算法与数据结构(3):基本数据结构——链表,栈,队列,有根树
Albert_Shen 人气:1原本今天是想要介绍堆排序的。虽然堆排序需要用到树,但基本上也就只需要用一用树的概念,而且还只需要完全二叉树,实际的实现也是用数组的,所以原本想先把主要的排序算法讲完,只简单的说一下树的概念。但在写的过程中才发现,虽然是只用了一下树的概念,但要是树的概念没讲明白的话,其实不太好理解。所以决定先介绍一下基本的数据结构,然后下一篇文章再介绍堆排序。读书人的事,怎么能叫鸽呢?这是战略调整,战略调整懂不懂?我给你说,上古大儒图灵说过asdfghjkl!/.,;''
不鸽了不鸽了,下次一定。
链表
链表是一种非常非常非常重要的数据结构,与数组有很多相似性,例如其中的各对象均按线性顺序排列。他们最重要的区别在于,数组是一种静态的集合,链表则是一个动态的集合。我们用下图来形象地说明两者的区别:
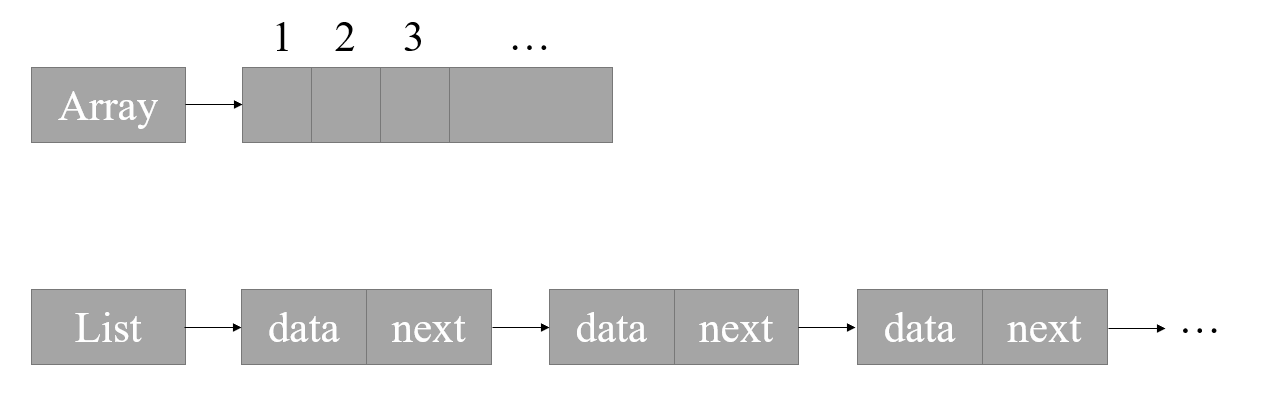
上图分别是数组与单向链表的示意图。数组在使用前需要声明好需要使用的空间大小,声明后空间大小无法变化,数据存储是连续的,插入删除需要移动后面所有元素,但可以使用下标寻址;链表则正好与之相反,使用前无需声明需要使用的空间,使用时可根据实际情况增删数据个数(使用空间也随之变化),数据存储不连续,插入删除效率极高,但不可用下标寻址。
细心的同学可能发现,为什么上图中 Array 和 List 都有箭头指着后面的空间呢?是的,无论是数组还是链表,他们本质上都是指针,上图中所有箭头都是指针的意思。例如当你使用 int array[20] 声明了一个数组时,后面所使用的 array 本质上都是一个指针,你既可以使用 array[1] 来获取第二个数据,也可以使用 *(array + 1) 来达到同样的效果。
那么链表的结构是什么样的呢?

