6-PACK: Category-level 6D Pose Tracker with Anchor-Based Keypoints
耗子梦见猫 人气:0论文地址:https://arxiv.org/abs/1910.10750v1
代码链接:https://sites.google.com/view/6packtracking
演示视频:https://www.bilibili.com/video/av95100434/
简介
作者提出了一种基于RGB-D的深度学习方法6PACK,能够实时的跟踪已知类别物体。通过学习用少量的三维关键点来简洁地表示一个物体,基于这些关键点,通过关键点匹配来估计物体在帧与帧之间的运动。这些关键点使用无监督端到端学习来实现有效的跟踪。实验表明该方法显著优于现有方法,并支持机器人执行简单的基于视觉的闭环操作任务。
问题的提出
在机器人抓取任务中,实时跟踪物体6D位姿的能力影响抓取任务的实施。现有的6D跟踪方法大部分是基于物体的三维模型进行的,有较高的准确性和鲁棒性。然而在现实环境中,很难获得物体的三维模型,所以作者提出开发一种类别级模型,能够跟踪特定类别从未见过的物体。
创新点
1、这种方法不需要已知物体的三维模型。相反,它通过新的anchor机制,类似于2D对象检测中使用的proposals方法,来避免定义和估计绝对6D位姿。
2、这些anchor为生成三维关键点提供了基础。与以往需要手动标注关键点的方法不同,提出了一种无监督学习方法,该方法可以发现最优的三维关键点集进行跟踪。
3、这些关键点用于简洁的表示物体,可以有效地估计相邻两帧之间位姿的差异。这种基于关键点的表示方法可以实现鲁棒的实时6D姿态跟踪。
核心思想
作者提出的模型使用RGB-D图像,基于之前位姿周围采样的anchors(红点),来鲁棒地检测和跟踪一组基于3D类别的关键点(黄色)。然后利用连续两帧中预测的关键点,通过最小二乘优化求解点集对齐的问题,计算出6D物体的位姿变化。
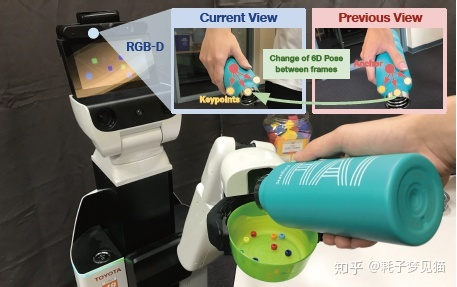
问题的定义
将类别级物体6D位姿跟踪定义为:物体在连续时间t−1和t之间的位姿变化问题。初始位姿是针对相同类别的所有目标物体定义的标准框架相对于相机框架的平移和旋转。例如,对于类别“相机”,将框架放置在物体的质心处,x轴指向相机物镜的方向,y轴指向上方。
将3D关键点定义为:在整个时间序列中几何和语义上一致的点。给定两个连续的输入帧,需要从两帧中预测匹配的关键点列表。基于刚体假设的基础,利用最小二乘优化来解决点集对齐问题,从而得到位姿的变化∆p。
模型
首先在预测物体实例的周围剪裁一个放大的体积,将其归一化为一个单元;在体积块上生成anchor网格;之后使用DenseFusion计算M个点的几何与颜色融合特征;根据距离将它们平均池化成N个anchor特征;注意力机制网络使用anchor特征来选择最接近质心的点;用质心生成一组有序的关键点。将这种关键点生成方法应用在前一帧和当前帧,得到两组有序的关键点来计算帧间的位姿变化。

6-PACK算法在预测位姿周围生成anchor网格的过程中使用了注意力机制。每个点用RGB-D点单独特征的距离加权和来表示体积。使用anchor信息在新的RGB-D框架中找到物体的粗略质心,并指导对其周围关键点的后续搜索,这比在无约束的三维空间中搜索关键点效率更高。
实验结果
作者采用的数据集是NOCS-REAL275,包含六个类别。通过对比三个模型的baseline来评估作者的方法。
NOCS:类别级物体6D位姿估计sota。
ICP:Open3D中中实现的标准点对面ICP算法。
KeypointNet:直接在三维空间中生成3D关键点。
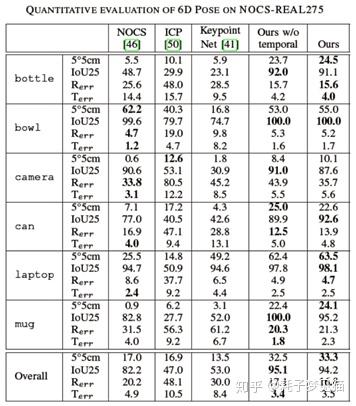
1)6-PACK指标5°5cm比NOCS高出15%以上,指标IoU25高出12%。说明与使用所有输入像素作为关键点的NOCS相比,6-PACK能够检测出最适合类别级6D跟踪的3D关键点。实验结果如下图所示:

其中,前两列为NOCS和6-PACK的定性对比,后两列为关键点匹配的结果。
2)6-PACK所有指标都优于KeypointNet,KeypointNet经常跟丢。作者的方法避免了丢失物体的轨迹(IoU25>94%),基于anchor的注意力机制提高了整体的跟踪性能。
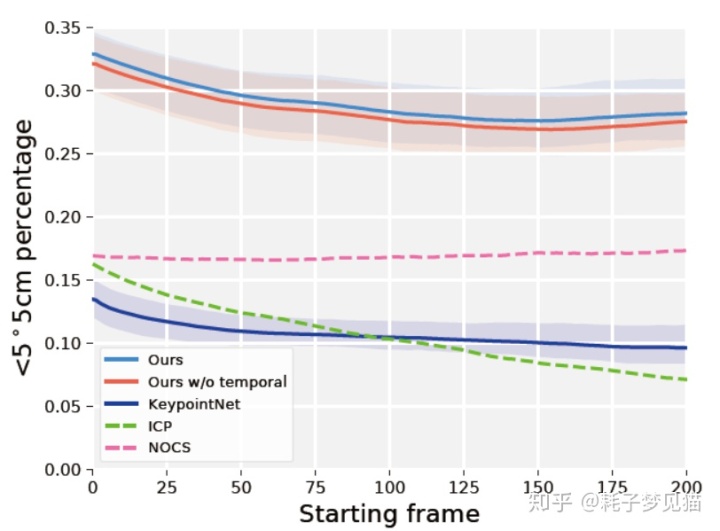
3)为了检验不同方法的鲁棒性和稳定性,作者计算了没有前x帧的平均性能。这样就能测量出初始位姿对性能的影响(接近初始位姿的帧很容易跟踪)。如下图,除了NOCS之外,所有方法的性能都有所下降,因为NOCS是位姿估计方法,而不是位姿跟踪方法。在整个过程中,6-PACK的性能比NOCS高出10%以上,并在初始帧100后停止下降。
4)作者在机器人上进行了实时测试,超过60%的试验中,成功地跟踪了目标(目标在可视范围内),而没有丢失。
加载全部内容
 爱之家商城
爱之家商城 氢松练
氢松练 Face甜美相机
Face甜美相机 花汇通
花汇通 走路宝正式版
走路宝正式版 天天运动有宝
天天运动有宝 深圳plus
深圳plus 热门免费小说
热门免费小说