我的Keras使用总结(2)——构建图像分类模型(针对小数据集)
战争热诚 人气:0Keras基本的使用都已经清楚了,那么这篇主要学习如何使用Keras进行训练模型,训练训练,主要就是“练”,所以多做几个案例就知道怎么做了。
在本文中,我们将提供一些面向小数据集(几百张到几千张图片)构造高效,实用的图像分类器的方法。
1,热身练习——CIFAR10 小图片分类示例(Sequential式)
示例中CIFAR10采用的是Sequential式来编译网络结构。代码如下:
# 要训练模型,首先得知道数据长啥样
from __future__ import print_function
import keras
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D
batch_size = 32
num_classes = 10
epochs = 100
data_augmentation = True
# 数据载入
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 多分类标签生成,我们将其由单个标签,生成一个热编码的形式
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# 网络结构配置
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same',
input_shape=x_train.shape[1:])) # (32, 32, 3)
model.add(Activation('relu'))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same'))
model.add(Activation('relu'))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512))
model.add(Activation('relu'))
model.add(Dropout(num_classes))
model.add(Activation('softmax'))
# 训练参数设置
# initiate RMSprop optimizer
opt = keras.optimizers.rmsprop(lr=0.0001, decay=1e-6)
# Let's train the model using RMSprop
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
# 生成训练数据
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
if not data_augmentation:
print("Not using data augmentation")
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test),
shuffle=True)
else:
print("Using real-time data augmentation")
# this will do preprocessing and realtime data augmentation
datagen = ImageDataGenerator(
featurewise_center=False, # set input mean to 0 over the dataset
samplewise_center=False, # set each sample mean to 0
featurewise_std_normalization=False, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range=0, # randomly rotate images in the range (degrees, 0 to 180)
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=True, # randomly flip images
vertical_flip=False) # randomly flip images
# Compute quantities required for feature-wise normalization
# (std, mean, and principal components if ZCA whitening is applied).
datagen.fit(x_train)
# fit训练
# fit the model on batches generated by datagen.flow()
model.fit_generator(datagen.flow(x_train, y_train,
batch_size=batch_size),
epochs=epochs,
validation_data=(x_test, y_test))
截取部分epoch的运行结果:
49056/50000 [============================>.] - ETA: 4s - loss: 0.6400 - acc: 0.7855 49088/50000 [============================>.] - ETA: 4s - loss: 0.6399 - acc: 0.7855 49120/50000 [============================>.] - ETA: 3s - loss: 0.6401 - acc: 0.7855 49152/50000 [============================>.] - ETA: 3s - loss: 0.6399 - acc: 0.7855 49184/50000 [============================>.] - ETA: 3s - loss: 0.6398 - acc: 0.7856 49216/50000 [============================>.] - ETA: 3s - loss: 0.6397 - acc: 0.7856 49248/50000 [============================>.] - ETA: 3s - loss: 0.6395 - acc: 0.7856 49280/50000 [============================>.] - ETA: 3s - loss: 0.6396 - acc: 0.7857 49312/50000 [============================>.] - ETA: 3s - loss: 0.6398 - acc: 0.7856 49344/50000 [============================>.] - ETA: 2s - loss: 0.6404 - acc: 0.7856 49376/50000 [============================>.] - ETA: 2s - loss: 0.6404 - acc: 0.7856 49408/50000 [============================>.] - ETA: 2s - loss: 0.6403 - acc: 0.7856 49440/50000 [============================>.] - ETA: 2s - loss: 0.6404 - acc: 0.7856 49472/50000 [============================>.] - ETA: 2s - loss: 0.6404 - acc: 0.7856 49504/50000 [============================>.] - ETA: 2s - loss: 0.6405 - acc: 0.7855 49536/50000 [============================>.] - ETA: 2s - loss: 0.6406 - acc: 0.7855 49568/50000 [============================>.] - ETA: 1s - loss: 0.6407 - acc: 0.7855 49600/50000 [============================>.] - ETA: 1s - loss: 0.6407 - acc: 0.7854 49632/50000 [============================>.] - ETA: 1s - loss: 0.6410 - acc: 0.7854 49664/50000 [============================>.] - ETA: 1s - loss: 0.6409 - acc: 0.7853 49696/50000 [============================>.] - ETA: 1s - loss: 0.6410 - acc: 0.7853 49728/50000 [============================>.] - ETA: 1s - loss: 0.6412 - acc: 0.7852 49760/50000 [============================>.] - ETA: 1s - loss: 0.6413 - acc: 0.7852 49792/50000 [============================>.] - ETA: 0s - loss: 0.6413 - acc: 0.7852 49824/50000 [============================>.] - ETA: 0s - loss: 0.6413 - acc: 0.7852 49856/50000 [============================>.] - ETA: 0s - loss: 0.6414 - acc: 0.7851 49888/50000 [============================>.] - ETA: 0s - loss: 0.6415 - acc: 0.7851 49920/50000 [============================>.] - ETA: 0s - loss: 0.6415 - acc: 0.7851 49952/50000 [============================>.] - ETA: 0s - loss: 0.6415 - acc: 0.7850 49984/50000 [============================>.] - ETA: 0s - loss: 0.6415 - acc: 0.7850 50000/50000 [==============================] - 228s 5ms/step - loss: 0.6414 - acc: 0.7851 - val_loss: 0.6509 - val_acc: 0.7836 Epoch 55/200
其实跑到第55个epoch,准确率已经达到了 0.785了,后面肯定能达到八九十,我这里就暂停了,让我电脑歇一歇,跑一天了。其实跑这个就是证明模型没有问题,而且我的代码可以运行,仅此而已。
2,针对小数据集的深度学习
本节实验基于如下配置:
- 2000张训练图片构成的数据集,一共有两个类别,每类1000张
- 安装有Keras,Scipy,PIL的机器,如果有GPU就更好的了,但是因为我们面对的是小数据集,没有也可以
- 数据集存放格式如下:

这份数据集来自于Kaggle,元数据集有12500只猫和12500只狗,我们只取了各个类的前500张图片,另外还从各个类中取了1000张额外图片用于测试。
下面是数据集的一些示例图片,图片的数量非常少,这对于图像分类来说是个大麻烦。但现实是,很多真实世界图片获取是很困难的,我们能得到的样本数目确实很有限(比如医学图像,每张正样本都意味着一个承受痛苦的病人)对数据科学家而言,我们应该有能够榨取少量数据的全部价值的能力,而不是简单的伸手要更多的数据。

在Kaggle的猫狗大战竞赛中,参赛者通过使用现代的深度学习技术达到了98%的正确率,我们只使用了全部数据的8%,因此这个问题对我们来说更难。
经常听说的一种做法是,深度学习只有在你拥有海量数据的时候才有意义。虽然这种说法并不是完全不对,但却具有较强的误导性。当然,深度学习强调从数据中自动学习特征的能力,没有足够的训练样本,这几乎是不可能的。尤其是当输入的数据维度很高(如图片)时。然而,卷积神经网络作为深度学习的支柱,被设计为针对“感知”问题最好的模型之一(如图像分类问题),即使只有很少的数据,网络也能把特征学的不错。针对小数据集的神经网络依然能够得到合理的结果,并不需要任何手工的特征工程。一言以蔽之,卷积神经网络大法好!另一方面,深度学习模型天然就具有可重用的特性:比方说,你可以把一个在大规模数据上训练好的图像分类或语音识别的模型重用在另一个很不一样的问题上,而只需要做有限的一点改动。尤其是在计算机视觉领域,许多预训练的模型现在都被公开下载,并重用在其他问题上以提升在小数据集上的性能。
2.1 数据预处理与数据提升
为了尽量利用我们有限的训练数据,我们将通过一系列变换堆数据进行提升,这样我们的模型将看不到任何两张完全相同的图片,这有利于我们抑制过拟合,使得模型的泛化能力更好。
在Keras中,这个步骤可以通过keras.preprocessing.image.ImageDataGenerator来实现,也就是图片预处理生成器,这个类使你可以:
- 在训练过程中,设置要施行的随机变换。
- 通过 .flow 或者 .flow_from_directory(directory) 方法实例化一个针对图像 batch 的生成器,这些生成器可以被用作 Keras模型相关方法的输入,如 fit_generator,evaluate_generator 和 predict_generator。
datagen = ImageDataGenerator() datagen.fit(x_train)
生成器初始化 datagen,生成 datagen.fit,计算依赖于数据的变化所需要的统计信息。
最终把数据需要按照每个batch进行划分,这样就可以送到模型进行训练了
datagen.flow(x_train, y_train, batch_size=batch_size)
接收numpy数组和标签为参数,生成经过数据提升或标准化后的batch数据,并在一个无限循环中不断的返回batch数据。
具体的图片生成器函数ImageDataGenerator:(他可以用以生成一个 batch的图像数据,支持实时数据提升,训练时该函数会无限生成数据,直到达到规定的 epoch次数为止。)

参数意思:


方法有三个,分别是 fit() flow() flow_from_directory() 下面继续截图Keras官网的内容:




现在我们看一个例子:
#_*_coding:utf-8_*_
'''
使用ImageDataGenerator 来生成图片,并将其保存在一个临时文件夹中
下面感受一下数据提升究竟做了什么事情。
'''
import os
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
datagen = ImageDataGenerator(
rotation_range=40, # 是一个0~180的度数,用来指定随机选择图片的角度
width_shift_range=0.2, # 水平方向的随机移动程度
height_shift_range=0.2, # 竖直方向的随机移动程度
rescale=1./255, #将在执行其他处理前乘到整个图像上
shear_range=0.2, # 用来进行剪切变换的程度,参考剪切变换
zoom_range=0.2, # 用来进行随机的放大
horizontal_flip=True, # 随机的对图片进行水平翻转,此参数用于水平翻转不影响图片语义的时候
fill_mode='nearest' # 用来指定当需要进行像素填充,如旋转,水平和竖直位移的时候
)
pho_path = 'timg.jpg'
img = load_img(pho_path) # this is a PIL image
x = img_to_array(img) # this is a Numpy array with shape (3, 150, 150)
x = x.reshape((1, ) + x.shape) # this is a Numpy array with shape (1, 3, 150, 150)
if not os.path.exists('preview'):
os.mkdir('preview')
i = 0
for batch in datagen.flow(x, batch_size=1,
save_to_dir='preview', save_prefix='durant', save_format='jpg'):
i += 1
if i > 20:
break # otherwise the generator would loop indefitely
这是原图:

下面是一张图片被提升以后得到的多个结果:


下面粘贴三个官网的例子:
1,使用.flow() 的例子

2,使用.flow_from_directory(directory)

3,同时变换图像和 mask
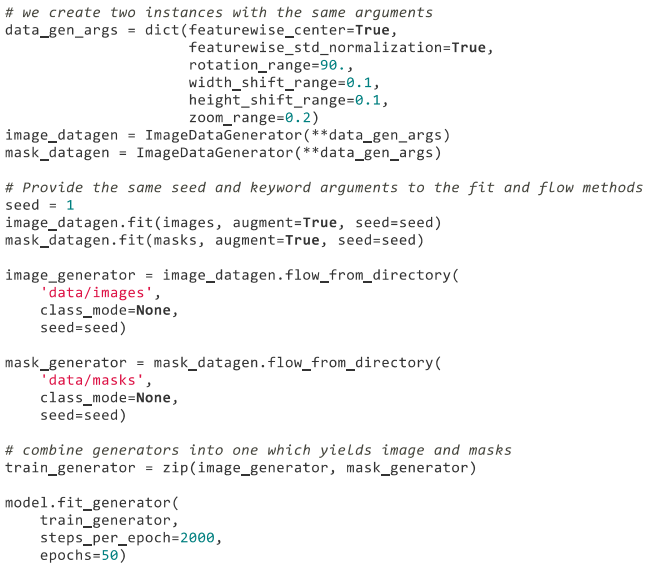
2.2 在小数据集上训练神经网络:40行代码达到80%的准确率
进行图像分类的正确工具是卷积网络,所以我们来试试用卷积神经网络搭建一个初级的模型。因为我们的样本数很少,所以我们应该对过拟合的问题多加注意。当一个模型从很少的样本中学习到不能推广到新数据的模式时,我们称为出现了过拟合的问题。过拟合发生时,模型试图使用不相关的特征来进行预测。例如,你有三张伐木工人的照片,有三张水手的照片。六张照片中只有一个伐木工人戴了帽子,如果你认为戴帽子是能将伐木工人与水手区别开的特征,那么此时你就是一个差劲的分类器。
数据提升是对抗过拟合问题的一个武器,但还不够,因为提升过的数据让然是高度相关的。对抗过拟合的你应该主要关注的时模型的“熵容量”——模型允许存储的信息量。能够存储更多信息的模型能够利用更多的特征取得更好的性能,但也有存储不相关特征的风险。另一方面,只能存储少量信息的模型会将存储的特征主要集中在真正相关的特征上,并有更好的泛华性能。
有很多不同的方法来调整模型的“熵容量”,常见的一种选择是调整模型的参数数目,即模型的层数和每层的规模。另一种方法时对权重进行正则化约束,如L1或L2这种约束会使模型的权重偏向较小的值。
在我们的模型里,我们使用了很小的卷积网络,只有很少的几层,每层的滤波器数目也不多。再加上数据提升和Dropout,就差不多了。Dropout通过防止一层看到两次完全一样的模式来防止过拟合,相当于也是数据提升的方法。(你可以说Dropout和数据提升都在随机扰乱数据的相关性)
下面展示的代码是我们的第一个模型,一个很简单的3层卷积加上ReLU激活函数,再接max-pooling层,这个结构和Yann LeCun 在1990 年发布的图像分类器很相似(除了ReLU)
这个实验的代码如下:
#_*_coding:utf-8_*_
from keras.models import Sequential
from keras.layers import Convolution2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.preprocessing.image import ImageDataGenerator
from keras import backend as K
K.set_image_dim_ordering('th')
# 简单的三层卷积加上ReLU激活函数,再接一个max-pooling层
model = Sequential()
model.add(Convolution2D(32, 3, 3, input_shape=(3, 150, 150)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(32, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Convolution2D(64, 3, 3))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
#the model so far outputs 3D feature maps (height, width, features)
# 然后我们接了两个全连接网络,并以单个神经元和Sigmoid激活结束模型
# 这种选择会产生一个二分类的结果,与这种配置项适应,损失函数选择binary_crossentropy
# this converts our 3D feature maps to 1D feature vectors
model.add(Flatten())
# 添加隐藏层神经元的数量和激活函数
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# next read data
# 使用 .flow_from_directory() 来从我们的jpgs图片中直接产生数据和标签
# this is the augmentation configuration we will use for training
train_datagen = ImageDataGenerator(
rescale=1./255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True
)
# this is the augmentation configuration we will use for testing only rescaling
test_datagen = ImageDataGenerator(rescale=1./255)