如上图所示,一个链表一般分为两个部分,一是指向列表第一个节点的 List ,一般用于指代列表,类似于数组中数组名的作用;另一个是列表内部真正储存数据的节点 Node。
为什么需要分为两个部分?请读者们回顾一下我们上文所说,这种设计本质上是在模仿数组的设计。比如说我现在告诉小明我定义了两个数组,分别叫做 array1 和 array2 ,如果他需要使用数组1的第3个元素,那么只需要使用 array1[2] 即可,如果没有这样一个标志符,难道我们用 [2] 来选取这个元素吗?那如果我要使用数组2的第3个元素又该怎么办呢?当然这其实只是一个小问题,理论上来说我们也可以用其他手段来解决他,但单独定义一个头部有另外一个更为重要的原因,我们可以在头部 List 储存整个列表的属性,例如列表元素个数,是否有序等等。当我们想要知道一个列表的元素个数时,只需要从头部直接获取相应的信息即可,而不用每次都扫描一遍整个列表再返回结果。当然你说我可以把这个信息写在 Node 里呀?我现在只需要添加一个节点,就可以储存整个列表的主要信息,你却要把他复制到每一个 Node 里去?你以为你是区块链啊?还要分布式存储?难道你还怕我 List 节点会骗你不成?要不少于51%的节点都说我们长度为10你才相信我长度真为10?
上文我们提到的链表是最为常用的链表,称为双向链表,其实意思也很简单,链表的搜索方向有两个,既可以向前搜索(指向上一个节点的 prev 指针),也可以向后搜索(指向下一个节点的 next 指针),首节点因为前面没有其余节点,所以首节点的 prev 指针为 NULL,同理尾结点的 next 指针也为 NULL。与之相似的有单向链表:只有 next 或 prev 指针,只能沿着一个方向搜索。循环链表,首节点的 prev 指针指向尾结点,尾结点的 next 指针指向首节点(而不是像双向链表里为 NULL)。只要你愿意,你可以定义出各种奇奇怪怪的链表,理论上来说,后面我们讲到的其他数据结构其实都是一些被广泛使用的奇怪链表。
下文中链表的完整代码可以在我的github上找到。
链表的 Node 节点如下定义:
// 列表节点
typedef struct ListNode{
int data;
struct ListNode* prev;
struct ListNode* next;
}ListNode;链表的 List 如下定义:
// 列表
typedef struct List{
struct ListNode* head;
int length;
}List;初始化一个列表:
// 初始化一个列表,不包含任何数据
List* ListInit(){
List* list = (List*)malloc(sizeof(List));
list->head = NULL;
list->length = 0;
return list;
}从链表中搜索并返回指定节点:
// 在list列表中搜索data为number_to_search的第一个节点,并返回此节点
ListNode* ListSearch(List* list, int number_to_search){
ListNode* node = list->head;
while(node != NULL && node->data != number_to_search){
node = node->next;
}
return node;
}向链表插入新节点:
// 新建一个data为number_to_add的节点,并将其添加至list列表头部
int ListAdd(List* list, int number_to_add){
// 新建节点
ListNode* node_to_add = (ListNode*)malloc(sizeof(ListNode));
node_to_add->data = number_to_add;
node_to_add->next = list->head;
node_to_add->prev = NULL;
// 将新节点插入至列表头部
if(list->head != NULL){
