下载网页中的 pdf 各种姿势,教你如何 carry 各种网页上的 pdf 文档。
Juwan 人气:1
> 关联词: PDF 下载 FLASH 网页 HTML 报告 内嵌 浏览器 文档 FlexPaperViewer swfobject。
这个需求是最近帮一个妹子处理一下各大高校网站里的 PDF 文档下载,又增加了无用的逆向知识 XD ,根据这些思路,可以有效的下载这类网站的文档文件。
这需要你有点 HTML5 和 Flash 时代的基础认知,顺便能看 F12 的 network 、cache 等内容,推算真实地址等。
我从最简单的说起,首先准备一个谷歌浏览器,有趣的是需要谷歌浏览器的打印功能,导出到 PDF 上,最后还需要福昕 PDF 编辑器批量合并图片成 PDF 文档。
## 第一种样本,是直接的 .pdf 该类直接下载即可,没有难度。
- http://zjc.suda.edu.cn/_upload/article/files/5f/cd/6352cea9466b80a3677983aab1ef/72cd882e-8bf8-4021-9960-553ebc770e4d.pdf
## 第二种样本,是现代 H5 + JS 内嵌 PDF 浏览器的方式。
属于现代 H5 JS 的产物,需要用 F12 开发者工具看源码推断 PDF 文件路径,接下来截图举例。