# this is a generator that will read pictures found in subfliders
# of 'data/train'. and indefinitely generate batches of augmented image data
train_generator = train_datagen.flow_from_directory(
'DogsVSCats/train', # this is the target directory
target_size=(150, 150), # all image will be resize to 150*150
batch_size=32,
class_mode='binary'
) # since we use binary_crossentropy loss,we need binary labels
# this is a similar generator, for validation data
validation_generator = test_datagen.flow_from_directory(
'DogsVSCats/valid', # this is the target directory
target_size=(150, 150), # all image will be resize to 150*150
batch_size=32,
class_mode='binary'
)
# 然后我们可以用这个生成器来训练网络了。
model.fit_generator(
train_generator,
samples_per_epoch=2000,
nb_epoch=50,
validation_data=validation_generator,
nb_val_samples=800
)
model.save_weights('first_try.h5') #always save your weights after training or duraing trianing
部分结果如下:
Epoch 1/50 62/62 [==============================] - 66s 1s/step - loss: 0.7043 - acc: 0.5238 - val_loss: 0.6798 - val_acc: 0.5015 Epoch 2/50 62/62 [==============================] - 63s 1s/step - loss: 0.6837 - acc: 0.5762 - val_loss: 0.6481 - val_acc: 0.6837 Epoch 3/50 62/62 [==============================] - 63s 1s/step - loss: 0.6465 - acc: 0.6503 - val_loss: 0.5826 - val_acc: 0.6827 Epoch 4/50 62/62 [==============================] - 63s 1s/step - loss: 0.6077 - acc: 0.6884 - val_loss: 0.5512 - val_acc: 0.7447 Epoch 5/50 62/62 [==============================] - 63s 1s/step - loss: 0.5568 - acc: 0.7088 - val_loss: 0.5127 - val_acc: 0.7357 Epoch 6/50 62/62 [==============================] - 63s 1s/step - loss: 0.5469 - acc: 0.7241 - val_loss: 0.4962 - val_acc: 0.7578 Epoch 7/50 62/62 [==============================] - 63s 1s/step - loss: 0.5236 - acc: 0.7446 - val_loss: 0.4325 - val_acc: 0.8028 Epoch 8/50 62/62 [==============================] - 63s 1s/step - loss: 0.4842 - acc: 0.7751 - val_loss: 0.4710 - val_acc: 0.7758 Epoch 9/50 62/62 [==============================] - 63s 1s/step - loss: 0.4693 - acc: 0.7726 - val_loss: 0.4383 - val_acc: 0.7808 Epoch 10/50 62/62 [==============================] - 63s 1s/step - loss: 0.4545 - acc: 0.7952 - val_loss: 0.3806 - val_acc: 0.8298 Epoch 11/50 62/62 [==============================] - 63s 1s/step - loss: 0.4331 - acc: 0.8031 - val_loss: 0.3781 - val_acc: 0.8248 Epoch 12/50 62/62 [==============================] - 63s 1s/step - loss: 0.4178 - acc: 0.8162 - val_loss: 0.3146 - val_acc: 0.8799 Epoch 13/50 62/62 [==============================] - 63s 1s/step - loss: 0.3926 - acc: 0.8275 - val_loss: 0.3030 - val_acc: 0.8739 Epoch 14/50 62/62 [==============================] - 63s 1s/step - loss: 0.3854 - acc: 0.8295 - val_loss: 0.2835 - val_acc: 0.8929 Epoch 15/50 62/62 [==============================] - 63s 1s/step - loss: 0.3714 - acc: 0.8303 - val_loss: 0.2882 - val_acc: 0.8879 Epoch 16/50 62/62 [==============================] - 63s 1s/step - loss: 0.3596 - acc: 0.8517 - val_loss: 0.3727 - val_acc: 0.8228 Epoch 17/50 62/62 [==============================] - 63s 1s/step - loss: 0.3369 - acc: 0.8568 - val_loss: 0.3638 - val_acc: 0.8328 Epoch 18/50 62/62 [==============================] - 63s 1s/step - loss: 0.3249 - acc: 0.8608 - val_loss: 0.2589 - val_acc: 0.8819 Epoch 19/50 62/62 [==============================] - 