list->head->prev = node_to_add;
}
list->head = node_to_add;
list->length ++;
return 0;
}删除链表中的指定节点:
// 从list列表中删除node节点,并free掉node节点
int ListDelete(List* list, ListNode* node){
if(node->prev == NULL){
list->head = node->next;
} else{
node->prev->next = node->next;
}
if(node->next != NULL){
node->next->prev = node->prev;
}
free(node);
list->length --;
return 0;
}大家可以看到在代码中,很多代码都是在判断边界条件,写着实在是不方便,那有没有什么办法不需要进行繁琐的边界判断呢?当然有,不知道同学们有没有回想起我们上文所说的循环链表?没错,我们将链表头部和尾部指向 NULL 的指针全部指向一个 Node 节点,我们不妨将其称为 Nil 节点,此节点与其他 Node 节点采用完全一样的结构,Nil 的 prev 指向尾结点,next 指向首节点,这样就无需判断边界条件了,这种方式的具体实现就留给各位读者了。
栈和队列
栈和队列是一种动态集合,虽然操作简单,但却十分有效。栈采用后进先出(last-in,,first-out,LIFO,这名字真的体现了一种淳朴感,哪像现在各种东西吹得天花乱坠)的策略,即字面意思,最后进入此集合的元素会被首先推出。例如我们平时使用的文本编辑器的撤销功能,第一个撤销的操作是你最后进行的那一个操作,这就是一个典型的栈的应用。队列正好与栈相反,采用先进先出(first-in,first-out,FIFO)带策略,最先进入队列的元素会被首先推出,例如平时生活中的排队,先开始排队的人先排到。
栈和队列的操作也非常类似,都包含插入(栈中称为 PUSH、入栈,队列中称为 ENQUEUE、入队),删除(栈中称为 POP、出栈,队列中称为 DEQUEUE,出队)。
栈
队栈和队列有了一个初步的认识后,我们来详细介绍一下栈。栈既可以用数组实现,也可以使用链表实现,为了讲解简单,我们就使用数组来实现(其实使用链表实现也是一样的道理,几乎没有任何区别)。
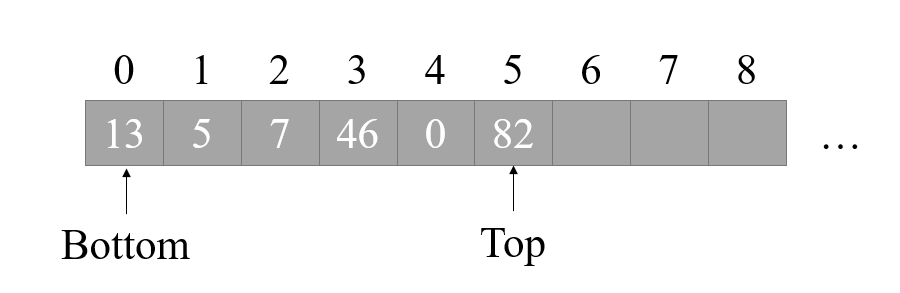
上图就是一个栈的示意图,一个栈包含两个指针,分别是栈底指针 Bottom,栈顶指针 Top,每次我们进行 PUSH操作时,将 Top 指针加1,然后将数据复制到现在 Top 指针所指位置,如下图所示:
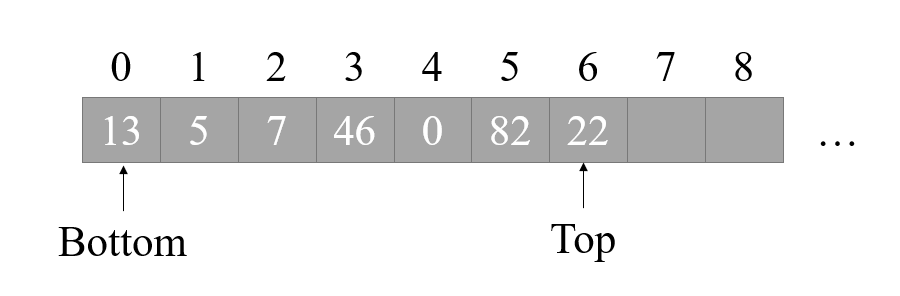
出栈则是此过程的逆过程,将 Top 指针减一,并返回数据即可。
栈最重要的就是 PUSH 和 POP 操作,那看起来没 Bottom 指针什么事呀?其实不然,Bottom 指针最重要的作用是标记这是栈开始的地方,同时也可以帮助我们判断栈是否为空,并防止出栈时越界等问题。
同时我们也注意到出栈时我们只讲 Top 指针减一了,可数据还在栈里面呀?其实无需担心,一段空间内是否有数据,不是看里面是否真的有数据,而是根据你的解释来判断。计算机的数据本质上都是 0-1 串,所以其实整个计算机从拼装好那一刻,他的空间就一直是“满”的——因为一个 bit 不是高电平就是低电平,也就意味着不是 1 就是 0。当你在计算机里删除文件时,是真的把一份文件的数据抹去了吗?不,只是操作系统在那做了一个标记,告诉其他程序:这些不是有用的数据,如果你们需要空间,可以直接使用这些地方。这正是误删文件后,进行数据恢复的原理——只要这段空间还没有被写入其他数据,那么我只需要再将其标记回来,告诉大家这个地方有一个文件,此时文件就成功恢复了(当然还伴随有一些其他的细节操作,比如修改文件索引等等)。所以同理,出栈时我们只需将 Top 指针减一即可,因为此时我们的解释为,下标大于 Top 指针的都不属于栈内的数据。再说了,你又有什么方法将这段数据抹去呢?难道将其赋值为 0 吗?如果我本身就出栈了一个 0 呢?