- http://www.nuaa.edu.cn/2020/0108/c295a192335/page.htm
对其右键选检查,此时进入 F12 的 HTML 元素审查位置,可以找到它的定义代码。
仔细看标签内容可以发现,存在 data-url="/_upload/article/files/3d/8d/78ed42f44031bcb6793b0eb27af1/8e6ad93b-4902-4fd8-bba5-bfabaf852885_1.png" 这类标签。
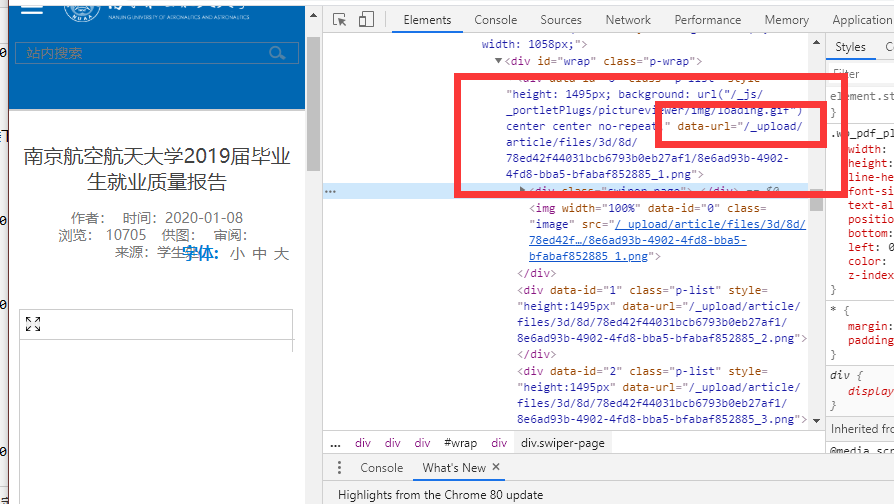
试图搜索(Ctrl + F)页面内容中的 .pdf 文件后缀,就会发现它的文件源存在了 pdfsrc="/_upload/article/files/3d/8d/78ed42f44031bcb6793b0eb27af1/8e6ad93b-4902-4fd8-bba5-bfabaf852885.pdf" 。
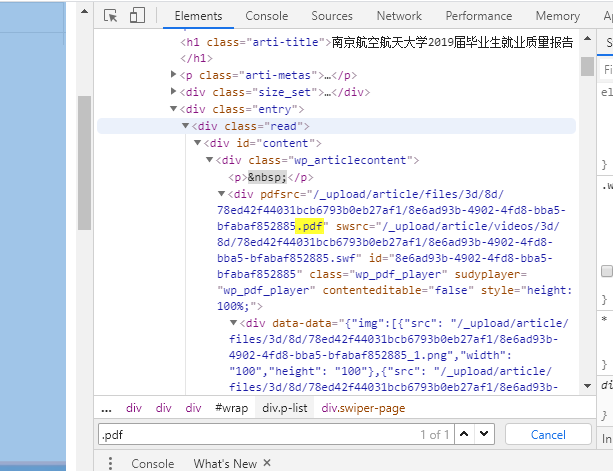
此时需要确定它的服务器源,从而获取真实地址,可以绝大概率是从这里来的。
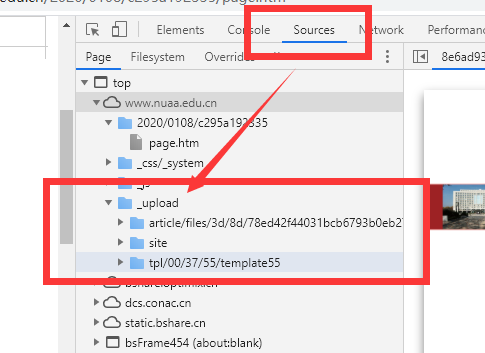
因此地址改为 http://www.nuaa.edu.cn//_upload/article/files/3d/8d/78ed42f44031bcb6793b0eb27af1/8e6ad93b-4902-4fd8-bba5-bfabaf852885.pdf 就出来了。
