强化学习
叮叮当当sunny 人气:11. 定义
机器学习算法可以分为3种:有监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)和强化学习(Reinforcement Learning)。
强化学习(Reinforcement Learning, RL),又称再励学习、评价学习或增强学习,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
强化学习的常见模型是标准的马尔可夫决策过程(Markov Decision Process, MDP)。按给定条件,强化学习可分为基于模式的强化学习(model-based RL)和无模式强化学习(model-free RL),以及主动强化学习(active RL)和被动强化学习(passive RL)。强化学习的变体包括逆向强化学习、阶层强化学习和部分可观测系统的强化学习等。求解强化学习问题所使用的算法可分为策略搜索算法和值函数(value function)算法两类。深度学习模型可以在强化学习中得到使用,形成深度强化学习。
强化学习强调如何基于环境而行动,以取得最大化的预期利益。这一灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为。
强化学习最重要的3个特点是:
- 基本是以一种闭环的形式;
- 不会直接指示选择哪种行动(actions);
- 一系列的行动(actions)和奖励信号(reward signals)都会影响之后较长时间的决策。
在强化学习中,有四个非常重要的概念:
- 规则(policy)
Policy定义了agents在特定的时间特定的环境下的行为方式,可以视为是从环境状态到行为的映射。
- 奖励信号(a reward signal)
Reward就是一个标量值,是环境根据agent的行为返回给agent的信号,reward定义了在该情景下执行该行为的好坏,agent可以根据reward来调整自己的policy。常用R来表示。
- 值函数(value function)
Reward定义的是立即的收益,而value function定义的是长期的收益,它可以看作是累计的reward,常用v来表示。
- 环境模型(a model of the environment)
预测environment下一步会做出什么样的改变,从而预测agent接收到的状态或者reward是什么。
总之,强化学习作为一个序列决策(Sequential Decision Making)问题,它需要连续选择一些行为,从这些行为完成后得到最大的收益作为最好的结果。它在没有任何label告诉算法应该怎么做的情况下,通过先尝试做出一些行为——然后得到一个结果,通过判断这个结果是对还是错来进行反馈。
下面是一个形象化的描述:
强化学习能够让机器学着如何在环境中拿到高分,表现出优秀的成绩。而这些成绩背后是不断的试错,不断地尝试,并且累积经验,计算机拥有一位虚拟的老师,这个老师比较吝啬,他不会告诉你如何移动,如何做决定,只是给你的行为打分,这时,机器只需要记住那些高分,低分对应的行为,就可以在下次用同样的行为拿高分,并避免低分的行为。
参考:
百度百科:强化学习(学习方法) 词条
Mathworks:电子书
莫烦PYTHON:https://morvanzhou.github.io/tutorials/machine-learning/reinforcement-learning/1-1-A-RL/
OSCHINA:https://my.oschina.net/u/876354/blog/1614879
CSDN:https://blog.csdn.net/qq_39521554/articlehttps://img.qb5200.com/download-x/details/80715615
【机器学习】周志华 著 清华大学出版社 2016年1月第1版
Scientific Research:https://www.scirp.org/journal/paperinformation.aspx?paperid=90153
2. K摇臂赌博机
这是一种比较简单的情形:最大化单步奖赏,即仅考虑一步操作。
该部分例子在周志华的机器学习中有讲到,现利用Matlab对仅探索、 贪心法和Softmax算法进行实现,比较分析。

