[斯坦福大学2014机器学习教程笔记]第四章-正规方程
不爱学习的Shirley 人气:0到目前为止,我们一直在使用梯度下降法来求解(通过一步步迭代来收敛到全局最小值)。相反地,正规方程提供的一种求解θ的解法。所以我们不再需要运行迭代算法,而是可以直接一次性求解θ的最优值。
事实上,正规方程也有优点,也有一些缺点。但在讲它的优缺点和如何使用正规方程之前,让我们先对这个算法有一个直观的理解。下面我们来看一个例子。
我们假设有一个非常简单的代价函数J(θ)。它就是一个实数θ的函数。所以现在假设θ只是一个标量,或者只是一个实数值,而函数是θ的二次函数。所以它的图像如下所示。
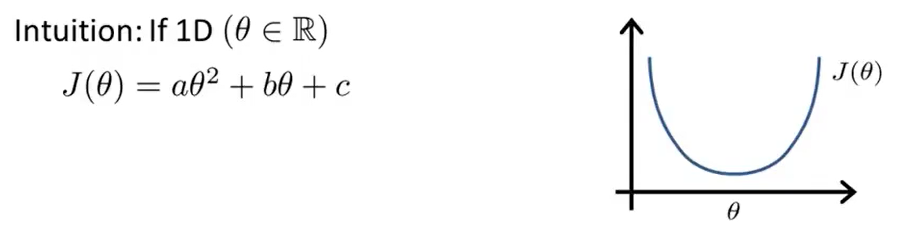
那么,怎么最小化一个二次函数呢?我们知道,我们可以对函数进行求导并让导数值为0。这样,我们就会求得使J(θ)最小的θ值。这是θ为实数的一个简单的例子。但是,我们通常碰到的问题中,θ不是一个实数,而是一个n+1维的参数向量,代价函数J是这个向量的函数,也就是θ0,θ1,θ2,……θn的函数。(J(θ0,θ1,……θn)=(1/2m)Σ(hθ(xi)-yi)2) [Q1:这里是m还是n呢?首先,我们要搞清楚n和m代表什么。n表示特征量的数目,m表示样本的数量。]
我们要如何最小化这个代价函数?
事实上,微积分告诉我们有一个方法能做到:就是逐个对参数θj求J的偏导数,然后把它们全部置零。如果我们这样做,并且求出θ0,θ1,……θn的值。这样就能得到最小化代价函数J的值。如果你真的做完微积分,并求出θ0,θ1,……θn的值,这个偏微分最终可能很复杂。
下面让我们来看一个例子。假如现在有m=4个训练样本。
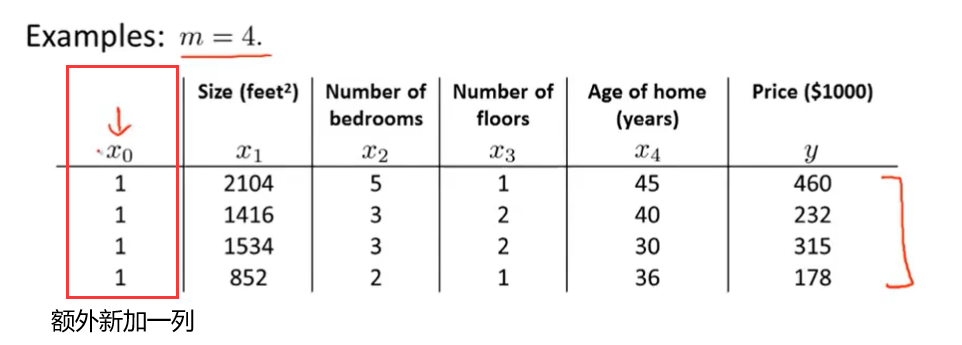
为了实现正规方程法,我们要做的就是在数据集中再加上一列,对应额外特征变量的x0,它的取值永远是1。接下来我们要做的,就是构建一个矩阵X。这个矩阵包括了所有训练样本的所有特征变量。我们要对y值进行类似的操作。我们取我们想要预测的值,然后构建一个向量y。所有,X是一个m*(n+1)的矩阵,y是一个m维向量。最后,我们用矩阵X和向量y计算θ值。设θ=(XTX)-1XTy,这样我们就能得到使代价函数最小化的θ。

在一般情况下,假设现在有m个训练样本,从(x(1),y(1))一直到(x(m),y(m))和n个特征变量。所有每个训练样本x(i)可能是一个如下所示的向量(一个n+1维特征向量)。我们接下来构建矩阵的方法也被称为设计矩阵。每个训练样本都给出一个像下图左侧一样的特征向量,我们要做的就是取第一个向量的转置,然后让第一个向量的转置称为设计矩阵X的第一行。同理,一直取到第m个向量的转置。

