Scikit-Learn 源码研读 (第二期)基类的实现细节
chandlertu 人气:2
[toc]
sklearn项目可以看成一棵大树,各种estimator是果实,而支撑这些估计器的主干,是为数不多的几个基类。常见的几个类有BaseEstimator、BaseSGD、ClassifierMixin、RegressorMixin,等等。
官方文档的API参考页面列出了主要的API接口,我们看下Base类

本期我们只研究BaseEstimator、ClassifierMixin、RegressorMixin、TransformerMixin。BaseSGD是一个比较大的话题,需要单独开一期来仔细研究。
## BaseEstimator
最底层的就是BaseEstimator类。主要暴露两个方法:`set_params`,`get_params`.
### `get_params`
这个方法旨在获取对象的参数,返回对象默认是{参数:参数值}的键值对。如果将`get_params`的参数`deep`设置为True,还会返回(如果有的话)子对象(它们是估计器)。下面我们来仔细看一下这个方法的实现细节:

为了节约篇幅,我会将不重要的注释略去,以后都是这样处理,不再赘述,除非特殊说明。
(1)
函数体中主要就是`getattr`方法,语法:getattr(对象,要检索的属性[,如果属性不存在则返回的值])。Line200~208的任务是判断self(一般就是估计器的实例)是否含有key这个参数,如果有就返回它的参数值,否则人为设置为None。
为什么要写这么复杂呢? 其实可以直接写作 `value = getattr(self, key, None)`,有点迷~
(2)
再来看Line209~212,如果用户设置了`deep=True`,并且value对象实现了`get_params`(说明value对象是一个子对象,即估计器,否则普通的参数是不会再次实现`get_params`方法的),则提取参数字典的键值对,并且写入字典。整个函数最后返回的也是字典。
(3)
我们先快速的看一下这个方法具体是怎么使用的,然后再继续追踪源码的实现。
```python
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(random_state=0)
X = [[ 1, 2, 3], # 2 samples, 3 features
[11, 12, 13]]
y = [0, 1] # classes of each sample
clf.fit(X, y)
```
简单的实例化一个随机森林分类器的对象,我们看下对它调用`get_params`会返回什么:
```python
clf.get_params()
{'bootstrap': True,
'class_weight': None,
'criterion': 'gini',
'max_depth': None,
'max_features': 'auto',
'max_leaf_nodes': None,
'min_impurity_decrease': 0.0,
'min_impurity_split': None,
'min_samples_leaf': 1,
'min_samples_split': 2,
'min_weight_fraction_leaf': 0.0,
'n_estimators': 10,
'n_jobs': None,
'oob_score': False,
'random_state': 0,
'verbose': 0,
'warm_start': False}
```
很明显,这就是这个随机森林分类器的默认参数方案。
(4)
我们注意到Line199这行,使用了另一个方法 `for key in self._get_param_names():`,现在研究该函数
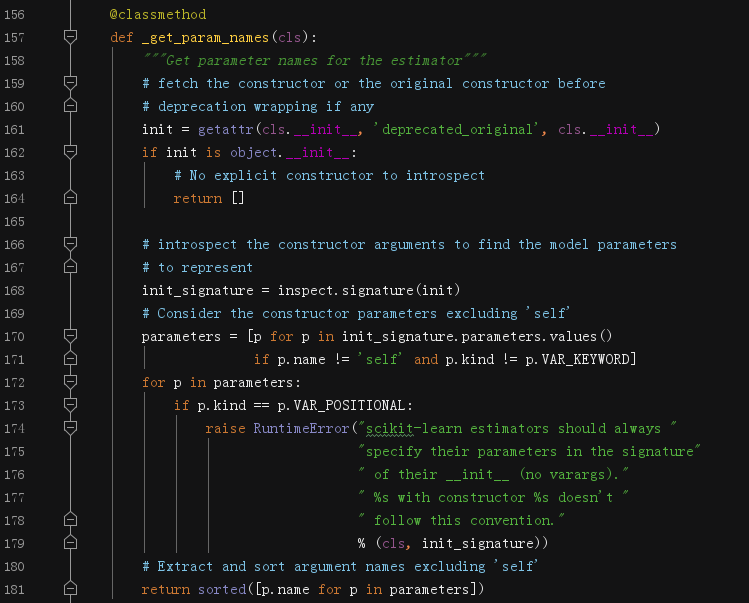
这里赘述一下,在sklearn这种大型的Python项目中,很多暴露出去的方法,其实质只是一个壳子,你可以理解为它是在搬运别人做的东西,只是美化包装一下交给调用者。例如`get_params`方法,它并没有真的获取到估计器实例的参数,因为`_get_param_names`在帮它干这个活儿。
`@classmethod`这个装饰器直接告诉我们,该方法的适用对象是类自身,而非实例对象。
这个函数有很多检查事项,真正获取参数的是 `inspect.signature(init).parameters.values()`,最后获取列表中每个对象的`name`属性。
### `set_params`
这个方法作用是设置参数。正常来说,我们在初始化估计器的时候定制化参数,但是也有临时修改参数的需求,这时可以手工调用`set_params`方法。但是更多的还是由继承BaseEstimator的类来调用这个方法。
具体地,我们看下实现细节:

这个方案支持处理嵌套字典,但是我们不去纠缠这么琐碎,直接看到L251,`setattr(self, key, value)`,对估计器的key属性设置一个新的值。
应用的实例:

## ClassifierMixin
Mixin表示混入类,可以简单地理解为给其他的类增加一些额外的方法。Sklearn的分类、回归混入类只实现了`score`方法,任何继承它们的类需要自己去实现`fit`、`predict`等其他方法。

关于混入类,简单的说就是一个父类,但是和普通的类有点不同,它需要指明元对象,`_estimator_type`。这里不再展开论述,感兴趣的读者请阅读这篇讨论 [What is a mixin, and why are they useful?](https://stackoverflow.com/questions/533631/what-is-a-mixin-and-why-are-they-useful)
可以看到,这个混入类的实现非常简单,求预测值和真实值的准确率,返回值是一个浮点数。注意预测值来自`self.predict()`,所以继承混入类的类必须自己实现`predict`方法,否则引发错误。后面不再重复强调该细节。
再次的,分类任务的混入类又是在搬运其它函数的劳动成果,那我们就来研究一下`accuracy_score`的实现细节
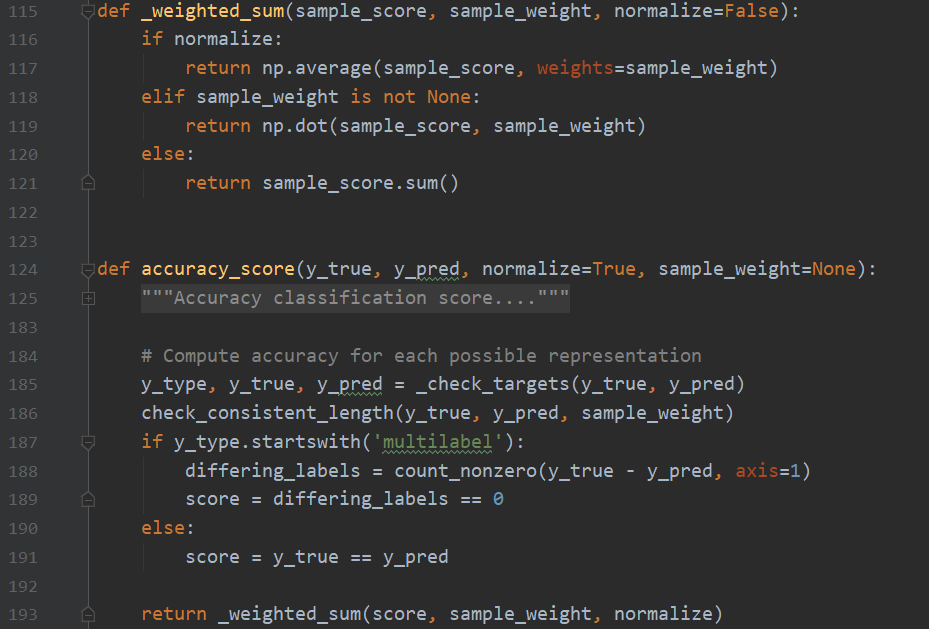
