volatile 手摸手带你解析
ytao丨杨滔 人气:2
前言
volatile 是 Java 里的一个重要的指令,它是由 Java 虚拟机里提供的一个轻量级的同步机制。一个共享变量声明为 volatile 后,特别是在多线程操作时,正确使用 volatile 变量,就要掌握好其原理。
特性
volatile 具有可见性和有序性的特性,同时,对 volatile 修饰的变量进行单个读写操作是具有原子性。
这几个特性到底是什么意思呢?
- 可见性: 当一个线程更新了 volatile 修饰的共享变量,那么任意其他线程都能知道这个变量最后修改的值。简单的说,就是多线程运行时,一个线程修改 volatile 共享变量后,其他线程获取值时,一定都是这个修改后的值。
- 有序性: 一个线程中的操作,相对于自身,都是有序的,Java 内存模型会限制编译器重排序和处理器重排序。意思就会说 volatile 内存语义单个线程中是串行的语义。
- 原子性: 多线程操作中,非复合操作单个 volatile 的读写是具有原子性的。
可见性
可见性是在多线程中保证共享变量的数据有效,接下来我们通过有 volatile 修饰的变量和无 volatile 修饰的变量代码的执行结果来做对比分析。
无 volatile 修饰变量
以下是没有 volatile 修饰变量代码,通过创建两个线程,来验证 flag 被其中一个线程修改后的执行情况。
/**
* Created by YANGTAO on 2020/3/15 0015.
*/
public class ValatileDemo {
static Boolean flag = true;
public static void main(String[] args) {
// A 线程,判断其他线程修改 flag 之后,数据是否对本线程有效
new Thread(() -> {
while (flag) {
}
System.out.printf("********** %s 线程执行结束! **********", Thread.currentThread().getName());
}, "A").start();
// B 线程,修改 flag 值
new Thread(() -> {
try {
// 避免 B 线程比 A 线程先运行修改 flag 值
TimeUnit.SECONDS.sleep(1);
flag = false;
// 如果 flag 值修改后,让 B 线程先打印信息
TimeUnit.SECONDS.sleep(2);
System.out.printf("********** %s 线程执行结束! **********", Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "B").start();
}
}上面代码中,当 flag 初始值 true,被 B 线程修改为 false。如果修改后的值对 A 线程有效,那么正常情况下 A 线程会先于 B 线程结束。执行结果如下:

执行结果是:当 B 线程执行结束后,flag = false并未对 A 线程生效,A 线程死循环。
volatile 修饰变量
在上述代码中,当我们把 flag 使用 volatile 修饰:
/**
* Created by YANGTAO on 2020/3/15 0015.
*/
public class ValatileDemo {
static volatile Boolean flag = true;
public static void main(String[] args) {
// A 线程,判断其他线程修改 flag 之后,数据是否对本线程有效
new Thread(() -> {
while (flag) {
}
System.out.printf("********** %s 线程执行结束! **********", Thread.currentThread().getName());
}, "A").start();