下文中栈的完整代码可以在我的github上找到。
栈的定义如下:
// 定义栈
typedef struct Stack{
int* array;
int top;
int length;
}Stack;栈的初始化:
// 初始化栈
Stack* StackInit(int stack_length){
Stack* stack = (Stack*)malloc(sizeof(Stack));
stack->array = (int*)malloc(sizeof(int) * stack_length);
stack->top = -1;
stack->length = stack_length;
return stack;
}常用的栈辅助函数:
// 判断栈是否已满
int StackIsFull(Stack* stack){
return (stack->top >= (stack->length - 1));
}
// 判断栈是否为空
int StackIsEmpty(Stack* stack){
return (stack->top < 0);
}压栈操作:
// 压栈
int StackPush(Stack* stack, int number_to_push){
if(StackIsFull(stack)){
return -1;
} else{
stack->top ++;
stack->array[stack->top] = number_to_push;
return 0;
}
}出栈操作:
// 出栈
int StackPop(Stack* stack){
stack->top --;
return stack->array[stack->top + 1];
}对于上述代码,我们需要注意,由于C语言本身的限制,所以在出栈以前需要使用者自行调用 StackIsEmpty() 函数,在保证栈不为空的情况下调用 StackPop() 出栈,否则会出现越界造成不可预测的错误。但如果使用一些有抛出异常功能的高级语言,如 Java,则可以在栈空但用户仍然进行 Pop 操作时抛出异常,以此强行避免不熟练的使用者的错误操作。
题外话:其实我上面的代码写的不是很符合C语言的规范,如果没有特殊情况,C语言函数的返回值都是用于判断函数执行效果的。例如 return 0 表示操作正常,return -1 表示溢出,return -2 表示空间不足申请失败等,数据的传递需要全部使用参数实现(例如传入的数据使用普通变量,计算完成返回的数据使用指针等),例如C语言中最简单的输入输出函数 scanf() printf() 等。因为是示例代码,所以这些细节地方我没有太注意。
队列
