有性能瓶颈,找不到更看不出瓶颈在哪里,优化了也看不出效果。以内核参数优化为例
Centos Performance Tuning

另外IO均衡化也是,集群流量压力不大,找不到需要IO均衡化的目标topics。只有流量逐步放大,才容易发现并识别问题topics
所以优化需要分类、分批、分场景、根据瓶颈、风险、效果、难易程度逐步推进。
从预先优化到全面优化
在线特征dump上线持续放量直至100%过程,我们做了大量调整和优化,它是一个循序渐进和不断完善的过程,不可能一蹴而就,回顾优化列表如下:
- 提前预先优化,预估大流量topics,扩容partitions覆盖更多磁盘挂载点
- 依赖服务zookeeper优化:单条事务消息刷盘改为批量刷盘
- 容器级优化:jvm heap利用率优化,从16GB降低大10GB,多余物理内存腾出给pagecache使用
- Kafka服务应用级优化
- 调大replica.fetch.wait.max.ms,降低replica fetch Request无效请求数,释放cpu计算和内存资源
- 增大replica.fetch.max.bytes,特别是kafka重启降低目标broker读IOPS
- 调大为zookeeper.session.timeout = 20000ms,避免网络抖动异常导致broker掉线
- 业务客户端优化
- jstorm
- 生产端:增大batch大小,降低Producer Request次数,给磁盘write IO降压
- 消费端:增大各个fetch参数,降低生产/消费速率,给磁盘read IO降压
- flink:增大并行度,结合异步和jvm参数
- jstorm
- 持续IO均衡化
- 扩容partitions,topics数据量大,partitions数量少,与业务沟通,扩partitions分配到低IO挂载点上
- 迁移partitions,partitions目录迁移和节点迁移,找出热点挂载点,分析出高读写的partitions,迁移到使用率低的磁盘挂载点上
- 调整topic保留时间,保证业务磁盘容量够用不浪费,与业务沟通,设置topics最小保留时间
- centos内核参数优化,目标是提升性能,保证稳定,同时充分利用pagecache和OS读写磁盘特性,用各种策略榨干取尽其资源
- 设置/sys/block/sdb/queue/read_ahead_kb
- 设置/sys/block/sdc/queue/nr_requests
- ...省略,了解更多请看 centos系统参数优化
partition迁移重点分析
要做到全面性、多维度、立体化的综合性能优化并达到预期理想效果,需要对相关Kafka、jvm、netty技术原理及OS等等(不限于)有相当理解。例如持续IO均衡化,就是需要运用综合手段来解决,利用管理平台、各类监控数据和shell命令找出触发瓶颈的topics及对应partitions,然后用工具迁移实现IO再平衡。

以上操作是反复循环进行的动作,观察-》分析-》操作-》查看效果-》再观察... 反复进行直至达到最佳状态
以下为partitions目录迁移bugs,经过分析,重启后解决,错误原因是broker应用内存中保留了partition目录迁移状态信息,重启后还原,但继续执行迁移需要重新操作

小结
- 预先优化,保证初期放量稳定,性能不打折
- 持续优化,采取多种手段拍平IO毛刺,同时兼顾磁盘容量均衡
- 想要达到最佳效果,需要对centOS底层TCP传输、网络处理、pagecache使用、IO调度、磁盘读写调度及刷盘机制有综合性全面的理解;要对Kafka的底层原理、各种配置参数项等具有深刻理解,可以进行Kafka集群参数调优,快速处理突发故障、恢复集群抖动和动态进行集群扩缩容等
博客引用地址:https://www.cnblogs.com/lizherui/p/12632988.html
加载全部内容