以5个摇臂为例,1~5号摇臂分别以0、0.2、0.4、0.6、0.8的概率返回奖赏1,以1、0.8、0.6、0.4、0.2的概率返回奖赏0。
function v=R(n,i)
%计算奖赏
%n:摇臂个数
%i:所选摇臂
%v:奖赏
if rand()<(i-1)/n
v=1;
else
v=0;
end
end
2.1 仅探索
function av=explore(n,k)
%仅探索
%n:摇臂个数
%k:试验次数
%av:平均累积奖赏序列
V=0;av=[];
for e=1:k
i=unidrnd(n);
V=V+R(n,i);
av=[av,V/e];
end
end
2.2 $\epsilon$贪心法
$\epsilon $贪心法基于一个概率来对探索和利用进行折中:每次尝试时以$\epsilon $的概率进行探索,即以均匀概率随机选取一个摇臂;以1-$\epsilon $的概率进行利用,即选择当前平均奖赏最高的摇臂(若有多个,则随机选取一个)。
function av=greed(n,k,ep)
%贪心法
%n:摇臂个数
%k:试验次数
%ep:探索概率
%av:平均累积奖赏序列
V=0;av=[];
for e=1:k
if e==1||rand()<ep
i=unidrnd(n);
else
for j=1:n
a(j)=mean(v(ii==j));
end
a(isnan(a))=0;
[~,i]=max(a);
end
ii(e)=i;
v(e)=R(n,i);
V=V+v(e);
av=[av,V/e];
end
end
2.3 Softmax算法
Softmax算法基于当前已知的摇臂平均奖赏来对探索和利用进行折中:若各摇臂的平均奖赏相当,则选取各摇臂的概率也相当;若某些摇臂的平均奖赏明显高于其他摇臂,则它们被选取的概率也明显更高。
Softmax算法中摇臂概率的分配是基于Boltzmann分布:
\[P(k)=\frac{{{e}^{\frac{Q(k)}{\tau }}}}{\sum\limits_{i=1}^{K}{{{e}^{\frac{Q(i)}{\tau }}}}}\]
function av=softmax(n,k,ta)
%Softmax方法
%n:摇臂个数
%k:试验次数
%ta:温度参数
%av:平均累积奖赏序列
V=0;av=[];
for e=1:k
if e==1
i=unidrnd(n);
else
for j=1:n
a(j)=mean(v(ii==j));
end
a(isnan(a))=0;
P(j)=exp(a(j)/ta)/sum(exp(a(j)/ta));
for j=1:n
if(sum(P(1:j))>rand())
i=j;
break;
end
end
end
ii(e)=i;
v(e)=R(n,i);
V=V+v(e);
av=[av,V/e];
end
end
2.4 比较分析
试验500次,比较几种方法的平均累积奖赏变化,绘出图像。
%摇臂个数
n=5;
%试验次数
len=500;
av_e=explore(n,len);
av_g=greed(n,len,0.1);
av_s=softmax(n,len,0.1);
plot(1:len,av_e,1:len,av_g,1:len,av_s);
xlabel("试验次数");ylabel("平均累积奖赏");
legend("仅探索","\epsilon贪心法","softmax算法");
如下图所示,仅探索在试验较多次数后稳定在0.4左右(0、0.2、0.4、0.6、0.8的均值),Softmax算法稳定在0.8左右,已经充分学习到了该环境, 贪心法则由于一定的随机探索概率而稍低。

2. Q-learning算法实现
2.1 场景引入
下面利用Q-learning实现二维网格的强化学习,并使用Matlab的强化学习工具箱(Reinforcement Learning Toolbox)进行验证。
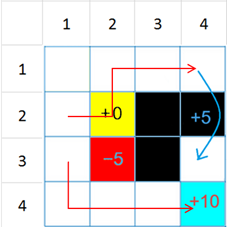
假设有如下场景:下面是一幅4×4的地图,最左上角的格子记为1号,下面的为2号,以此类推,第二列则为5~8号……
- 一位王子需要从下面地图中的某个方格出发,前往城堡寻找公主,他可以有上下左右4种移动方式;
- 公主在16号格子的位置(蓝色),如果找到公主,则可以得到10分的奖赏;
- 由于路途艰辛,王子每走一格就会损失1损失点体力(得到-1分的奖赏);
- 黑色区域存在障碍物,不可到达;
- 红色区域存在怪兽,到达时损失5点体力(得到-5分的奖赏);
- 黄色区域存在补给,到达时不需损失体力(得到0分的奖赏);
- 王子可以从13号格跳跃到15号格,并得到5分奖赏。

原理在这篇文章中,示例为5个房间的路线寻找,网上也有许多翻译版本,不再赘述。
核心原理为贝尔曼方程:
\[Q(x,x')=(1-\alpha )Q(x,x')+\alpha [R(x,x')+\gamma {{\max }_{a}}Q(x',a)]\]
$\alpha $为学习率,$\gamma $为折扣因子。
下面的实现过程有以下改动:
- 将5个房间拓展为16个二维网格;
- 加入障碍、跳跃等元素;
- 仿照Matlab工具箱,将奖赏矩阵R和可移动矩阵T分开定义,方便观察;
- 将一般的移动奖赏由0改为-1,促使其少走弯路;
- 按照$\epsilon $贪心法的思路,定义策略选择概率,在学习过程中实践,加快收敛速度。
2.2 编程实现
定义部分:
clear
%定义可移动矩阵T
T=zeros(16);
%T(i,j)=0表示不可从i位置移动至j位置,1则为可移动。
for i=1:16
%定义上行动作N
if(not(ismember(i,[1,5,9,13])))
T(i,i-1)=1;
end
%定义下行动作S
if(not(ismember(i,[4,8,12,16])))
T(i,i+1)=1;
end
%定义左行动作W
if(i>4)
T(i,i-4)=1;
end
%定义右行动作E
if(i<13)
T(i,i+4)=1;
end
end
%定义不可达到区域(障碍物)
T(:,[10,11,14])=0;
%定义跳跃
T(13,:)=0;
T(13,15)=1;
%定义奖赏矩阵
R=-1*ones(16);
R(:,6)=0;
R(:,7)=-5;
R(:,16)=10;
R(13,15)=5;
%将Q矩阵初始化为0
Q=zeros(16);
%折扣因子(γ)
gamma=0.8;
%策略选择概率概率
epsilon=0.3;
训练过程:
%训练循环
for episode=1:500
%随机化初始状态
state=unidrnd(16);
while ismember(state,[10,11,14])
state=unidrnd(16);
end
%如果不是最终转态
while state~=16
%选择可能的动作
possible_actions=find(T(state,:)==1);
possible_Q=Q(state,possible_actions);
if rand()<epsilon
%随意探索
choose=unidrnd(length(possible_actions));
action=possible_actions(choose);
else
[~,index]=max(possible_Q);
action=possible_actions(index);
end
%更新
Q(state,action)=R(state,action)+gamma*max(Q(action,:));
%下一步
state=action;
end
%输出训练过程
if mod(episode,100)==0
disp("-------------------")
fprintf("训练的次数为:%d\n",episode)
end
end
disp("训练结束")
寻找路径:
function path=findpath(start,Q)
%寻找路径
%start:开始位置
%Q:matrix Q
%path:路径向量
path=start;
while path(end)~=16
[~,next]=max(Q(start,:));
path=[path,next];
start=next;
end
end
测试:

由输出路径编号可知,程序为我们找到以下路线:
2.3 Reinforcement Learning Toolbox
注:以下程序是在Matlab2020a中运行的,在2018b及之前版本中运行可能存在问题,如果没有下载最新版建议可以使用在线版(https://matlab.mathworks.com/)进行测试。
注:在Matlab命令窗口中执行以下命令可以打开相关示例。
openExample('rl/BasicGridWorldExample')
创建环境:
clear %创建一个GridWorld对象 GW = createGridWorld(4,4); %设置终点和障碍 GW.TerminalStates = '[4,4]'; GW.ObstacleStates = ["[2,3]";"[2,4]";"[3,3]"]; %更新障碍状态的状态转换矩阵 updateStateTranstionForObstacles(GW); %设置障碍状态上的跳转规则 GW.T(state2idx(GW,"[1,4]"),:,:) = 0; GW.T(state2idx(GW,"[1,4]"),state2idx(GW,"[3,4]"),:) = 1; %在奖赏转换矩阵中定义奖赏 nS = numel(GW.States); nA = numel(GW.Actions); GW.R = -1*ones(nS,nS,nA); GW.R(state2idx(GW,"[1,4]"),state2idx(GW,"[3,4]"),:) = 5; GW.R(:,state2idx(GW,"[2,2]"),:) = 0; GW.R(:,state2idx(GW,"[3,2]"),:) = -5; GW.R(:,state2idx(GW,GW.TerminalStates),:) = 10; %创建环境 env = rlMDPEnv(GW);
模型设置和训练:
%要创建Q-learning代理,首先使用网格世界环境中的观察和操作规范创建Q矩阵
qTable = rlTable(getObservationInfo(env),getActionInfo(env));
qRepresentation = rlQValueRepresentation(qTable,getObservationInfo(env),getActionInfo(env));
%设置学习率
qRepresentation.Options.LearnRate = 1;
agentOpts = rlQAgentOptions;
%设置折扣因子
agentOpts.DiscountFactor = 0.8;
%配置epsilon-贪心概率
agentOpts.EpsilonGreedyExploration.Epsilon = 0.3;
qAgent = rlQAgent(qRepresentation,agentOpts);
%指定培训选项
trainOpts = rlTrainingOptions;