// B 线程,修改 flag 值
new Thread(() -> {
try {
// 避免 B 线程比 A 线程先运行修改 flag 值
TimeUnit.SECONDS.sleep(1);
flag = false;
// 如果 flag 值修改后,让 B 线程先打印信息
TimeUnit.SECONDS.sleep(2);
System.out.printf("********** %s 线程执行结束! **********", Thread.currentThread().getName());
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "B").start();
}
}执行结果:
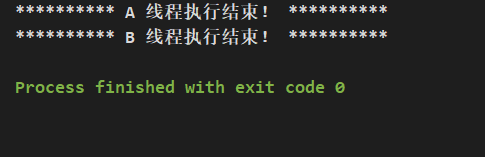
B 线程修改 flag 值后,对 A 线程数据有效,A 线程跳出循环,执行完成。所以 volatile 修饰的变量,有新值写入后,对其他线程来说,数据是有效的,能被其他线程读到。
主内存和工作内存
上面代码中的变量加了 volatile 修饰,为什么就能被其他线程读取到,这就涉及到 Java 内存模型规定的变量访问规则。
- 主内存:主内存是机器硬件的内存,主要对应Java 堆中的对象实例数据部分。
- 工作内存:每个线程都有自己的工作内存,对应虚拟机栈中的部分区域,线程对变量的读/写操作都必须在工作内存中进行,不能直接读写主内存的变量。
上面无 volatile 修饰变量部分的代码执行示意图如下:
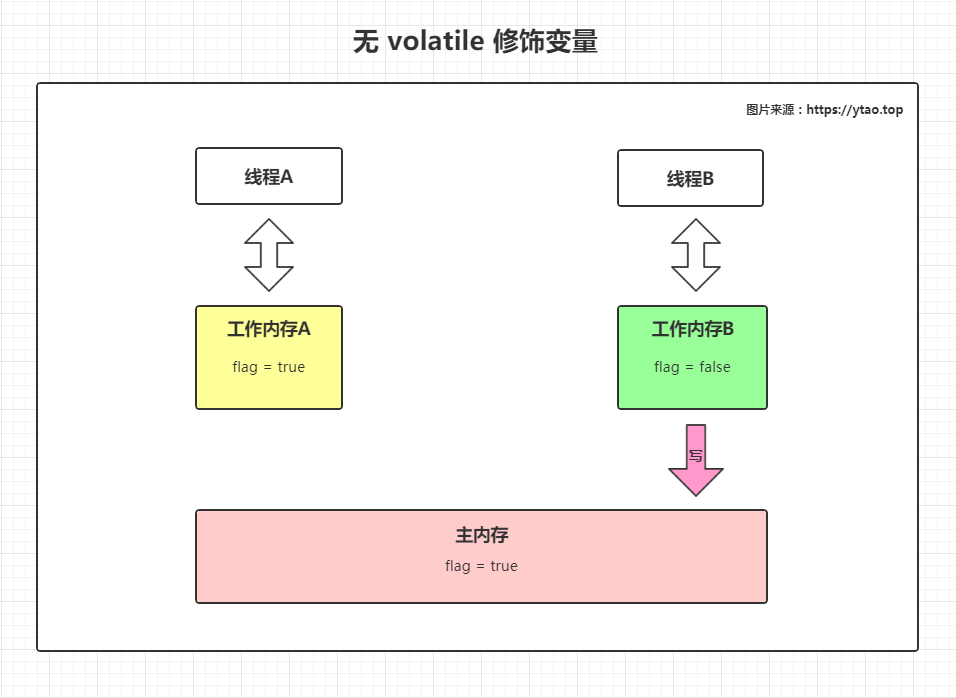
当 A 线程读取到 flag 的初始值为true,进行 while 循环操作,B 线程将工作内存 B 里的 flag 更新为false,然后将值发送到主内存进行更新。随后,由于此时的 A 线程不会主动刷新主内存中的值到工作内存 A 中,所以线程 A 所取得 flag 值一直都是true,A 线程也就为死循环不会停止下来。
上面volatile 修饰变量部分的代码执行示意图如下:

当 B 线程更新 volatile 修饰的变量时,会向 A 线程通过线程之间的通信发送通知(JDK5 或更高版本),并且将工作内存 B 中更新的值同步到主内存中。A 线程接收到通知后,不会再读取工作内存 A 中的值,会将主内存的变量通过主内存和工作内存之间的交互协议,拷贝到工作内存 A 中,这时读取的值就是线程 A 更新后的值flag = false。
整个变量值得传递过程中,线程之间不能直接访问自身以外的工作内存,必须通过主内存作为中转站传递变量值。在这传递过程中是存在拷贝操作的,但是对象的引用,虚拟机不会整个对象进行拷贝,会存在线程访问的字段拷贝。
有序性
volatile 包含禁止指令重排的语义,Java 内存模型会限制编译器重排序和处理器重排序,简而言之就是单个线程内表现为串行语义。
那什么是重排序?
重排序的目的是编译器和处理器为了优化程序性能而对指令序列进行重排序,但在单线程和单处理器中,重排序不会改变有数据依赖关系的两个操作顺序。
比如:
/**
* Created by YANGTAO on 2020/3/15 0015.
*/
public class ReorderDemo {
static int a = 0;
static int b = 0;
public static void main(String[] args) {
a = 2;
b = 3;
}
}
// 重排序后:
public class ReorderDemo {
static int a = 0;
static int b = 0;
public static void main(String[] args) {
b = 3; // a 和 b 重排序后,调换了位置
a = 2;
}
}但是如果在单核处理器和单线程中数据之间存在依赖关系则不会进行重排序,比如:
/**
* Created by YANGTAO on 2020/3/15 0015.