63s 1s/step - loss: 0.3348 - acc: 0.8548 - val_loss: 0.2273 - val_acc: 0.9079 Epoch 20/50 62/62 [==============================] - 63s 1s/step - loss: 0.2979 - acc: 0.8754 - val_loss: 0.1737 - val_acc: 0.9389 Epoch 21/50 62/62 [==============================] - 63s 1s/step - loss: 0.2980 - acc: 0.8686 - val_loss: 0.2198 - val_acc: 0.9189 Epoch 22/50 62/62 [==============================] - 63s 1s/step - loss: 0.2789 - acc: 0.8815 - val_loss: 0.2040 - val_acc: 0.9109 Epoch 23/50 62/62 [==============================] - 63s 1s/step - loss: 0.2793 - acc: 0.8891 - val_loss: 0.1388 - val_acc: 0.9479 Epoch 24/50 62/62 [==============================] - 63s 1s/step - loss: 0.2799 - acc: 0.8865 - val_loss: 0.1565 - val_acc: 0.9419 Epoch 25/50 62/62 [==============================] - 63s 1s/step - loss: 0.2513 - acc: 0.8949 - val_loss: 0.1467 - val_acc: 0.9510 Epoch 26/50 62/62 [==============================] - 63s 1s/step - loss: 0.2551 - acc: 0.9029 - val_loss: 0.1281 - val_acc: 0.9520 Epoch 27/50 62/62 [==============================] - 63s 1s/step - loss: 0.2387 - acc: 0.8961 - val_loss: 0.1590 - val_acc: 0.9409 Epoch 28/50 62/62 [==============================] - 63s 1s/step - loss: 0.2449 - acc: 0.9054 - val_loss: 0.1250 - val_acc: 0.9580 Epoch 29/50 62/62 [==============================] - 63s 1s/step - loss: 0.2158 - acc: 0.9218 - val_loss: 0.0881 - val_acc: 0.9780 Epoch 30/50 62/62 [==============================] - 63s 1s/step - loss: 0.2286 - acc: 0.9158 - val_loss: 0.1012 - val_acc: 0.9660 Epoch 31/50 62/62 [==============================] - 63s 1s/step - loss: 0.2017 - acc: 0.9181 - val_loss: 0.1109 - val_acc: 0.9570 Epoch 32/50 62/62 [==============================] - 63s 1s/step - loss: 0.1957 - acc: 0.9213 - val_loss: 0.1160 - val_acc: 0.9560 Epoch 33/50 62/62 [==============================] - 63s 1s/step - loss: 0.2046 - acc: 0.9249 - val_loss: 0.0600 - val_acc: 0.9840 Epoch 34/50 62/62 [==============================] - 63s 1s/step - loss: 0.1967 - acc: 0.9206 - val_loss: 0.0713 - val_acc: 0.9790 Epoch 35/50 62/62 [==============================] - 63s 1s/step - loss: 0.2238 - acc: 0.9153 - val_loss: 0.3123 - val_acc: 0.8929 Epoch 36/50 62/62 [==============================] - 63s 1s/step - loss: 0.1841 - acc: 0.9317 - val_loss: 0.0751 - val_acc: 0.9740 Epoch 37/50 62/62 [==============================] - 63s 1s/step - loss: 0.1890 - acc: 0.9279 - val_loss: 0.1030 - val_acc: 0.9700
这个模型在50个epoch后的准确率为 79%~81%。(但是我的准确率在38个epoch却达到了惊人的92%,也是恐怖)没有做模型和超参数的优化。
注意这个准确率的变化可能会比较大,因为准确率本来就是一个变化较高的评估参数,而且我们的训练样本比较少,所以比较好的验证方法就是使用K折交叉验证,但每轮验证中我们都要训练一个模型。
2.3 Keras报错:ValueError: Negative dimension size caused by subtracting 2 ...
(解决方法参考:https://blog.csdn.net/akadiao/articlehttps://img.qb5200.com/download-x/details/80531070)
使用Keras时遇到如下错误:
ValueError: Negative dimension size caused by subtracting 2 from 1 for 'block2_pool/MaxPool' (op: 'MaxPool') with input shapes: [?,1,75,128].
解决方法:这个是图片的通道顺序问题。
以128*128的RGB图像为例 channels_last应该将数据组织为(128, 128, 3),而channels_first将数据组织为(3, 128, 128)。
通过查看函数 set_image_dim_ording():
def set_image_dim_ordering(dim_ordering):
"""Legacy setter for `image_data_format`.
# Arguments
dim_ordering: string. `tf` or `th`.
# Raises
ValueError: if `dim_ordering` is invalid.