为简洁起见,我们先忽略L185~189之间的代码,后面会有专门研究分类任务的度量方法的文章,在那里我们再仔细研究它。直接看L191,`y_ture == y_pred`,这是一个简单的写法,精妙在于避免了for循环,快速的检查两个对象之间每一个元素是否相等并且返回True/False。L193对score结果做一层包装。
- L116:如果设置了`normalize`参数为True,则对score列表取平均值,就是预测正确的样本个数/总体个数=预测准确率
- L118:如果有权重,则按照权重对各个样本的得分进行加权,作为最终的预测准确率
- L121:如果没有上述两种设置,则直接返回预测正确的样本的个数。注意:sklearn默认的`score`方法返回预测准确率,而非预测正确的样本个数。
## RegressorMixin
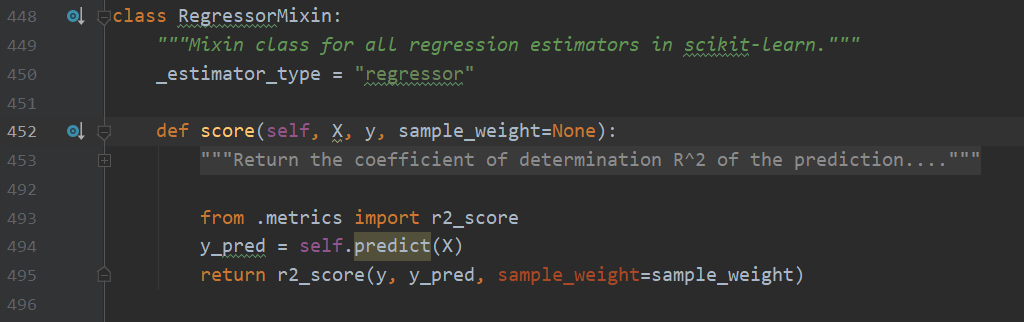
毫不意外地,回归任务的混入类只实现了`score`方法,核心数学原理是 $R^2$ 值。公式是 1-((y_true - y_pred)**2)/((y_true - y_true_mean)**2),直观上看,这个值是衡量预测值与真实值的偏离度与真实值自身偏离度的一个比值。 $R^2$最大为1,表示预测完全准确,值为0时表示模型没有任何预测能力。
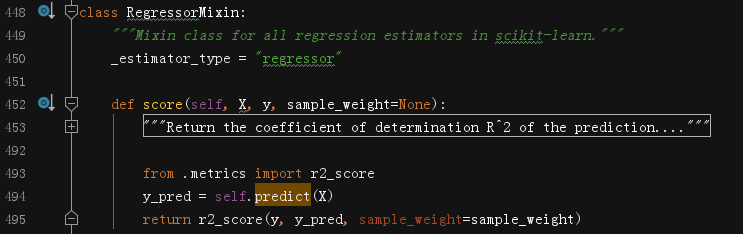
`score`方法调用了`metrics`模块的`r2_score`方法,返回值是浮点数。我们来研究下`r2_score`,这个函数是目前为止我们看过的最复杂的一个。因此,我们一块一块来研究。
### 检查传入的对象