同理,队列也既可以使用链表实现,也可以使用数组实现。我们也使用数组举例。队列与栈不同的是,队列插入数据时,插入至 tail 指针所指位置,然后将 tail 指针加一,推出数据时将 head 指针加一,然后返回原本 head 指针所指位置的数据。
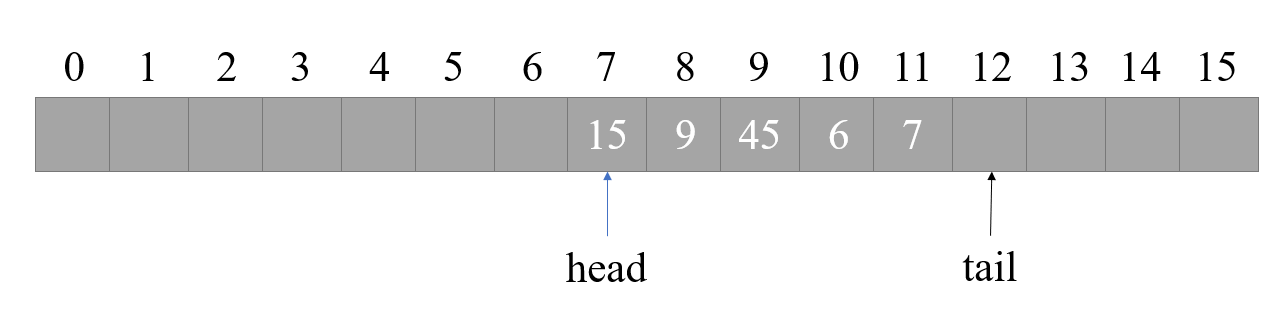
队列与链表不同,设计栈时,我们必定是从下标为0的位置开始使用,所以数组有多大空间,栈在任何时候都能使用这么大的空间。但队列由于是先进先出,如果进行了多次操作以后,例如原本定义的数组长度为10,我们进行了5次出队以后,head 指针讲指向下标为5的位置,难道前面的空间我们就不能再使用了吗?当然不是,此时我们可以采用一种被称为循环数组的设计:当超出了数组下标上限时,将从下标0重新开始增加。听着非常高大上的样子,其实实现起来非常简单:正常情况下,下标增加时只需简单的进行 + 操作,而在循环数组中,每次 + 操作以后再将新的值对数组长度取余,这样当下标超过数组长度时,将会因为被取余而等同于回到数组下标 0 处重新增加。如果没有理解这一段话,大家可以阅读下文入队函数中的操作。
队列的完整代码在我的github上可以看到。
队列定义:
// 队列定义
typedef struct Queue{
int* array;
int length;
int head;
int tail;
}Queue;队列初始化:
// 初始化
Queue* QueueInit(int queue_length){
Queue* queue = (Queue*)malloc(sizeof(Queue));
queue->array = (int*)malloc(sizeof(int) * (queue_length + 1));
queue->head = 0;
queue->tail = 0;
queue->length = queue_length + 1;
return queue;
}请注意,在代码实现中,我们申请的数组长度比队列长度大 1,请读者们回顾我们上文中队列实现的示意图,队列 head 指针所指位置是队首元素,队列 tail 指针所指位置是队尾元素下标 + 1。如果我们申请的数组长度与队列长度相同,请读者们设想一下,队列为空和队列满时,head 指针和 tail 指针指向的下标是否都是相同的?这样一来我们是无法判断出 head == tail 时,究竟是队列为空,还是队列已满。当然我们也可以利用其它标记,来使得我们可以在不额外增加长度的情况下解决这个问题,但这样势必会使整个问题复杂化,判断流程过多,不仅容易出错,运行效率也降低了。
常用队列辅助函数:
// 判断队列是否已满
int QueueIsFull(Queue* queue){
return (((queue->tail + 1) % queue->length) == queue->head);