"""
global _IMAGE_DATA_FORMAT
if dim_ordering not in {'tf', 'th'}:
raise ValueError('Unknown dim_ordering:', dim_ordering)
if dim_ordering == 'th':
data_format = 'channels_first'
else:
data_format = 'channels_last'
_IMAGE_DATA_FORMAT = data_format
可知,tf对应原本的 channels_last,th对应 channels_first,因此添加下面代码即可解决问题:
from keras import backend as K
K.set_image_dim_ordering('th')
这样保证要使用的通道顺序和配置的通道顺序一致即可。
3,多分类简易网络结构(Sequential)
官方文档是猫狗二分类,我们上面已经做过了,此时我们将其变为一个五分类,由于追求效率,从网上找来一个很小的数据集,数据来源:Caffe学习系列(12):训练和测试自己的图片
数据描述:
共有500张图片,分为大巴车、恐龙、大象、鲜花和马五个类,每个类100张。下载地址:http://pan.baidu.com/s/1nuqlTnN
编号分别以3,4,5,6,7开头,各为一类。我从其中每类选出20张作为测试,其余80张作为训练。因此最终训练图片400张,测试图片100张,共5类。如下图:
(注意,这里需要自己将图片分为五类,包括训练集和测试集)
3.1 载入与模型网络构建
代码如下:
# 载入与模型网络构建
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
def built_model():
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(150, 150, 3)))
# filter大小为3*3 数量为32个,原始图像大小3,150 150
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
# this converts ours 3D feature maps to 1D feature vector
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(5)) # 几个分类就几个dense
model.add(Activation('softmax')) # 多分类
3.2 图像预处理
下面我们开始准备数据,使用 .flow_from_directory() 来从我们的jpgs图片中直接产生数据和标签。
其中值得留意的是:
- ImageDataGenerate:用以生成一个 batch 的图像数据,支持实时数据提升。训练时该函数会无限生成数据,直到达到规定的epoch次数为止。
- flow_from_directory(directory):以文件夹路径为参数,生成经过数据提升/归一化后的数据,在一个无限循环中无限产生batch数据。
def generate_data():
'''
flow_from_directory是计算数据的一些属性值,之后再训练阶段直接丢进去这些生成器。
通过这个函数来准确数据,可以让我们的jpgs图片中直接产生数据和标签
:return:
'''
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True
)
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
'data/mytrain',
target_size=(150, 150), # all images will be resized to 150*150
batch_size=32,
class_mode='categorical' # 多分类
)
validation_generator = test_datagen.flow_from_directory(
'data/mytest',
target_size=(150, 150),
batch_size=32,
class_mode='categorical' # 多分类
)
return train_generator, validation_generator
3.3 载入与模型网络构建
代码如下:(和上面两分类的没多少差别)
def built_model():
# 载入与模型网络构建
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(150, 150, 3)))
# filter大小为3*3 数量为32个,原始图像大小3,150 150
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
# this converts ours 3D feature maps to 1D feature vector
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(5)) # 几个分类就几个dense
model.add(Activation('softmax')) # 多分类
# model.compile(loss='binary_corssentropy',
# optimizer='rmsprop',
# metrics=['accuracy'])
# 优化器rmsprop:除学习率可调整外,建议保持优化器的其他默认参数不变
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.summary()
return model
3.4 训练
代码如下:
def train_model(model=None):
if model is None:
model = built_model()
model.fit_generator(
train_generator,
# sampels_per_epoch 相当于每个epoch数据量峰值,
# 每个epoch以经过模型的样本数达到samples_per_epoch时,记一个epoch结束
samples_per_epoch=2000,
nb_epoch=50,
validation_data=validation_generator,
nb_val_samples=800
)
model.save_weights('first_try_animal.h5')
3.5 部分结果展示和所有源码
部分结果如下(这里仅展示一个完整的epoch训练数据):
Epoch 50/50 1/62 [..............................] - ETA: 1:10 - loss: 0.4921 - acc: 0.9062 2/62 [..............................] - ETA: 1:13 - loss: 0.2460 - acc: 0.9531 3/62 [>.............................] - ETA: 1:12 - loss: 0.1640 - acc: 0.9688 4/62 [>.............................] - ETA: 1:02 - loss: 0.1230 - acc: 0.9766 5/62 [=>............................] - ETA: 1:02 - loss: 0.0985 - acc: 0.9812 6/62 [=>............................] - ETA: 1:02 - loss: 0.0821 - acc: 0.9844 7/62 [==>...........................] - ETA: 1:02 - loss: 0.0704 - acc: 0.9866 8/62 [==>...........................] - ETA: 1:00 - loss: 0.0616 - acc: 0.9883 9/62 [===>..........................] - ETA: 59s - loss: 0.0547 - acc: 0.9896 10/62 [===>..........................] - ETA: 59s - loss: 0.0493 - acc: 0.9906 11/62 [====>.........................] - ETA: 59s - loss: 0.0448 - acc: 0.9915 12/62 [====>.........................] - ETA: 58s - loss: 0.0412 - acc: 0.9922 13/62 [=====>........................] - ETA: 57s - loss: 0.0380 - acc: 0.9928 14/62 [=====>........................] - ETA: 55s - loss: 0.0363 - acc: 0.9933 15/62 [======>.......................] - ETA: 54s - loss: 0.0339 - acc: 0.9938 16/62 [======>.......................] - ETA: 53s - loss: 0.0318 - acc: 0.9941 