(1)检查传入对象的长度
L577调用`check_consistent_length`检查输入标签、输出标签、权重是不是有相同的长度。检查的方法也很简单,对每个对象计算长度,然后取不同的长度值有多少个,如果超过1个,说明几个对象之间的长度不一,则引发一个错误来警告。

(2)检查传入的参数是否合法
L575调用`_check_reg_targets`方法,旨在检查传入参数是否合法。

这个函数略长,但是大致做了以下几件事:
- L83~95都是在做检查和格式转换。
- L97~114检查输入`multioutput`和`y_true`是否吻合,即真实的标签数组的维度如果是1的话,显然设置`multioutput`这个参数非None是不合法的。并且当真实标签数组的维度大于1的时候,若其维度和`multioutput`不同时也会引发错误以告警。
- L115根据`y_true`的维度决定标签是哪种类型,分为:连续型和多类输出的连续型。
注意:`multioutput`可以是字符串,也可以是一个数组,还可以是None值(考虑到向下兼容),因此这个参数非常灵活。后面研究具体算法时遇到了会再次提及,此处不作过多纠缠。
### 检查样本数和权重系数
继续看`r2_score`的实现:
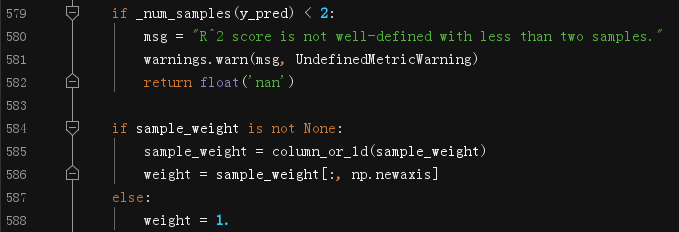
(3)L597~582检查预测值的样本数
如果预测值的样本数不足2个,则引发错误告警。因为决定系数(即$R^2$)要求至少要有2个样本
(4)L584~588处理权重系数
- L585调用`np.ravel()`,把权重数组拉平到一维
- L586对`sample_weights`扩维,将一维扩充为二维,二维扩充为三维,以此类推。值得注意的是,`np.newaxis`放置的位置不同,扩充的方向是不同的,具体看下面这个小例子:
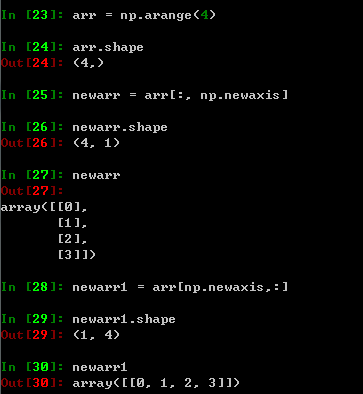
- L588,如果没有传入权重系数,则默认设置为1
### 实现$R^2$的计算细节
(5)构造分子和分母

(6)计算每个样本的得分

- L595~596 记录分母和分子的数组中不为0的索引值(就是非0值所在的位置)
- L597 记录分子、分母同时不为0的样本的索引值。如果对这个写法不熟悉,这里有个小例子帮助理解:
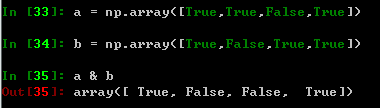
- L598~599 创建一个和真实标签相同长度的全1数组,然后对合法的索引位置计算真实的$R^2$值。
- L603 将分母为0的索引位置的值设置为0,这里设为其他常数也是可以的,对于同一个回归任务的评价没有影响。
(7)根据`multioutput`参数来决定各样本所得分数的权重

- L605~607 如果指明`raw_values`,则输出每个样本的分数
- L608~610 如果指明`uniform_average`,则avg_weights设置为None,其实就是均匀分布权重
- L611~612 如果指明`variance_weighted`,则直接用分母作权重
- L614~618 处理常量y值或一维数组的情形。如果分母全是0,则:若分子有非0,直接返回1;否则返回0
- L620 如果`multioutput`不是字符串,则直接把它作为最后的权重系数
(8)返回得分
```Python
return np.average(output_scores, weights=avg_weights)
```
刚刚说到,指明`uniform_average`,则avg_weights设置为None。在`numpy.average`这个方法里,如果权重是None,计算均值就是简单的`mean()`函数。
## TransformerMixin
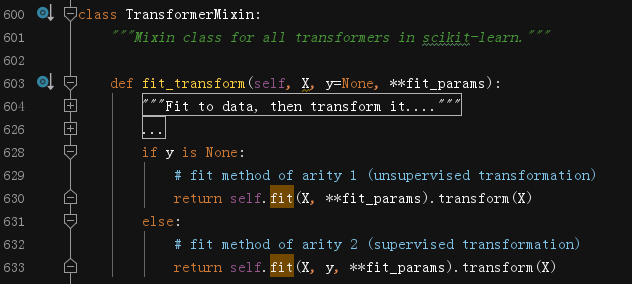
这个混入类的实现比较简单,完全依靠使用它的类自己实现的`fit`方法和`transform`方法。但是它会根据是否有标签,决定是有监督任务还是无监督任务。等后面遇到再具体讨论。
## 补充
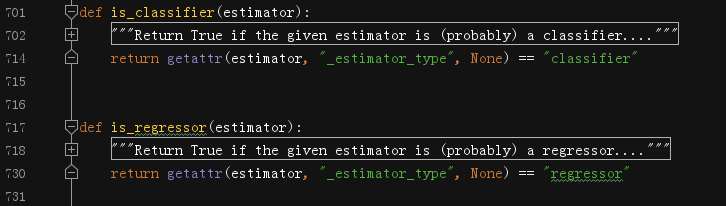
我们在研究分类混入类和回归混入类的时候,都发现有`_estimator_type`这个变量,它的具体作用就是这里看到的,判断一个估计器是用于分类任务还是回归任务的。
---
*如果有任何纰漏差错,欢迎评论互动。*

加载全部内容