}
// 判断队列是否为空
int QueueIsEmpty(Queue* queue){
return (queue->head == queue->tail);
}入队:
// 入队
int QueueEnqueue(Queue* queue, int number_to_enqueue){
if(QueueIsFull(queue)){
return -1;
}
queue->array[queue->tail] = number_to_enqueue;
queue->tail = (queue->tail + 1) % queue->length;
return 0;
}出队:
// 出队
int QueueDequeue(Queue* queue){
int return_value = queue->array[queue->head];
queue->head = (queue->head + 1) % queue->length;
return return_value;
}有根树
我们上文介绍的链表几乎可以实现所有的数据结构,包括树。
由于树这个家族过于庞大,不可能在一篇文章中讲解完成,所以我们将仅仅简单地介绍一下树的概念,方便我们后续的学习,并不实际在代码层面实现。我们将在学习更加深入后,在合适的时间对树这个家族进行详细的介绍并在代码层面实现。
一个树节点通常包含三个部分,数据,父节点指针,子节点指针。我们首先以最简单的二叉树为例进行介绍。下文的介绍中,为了突出主要问题,所有的图示中都将省略树节点的数据部分。
二叉树
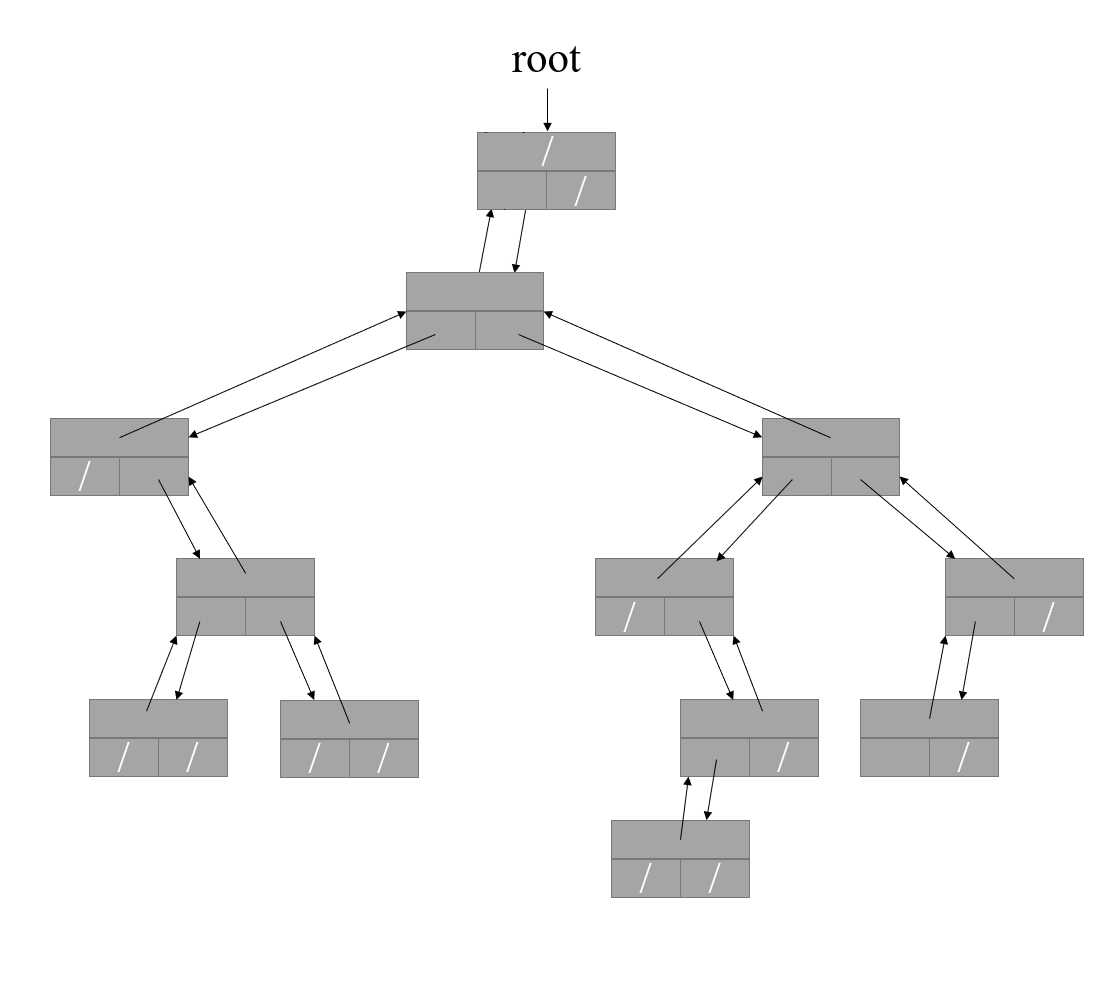
如上图,这是一个二叉树的示意图,最上面的那个节点称为树根,这也是我们为什么将其称为有根树。由于版面有限,我们在图中省略了每个节点的数据部分。一个二叉树的每个节点包含一个父节点指针和两个子节点指针(分别称为左孩子和右孩子),如果节点没有父节点(这种情况只会出现在树根节点),那么其父节点指针为 NULL,如果没有左孩子,则左孩子指针为 NULL,当没有右孩子时同理。这样的一种数据结构被我们形象地称为树。不过和自然界中的树不一样,我们的树一般而言是倒着的,最上面的是跟节点,最下面的是叶子节点。
分支无限制的有根树
二叉树是我们平时使用频率最高,也是最简单的树,那么相对应的就会有多叉树。那么我们应该如何表示多叉树呢?难道向二叉树一样,有几个孩子节点就有几个孩子指针?当然这也是一种实现方式,但不太合理——二叉树的使用频率非常高,为其单独设计一种结构很合理,但除了二叉树以外的其他树并没有什么是非常常用的,不同的程序之间的树结构几乎没有通用性,而且,如果我说我需要一个 100 万叉树,难道你需要在代码里把孩子节点的代码复制 100 万遍吗?