17/62 [=======>......................] - ETA: 51s - loss: 0.0316 - acc: 0.9945 18/62 [=======>......................] - ETA: 50s - loss: 0.0298 - acc: 0.9948 19/62 [========>.....................] - ETA: 49s - loss: 0.0283 - acc: 0.9951 20/62 [========>.....................] - ETA: 48s - loss: 0.0268 - acc: 0.9953 21/62 [=========>....................] - ETA: 47s - loss: 0.0259 - acc: 0.9955 22/62 [=========>....................] - ETA: 46s - loss: 0.0247 - acc: 0.9957 23/62 [==========>...................] - ETA: 45s - loss: 0.0236 - acc: 0.9959 24/62 [==========>...................] - ETA: 44s - loss: 0.0227 - acc: 0.9961 25/62 [===========>..................] - ETA: 42s - loss: 0.0218 - acc: 0.9962 26/62 [===========>..................] - ETA: 42s - loss: 0.0209 - acc: 0.9964 27/62 [============>.................] - ETA: 41s - loss: 0.0202 - acc: 0.9965 28/62 [============>.................] - ETA: 40s - loss: 0.0194 - acc: 0.9967 29/62 [=============>................] - ETA: 39s - loss: 0.0188 - acc: 0.9968 30/62 [=============>................] - ETA: 37s - loss: 0.0181 - acc: 0.9969 31/62 [==============>...............] - ETA: 36s - loss: 0.0176 - acc: 0.9970 32/62 [==============>...............] - ETA: 34s - loss: 0.0170 - acc: 0.9971 33/62 [==============>...............] - ETA: 33s - loss: 0.0165 - acc: 0.9972 34/62 [===============>..............] - ETA: 32s - loss: 0.0160 - acc: 0.9972 35/62 [===============>..............] - ETA: 31s - loss: 0.0156 - acc: 0.9973 36/62 [================>.............] - ETA: 30s - loss: 0.0151 - acc: 0.9974 37/62 [================>.............] - ETA: 29s - loss: 0.0147 - acc: 0.9975 38/62 [=================>............] - ETA: 28s - loss: 0.0146 - acc: 0.9975 39/62 [=================>............] - ETA: 27s - loss: 0.0142 - acc: 0.9976 40/62 [==================>...........] - ETA: 26s - loss: 0.0139 - acc: 0.9977 41/62 [==================>...........] - ETA: 24s - loss: 0.0135 - acc: 0.9977 42/62 [===================>..........] - ETA: 23s - loss: 0.0132 - acc: 0.9978 43/62 [===================>..........] - ETA: 22s - loss: 0.0129 - acc: 0.9978 44/62 [====================>.........] - ETA: 21s - loss: 0.0126 - acc: 0.9979 45/62 [====================>.........] - ETA: 20s - loss: 0.0123 - acc: 0.9979 46/62 [=====================>........] - ETA: 19s - loss: 0.0135 - acc: 0.9973 47/62 [=====================>........] - ETA: 17s - loss: 0.0153 - acc: 0.9967 48/62 [======================>.......] - ETA: 16s - loss: 0.0254 - acc: 0.9961 49/62 [======================>.......] - ETA: 15s - loss: 0.0249 - acc: 0.9962 50/62 [=======================>......] - ETA: 14s - loss: 0.0244 - acc: 0.9962 51/62 [=======================>......] - ETA: 13s - loss: 0.0338 - acc: 0.9957 52/62 [========================>.....] - ETA: 11s - loss: 0.0332 - acc: 0.9958 53/62 [========================>.....] - ETA: 10s - loss: 0.0329 - acc: 0.9959 54/62 [=========================>....] - ETA: 9s - loss: 0.0323 - acc: 0.9959 55/62 [=========================>....] - ETA: 8s - loss: 0.0317 - acc: 0.9960 56/62 [==========================>...] - ETA: 7s - loss: 0.0393 - acc: 0.9950 57/62 [==========================>...] - ETA: 5s - loss: 0.0511 - acc: 0.9940 58/62 [===========================>..] - ETA: 4s - loss: 0.0502 - acc: 0.9941 59/62 [===========================>..] - ETA: 3s - loss: 0.0494 - acc: 0.9942 60/62 [============================>.] - ETA: 2s - loss: 0.0518 - acc: 0.9938 61/62 [============================>.] - ETA: 1s - loss: 0.0535 - acc: 0.9933 62/62 [==============================] - 271s 4s/step - loss: 0.0607 - acc: 0.9929 - val_loss: 0.7166 - val_acc: 0.9300
源码如下:
# 载入与模型网络构建
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Activation, Dropout, Flatten, Dense
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
import os
def built_model():
# 载入与模型网络构建
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(150, 150, 3)))
# filter大小为3*3 数量为32个,原始图像大小3,150 150
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
# this converts ours 3D feature maps to 1D feature vector
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(5)) # 几个分类就几个dense
model.add(Activation('softmax')) # 多分类