*/
public class ReorderDemo {
static int a = 0;
static int b = 0;
public static void main(String[] args) {
a = 2;
b = a;
}
}
// 由于 a 和 b 存在数据依赖关系,则不会进行重排序volatile 实现特有的内存语义,Java 内存模型定义以下规则(表格中的 No 代表不可以重排序):
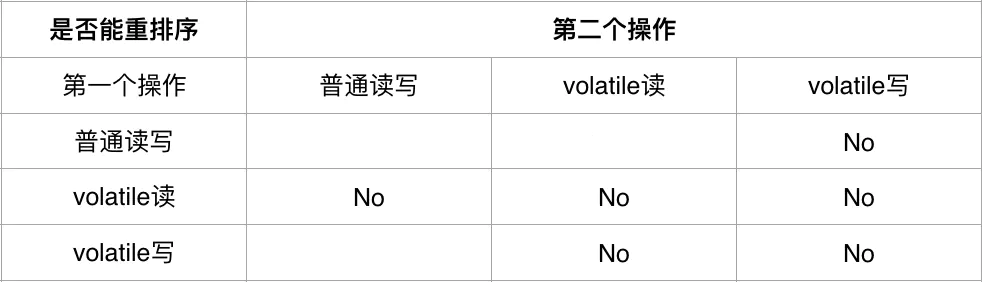
Java 内存模型在指令序列中插入内存屏障来处理 volatile 重排序规则,策略如下:
- volatile 写操作前插入一个 StoreStore 屏障
- volatile 写操作后插入一个 StoreLoad 屏障
- volatile 读操作后插入一个 LoadLoad 屏障
- volatile 读操作后插入一个 LoadStore 屏障
该四种屏障意义:
- StoreStore:在该屏障后的写操作执行之前,保证该屏障前的写操作已刷新到主内存。
- StoreLoad:在该屏障后的读取操作执行之前,保证该屏障前的写操作已刷新到主内存。
- LoadLoad:在该屏障后的读取操作执行之前,保证该屏障前的读操作已读取完毕。
- LoadStore:在该屏障后的写操作执行之前,保证该屏障前的读操作已读取完毕。
原子性
前面有提到 volatile 的原子性是相对于单个 volatile 变量的读/写具有,比如下面代码:
/**
* Created by YANGTAO on 2020/3/15 0015.
*/
public class AtomicDemo {
static volatile int num = 0;
public static void main(String[] args) throws InterruptedException {
final CountDownLatch latch = new CountDownLatch(10);
for (int i = 0; i < 10; i++) { // 创建 10 个线程
new Thread(() -> {
for (int j = 0; j < 1000; j++) { // 每个线程累加 1000
num ++;
}
latch.countDown();
}, String.valueOf(i+1)).start();
}
latch.await();
// 所有线程累加计算的数据
System.out.printf("num: %d", num);
}
}上面代码中,如果 volatile 修饰 num,在 num++ 运算中能持有原子性,那么根据以上数量的累加,最后应该是 num: 10000。
代码执行结果:
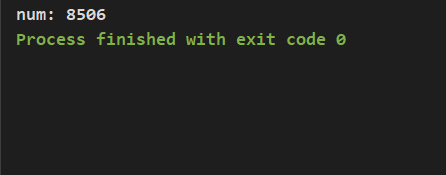
结果与我们预计数据的相差挺多,虽然 volatile 变量在更新值的时候回通知其他线程刷新主内存中最新数据,但这只能保证其基本类型变量读/写的原子操作(如:num = 2)。由于num++是属于一个非原子操作的复合操作,所以不能保证其原子性。
使用场景
- volatile 变量最后的运算结果不依赖变量的当前值,也就是前面提到的直接赋值变量的原子操作,比如:保存数据遍历的特定条件的一个值。
- 可以进行状态标记,比如:是否初始化,是否停止等等。
总结
volatile 是一个简单又轻量级的同步机制,但在使用过程中,局限性比较大,要想使用好它,必须了解其原理及本质,所以在使用过程中遇到的问题,相比于其他同步机制来说,更容易出现问题。但使用好 volatile,在某些解决问题上能获取更佳的性能。
个人博客: https://ytao.top
关注公众号 【ytao】,更多原创好文

加载全部内容