我们通常使用如下结构实现多叉树:
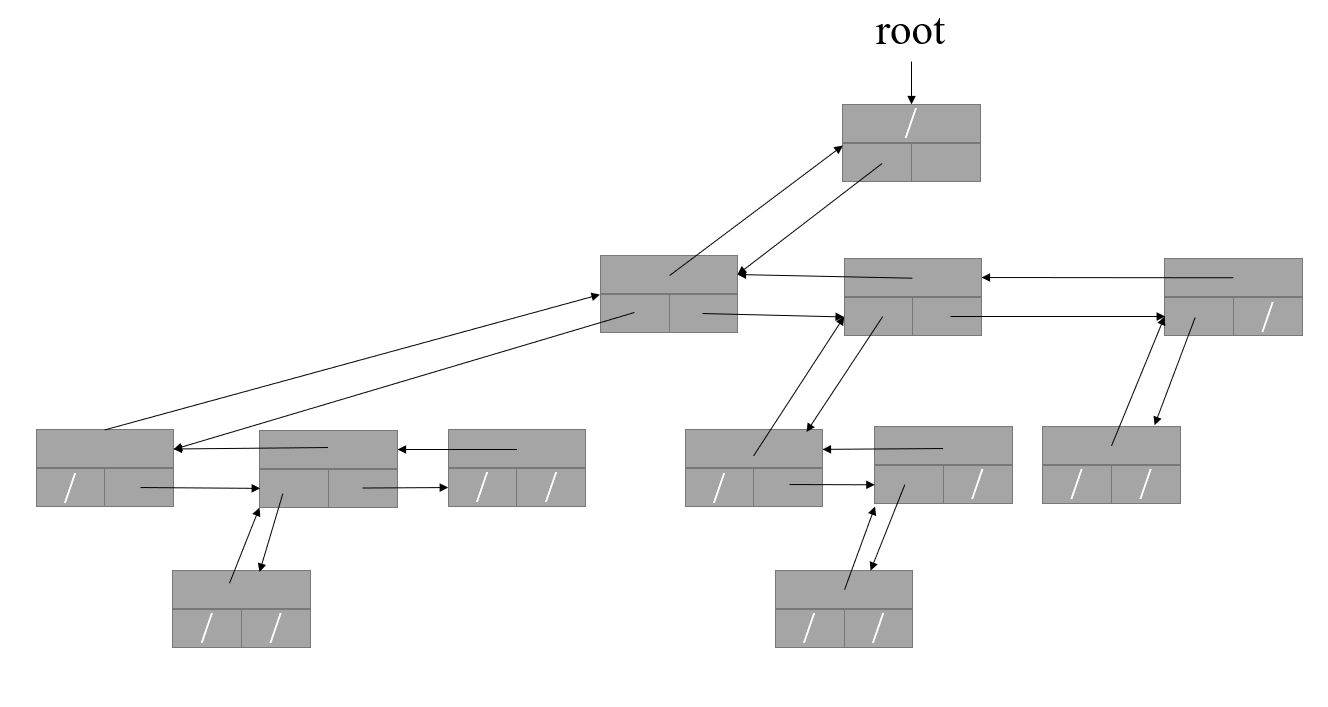
在数据结构上与二叉树完全一样,但在解释上则不同。位于同一排的节点互相称为兄弟节点,上方的是父节点,下方的是子节点。原先的左孩子变成了子节点里的“兄”,原先的右孩子变成与自己“同辈”的“弟”,“长兄”原先的父节点依然是父节点,但其他兄弟原先的父节点则变成了“兄”节点。仅仅通过不同的解释,在完全不改变数据结构的情况下,我们就实现多叉树,而且是任意子节点数量的多叉树。
请读者们仔细观察,我们上文中所举例的二叉树和多叉树实际上有没有什么区别呢?
结语
这一篇文章介绍了四种最基本的数据结构,请读者们一定要深入理解链表的概念,几乎所有的数据结构都可以从链表中找到影子。下一篇文章我们将会介绍堆排序(绝对不鸽!!!),堆排序将会使用树的概念实现,不过是一种特殊的树——完全二叉树。
原文链接:albertcode.info
个人博客:albertcode.info
微信公众号:AlbertCodeInfo
加载全部内容