正则表达式断言 正则表达式断言、巡视(Assertions)、正向断言、反向断言介绍
程默 人气:0断言(Assertions)在正则表达式概念里面难理解,它通常指的是在目标字符串的当前匹配位置进行的一种测试但这种测试并不占用目标字符串,也即不会移动模式在目标字符串中的当前匹配位置。详细可以看看,正则表达式匹配解析过程探讨分析(正则表达式匹配原理),里面提到“零宽度“很多元字符,只是对特殊位置进行匹配,它们可以理解为断言。
断言元字符
常见断言元字符有: \b, \B, \A, \Z, \z, ^ ,$ 它们只是表示特殊位置,各自作用如有字符串AB,带位置表示为:0A1B2
| 元字符 | 意义(以上面带位置字符串说明) |
|---|---|
| ^ | 行首,字符串首 表示位置0 |
| $ | 行尾,字符串尾部,表示位置2 |
| \b | 字分界线,可以表示:0,2位置 |
| \B | 非字分界线,可以表示1位置 |
| \A | 目标的开头(独立于多行模式) 表示位置0 |
| \Z | 目标的结尾或位于结尾的换行符前(独立于多行模式) 表示位置2 |
| \z | 目标的结尾(独立于多行模式)表示位置2 |
| \G | 目标中的第一个匹配位置 |
| A,Z,z,G很少使用 | |
这些断言的测试都是一些基于当前位置的测试,断言还支持更多复杂的测试条件。更复杂的断言以子模式方式来表示,它包括先行(前向)断言(Lookahead assertions)和后行(后向)断言(Lookbehind assertions),这些断言判断只做匹配判断条件,不会记录在匹配结果中,不会匹配字符。
先行断言、正向断言、正向巡视(Lookahead assertions)
先行断言,常有表示(?=pattern),从当前匹配位置开始测试后面匹配字符串是否成立,还有(?!pattern)这样两种格式,我们来看看一个例子。源字符串:“abc100”,正则表达式是:
/[a-z]+(?=\d+)/ ,我们分析下过程如下图:
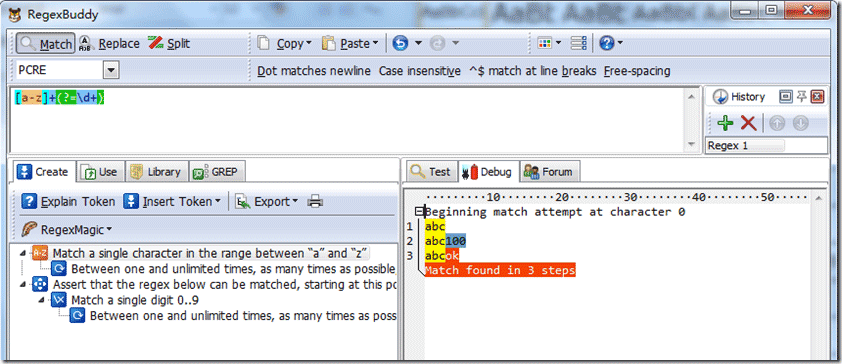
首先由正则表达式字符 [a-z]+ 取得控制权,匹配字符:”abc”,位置从”0”开始匹配,变成3。从该位置测试/d+是否成立。匹配到字符100,返回成立。因此正则表达式正向断言成功。返回匹配字符串”abc”
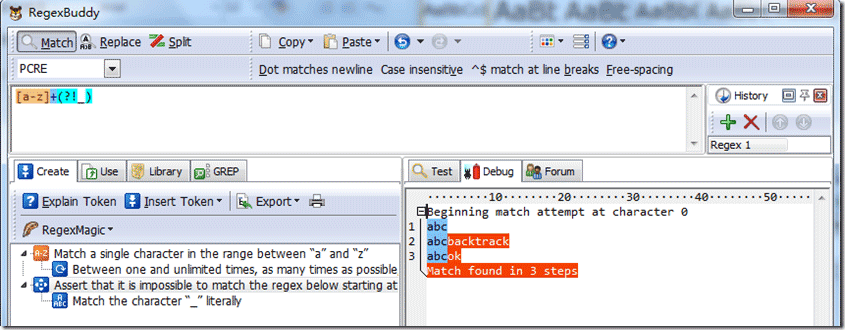
(?!pattern) 只是,正向匹配,当后面没有匹配成功,将返回真。以下是系统源字符串:abc100,测试结果如下:
后行断言、反向断言、反向巡视(Lookbehind assertions)
后行断言,常见表达式是:(?<=pattern)或者(?<!pattern)格式。正则表达式里面,不要出现不固定长度量词,可能会出现死循环。匹配出错。表示当前位置左边将出现匹配字符,则返回真,后面匹配正常。因为如果它出现在最左边,默认位置从0开始,匹配都是失败的。一般都从后面正则表达式开始匹配,再回溯,直到匹配到为止。我们看看下面例子:源字符串:“abc100+=“,正则表达式是:”(?<=\w)\w+”,匹配过程如下图:

首先由正则表达式字符 /\w+/取得控制权,匹配字符:”abc100”,位置从”0”开始匹配,匹配到6个字符。从该位置0检测左变\w匹配失败。因此/\w+/从字符b开始匹配到”bc100”,测试它左侧有字符”a”,反向断言正确。因此匹配到字符串“bc100”,(?<!pattern),只是没有匹配成功返回真,其它都一样!
后记:从这篇文章,我们发现搜索特点都是从左到有,一般正向断言放到,正则表达式后,反向断言放到匹配正则表达式前。但是,这里也可以放到前或后。这里就不再举例。欢迎交流讨论!
加载全部内容