%最多训练100次,每次最多持续30个步长
trainOpts.MaxStepsPerEpisode = 30;
trainOpts.MaxEpisodes= 100;
%当连续30次获得超过100的平均累积奖赏时,停止训练(事实上不可能达到)
trainOpts.StopTrainingCriteria = "AverageReward";
%如果有必要,可以设置平均累积奖赏终止条件
%trainOpts.StopTrainingValue = 10;
%trainOpts.ScoreAveragingWindowLength = 20;
%训练可能需要几分钟才能完成。
%为了节省时间,可以通过将doTraining设置为false来加载经过预处理数据
%要实际完成训练,就要把doTraining设为true
doTraining = false;
if doTraining
trainingStats = train(qAgent,env,trainOpts);
else
load('BasicGridWorldqAgent.mat')
end
训练过程中,Matlab会弹出强化学习管理器,显示目前的训练信息,如下图所示:
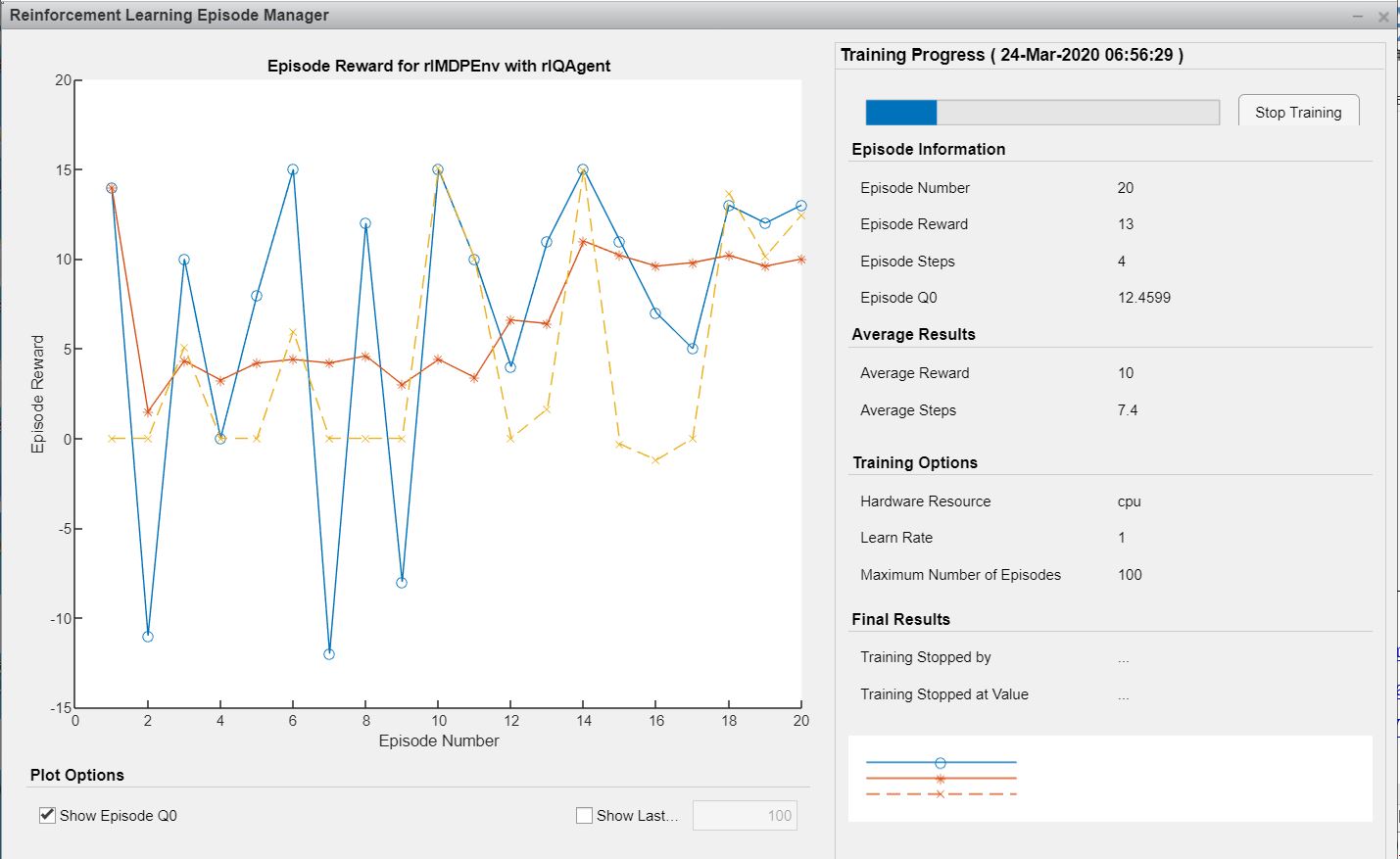
此处设置100次训练,训练完成后显示:

也可以提前点击Stop Training按钮进行终止,此时显示:

测试仿真:
%设置起始位置
env.ResetFcn = @() state2idx(GW,"[2,1]");
plot(env)
env.Model.Viewer.ShowTrace = true;
env.Model.Viewer.clearTrace;
simOpts = rlSimulationOptions(...
'MaxSteps',10,...
'NumSimulations',1);
%开始模拟仿真
sim(qAgent,env,simOpts)
以从2号格开始为例,Matlab训练结果可以通过图形展示出来:

2.4 对比
- 自己编程的方式内部结构清晰可见,容易理解,便于修改,且执行速度较快;
- Matlab工具箱输入形式简单,训练过程和结果的可视化较好,且内部算法可能更加智能。
参考:
Mnemstudio:http://mnemstudio.org/path-finding-q-learning-tutorial.htm
freeCodeCamp:Diving deeper into Reinforcement Learning with Q-Learning
MATLAB Help:Train Reinforcement Learning Agent in Basic Grid World
createGridWorld
代码包:
链接:http://pan.baidu.com/s/1WpgIVEQyCuuDh4iQK06fYQ
提取码:ju30
加载全部内容