# model.compile(loss='binary_corssentropy',
# optimizer='rmsprop',
# metrics=['accuracy'])
# 优化器rmsprop:除学习率可调整外,建议保持优化器的其他默认参数不变
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
model.summary()
return model
def generate_data():
'''
flow_from_directory是计算数据的一些属性值,之后再训练阶段直接丢进去这些生成器。
通过这个函数来准确数据,可以让我们的jpgs图片中直接产生数据和标签
:return:
'''
train_datagen = ImageDataGenerator(
rescale=1. / 255,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True
)
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
'data/mytrain',
target_size=(150, 150), # all images will be resized to 150*150
batch_size=32,
class_mode='categorical' # 多分类
)
validation_generator = test_datagen.flow_from_directory(
'data/mytest',
target_size=(150, 150),
batch_size=32,
class_mode='categorical' # 多分类
)
return train_generator, validation_generator
def train_model(model=None):
if model is None:
model = built_model()
model.fit_generator(
train_generator,
# sampels_per_epoch 相当于每个epoch数据量峰值,
# 每个epoch以经过模型的样本数达到samples_per_epoch时,记一个epoch结束
samples_per_epoch=2000,
nb_epoch=50,
validation_data=validation_generator,
nb_val_samples=800
)
model.save_weights('first_try_animal.h5')
if __name__ == '__main__':
train_generator, validation_generator = generate_data()
train_model()
# 当loss出现负数,肯定是之前多分类的标签哪些设置的不对,
注意上面的 steps_per_epoch和validation_steps的值(应该是这样计算出来的):
model=build_model(input_shape=(IMG_W,IMG_H,IMG_CH)) # 输入的图片维度
# 模型的训练
model.fit_generator(train_generator, # 数据流
steps_per_epoch=train_samples_num // batch_size,
epochs=epochs,
validation_data=val_generator,
validation_steps=val_samples_num // batch_size)
3.6 画图展示和使用模型预测
最后我们可以通过图直观的查看训练过程中的 loss 和 acc ,看看其变化趋势。下面是代码:
# 画图,将训练时的acc和loss都绘制到图上
import matplotlib.pyplot as plt
def plot_training(history):
plt.figure(12)
plt.subplot(121)
train_acc = history.history['acc']
val_acc = history.history['val_acc']
epochs = range(len(train_acc))
plt.plot(epochs, train_acc, 'b',label='train_acc')
plt.plot(epochs, val_acc, 'r',label='test_acc')
plt.title('Train and Test accuracy')
plt.legend()
plt.subplot(122)
train_loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(train_loss))
plt.plot(epochs, train_loss, 'b',label='train_loss')
plt.plot(epochs, val_loss, 'r',label='test_loss')
plt.title('Train and Test loss')
plt.legend()
plt.show()
我们也可以通过训练好的模型去预测新的样本。
单张样本的预测代码如下:
# 用训练好的模型来预测新样本
from PIL import Image
from keras.preprocessing import image
def predict(model, img_path, target_size):
img=Image.open(img_path) # 加载图片
if img.size != target_size:
img = img.resize(target_size)
x = image.img_to_array(img)
x *=1./255 # 相当于ImageDataGenerator(rescale=1. / 255)
x = np.expand_dims(x, axis=0) # 调整图片维度
preds = model.predict(x) # 预测
return preds[0]
批量预测(一个文件夹中的所有文件):
# 预测一个文件夹中的所有图片
new_sample_gen=ImageDataGenerator(rescale=1. / 255)
newsample_generator=new_sample_gen.flow_from_directory(
'E:\PyProjects\DataSet\FireAI\DeepLearning',
target_size=(IMG_W, IMG_H),
batch_size=16,
class_mode=None,
shuffle=False)
predicted=model.predict_generator(newsample_generator)
print(predicted)
注意我们上面保存模型是保存的权重,而不是模型,保存模型的代码如下:
# 模型的加载,预测
from keras.models import load_model
saved_model=load_model('animal.h5')
predicted=saved_model.predict_generator(newsample_generator)
print(predicted) # saved_model的结果和前面的model结果一致,表面模型正确保存和加载
如果保存的是权重,直接加载,会报错:

最后,我自己的预测代码:
# 用训练好的模型来预测新的样本
from keras.preprocessing import image
import cv2
import numpy as np
from keras.models import load_model
def predict(model, img_path, target_size):
img = cv2.imread(img_path)
if img.shape != target_size:
img = cv2.resize(img, target_size)
# print(img.shape)
x = image.img_to_array(img)
x *= 1. / 255 # 相当于ImageDataGenerator(rescale=1. / 255)
x = np.expand_dims(x, axis=0) # 调整图片维度
preds = model.predict(x)
return preds[0]
if __name__ == '__main__':
model_path = 'animal.h5'
model = load_model(model_path)
target_size = (150, 150)
img_path = 'data/test/300.jpg'
res = predict(model, img_path, target_size)
print(res)
参考文献:https://www.jianshu.com/p/09b5a5d82eec
https://blog.csdn.net/sinat_26917383/articlehttps://img.qb5200.com/download-x/details/72861152#commentBox
https://github.com/RayDean/DeepLearning/blob/master/FireAI_005_KerasBinaryClass.ipynb
还有Keras官网,我的目的只是复现,掌握Keras。
加载全部内容