举个具体的例子,假如我们除了x0之外只有一个特征变量,那么我们的设计矩阵X如下图所示。
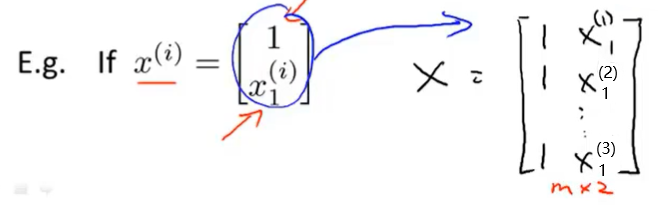
我们就能得到一个m*2维矩阵。这就是如何构建矩阵X。而向量y就是把所有结果放在一起得到一个m维向量。
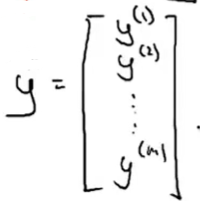
最后构建好设计矩阵X和向量y之后,我们就可以计算θ=(XTX)-1XTy。
下面我们就来讲一下θ=(XTX)-1XTy这个式子。
- 什么是(XTX)-1?
(XTX)-1是XTX的逆矩阵。具体的说,如果令A=XTX(XT是一个矩阵,XTX也是一个矩阵),那么(XTX)-1就是矩阵A的逆(A-1)。先计算XTX,再计算它的逆。
- 在Octave中,计算这个量的命令为:pinv(X' *X) *X' *y。在Octave中X'用来表示X的转置。(X' *X)计算的是XTX;pinv是计算逆的函数,pinv(X' *X)计算的是XTX的逆;然后再乘XT,再乘y。
- 根据数学知识,其实我们可以证出θ=(XTX)-1XTy这个式子算出的θ值,可以最小化线性回归的代价函数J(θ)。
还记得我们之前讲过的特征缩放吗?事实上,如果我们使用正规方程,我们就不需要特征缩放。如果你使用正规方程,即使你的特征量的取值如0≤x1≤1,0≤x2≤1000,0≤x3≤0.00001,也没有关系。但是,如果使用的是梯度下降法,特征缩放就非常重要了。
- 我们什么时候使用梯度下降法,什么时候使用正规方程法呢?下面我们讲一下关于它们的优缺点。
假如我们有m个训练样本,n个特征变量。
| 梯度下降法 | 正规方程法 |
|
缺点: 1.需要选择学习速率α。这通常表示要运行很多次来尝试不同的学习速率α。 2.需要更多次的迭代(取决于具体细节,计算可能会很慢)。 |
缺点: 正规方程法为了求解参数θ需要求解 (XTX)-1,而 XTX是一个n*n的矩阵,对于大多数计算应用来说,实现逆矩阵的计算代价以矩阵维度的三次方增长(O(n3))。因此,如果特征变量n的数目很大的话,计算这个逆矩阵的代价是非常大的。此时计算速度也会非常慢。 |
|
优点: 1.梯度下降法在特征变量很多的情况下,也能运行地很好,即使有上百万个特征变量。 |
优点: 1.不需要现在学习速率α,所有这就会很方便。 2.也不需要迭代,所以不需要画出J(θ)的曲线来检查收敛性,或者采取任何的额外步骤。 |
所以,如果n很大的话,使用梯度下降算法会比较好。如果n比较小的话,正规方程法可能会好一点。那么,什么算大什么算小呢?
如果n是上万的,那么这个时候应用正规方程法的求解速度会开始变得有点慢,此时可能梯度下降法会好点(但是也不是绝对的)。如果n远大于此,那么这个时候使用梯度下降法会好点。
加载全部内容