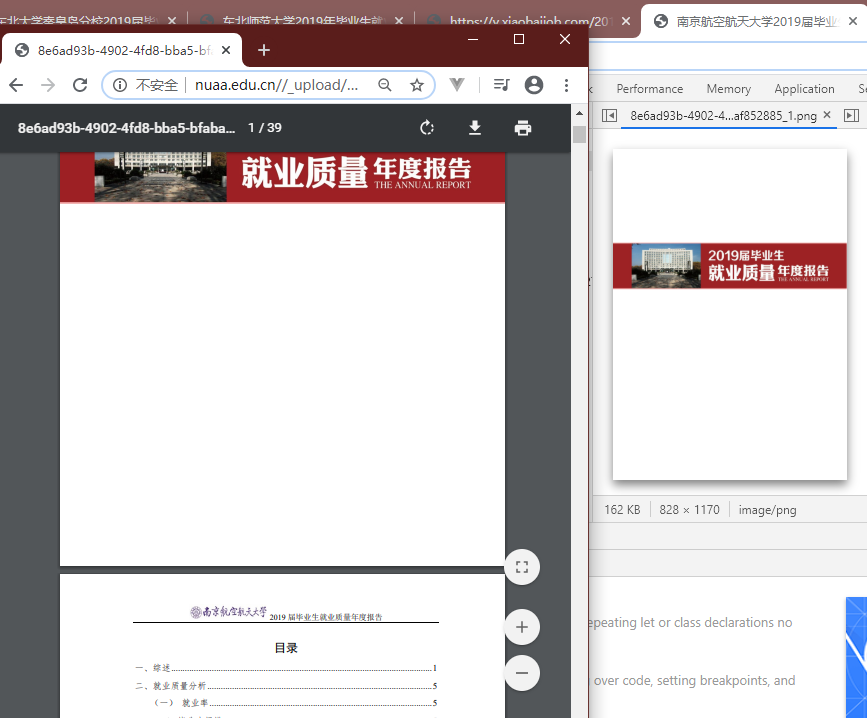
觉得还不太相信?那就再来一个。
- http://zjc.suda.edu.cn/88/5c/c5230a362588/page.htm
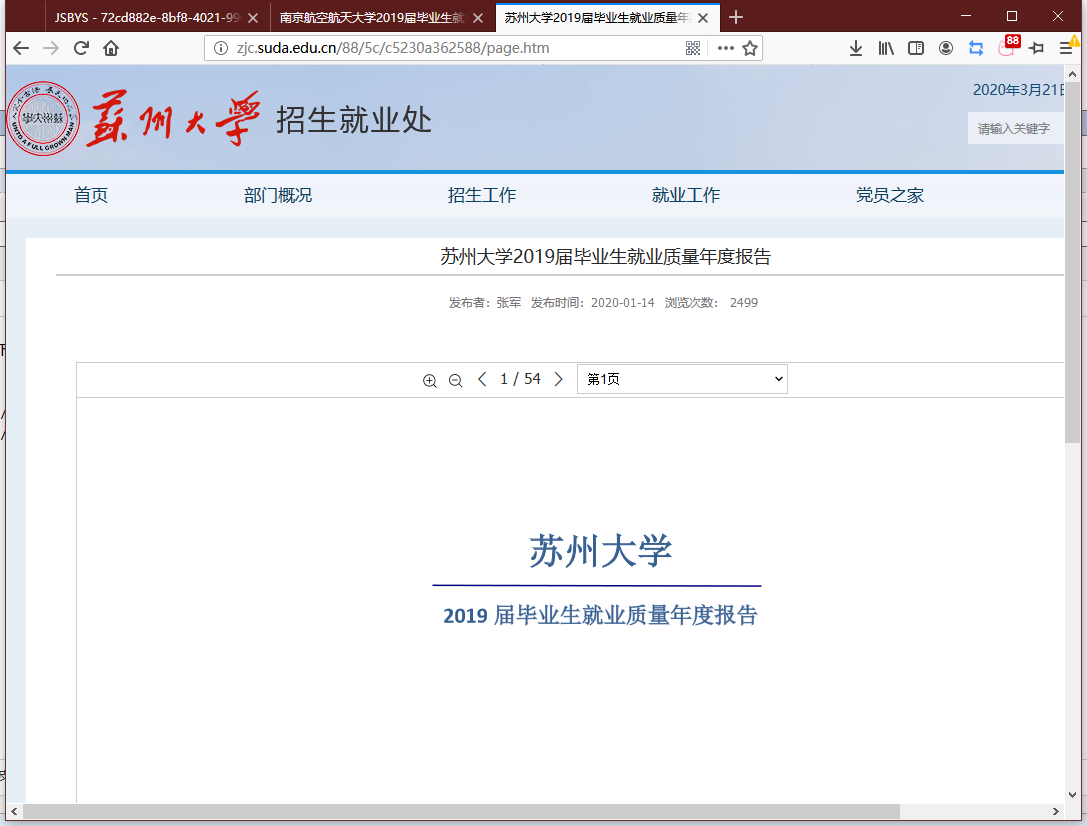
直接进 F12 直接搜 .pdf 直接找到源直接替换直接得到文件路径。
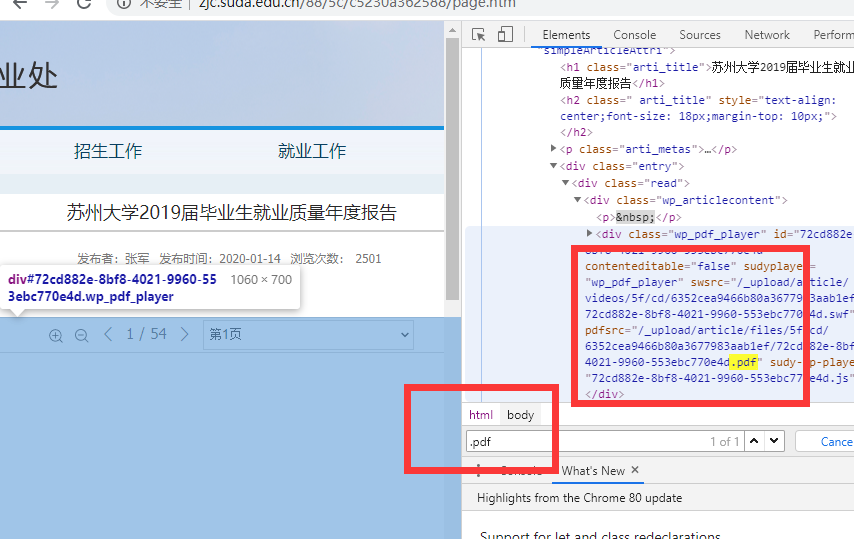
直接得到 http://zjc.suda.edu.cn//_upload/article/files/5f/cd/6352cea9466b80a3677983aab1ef/72cd882e-8bf8-4021-9960-553ebc770e4d.pdf 就是了。
聪明的你学会了吗?接着我们进入第三种样本吧。
## 第三种样本,旧时代的遗留产物 FLASH 下的 PDF 文档
这个需要一点编程基础了,我之前思路走歪了,现代电脑已经不支持过去的 Flash 软件了,我先是获取了 swf 后试图转换图片、反编译其内容,但能够在 Win10 上 work 的软件已经不多了。
最后痛定思痛,想起,我是个程序猿鸭,为什么要这么耿直的使用工具呢?没错,我直接怼代码进去了,就可以解决了嘻嘻,接下来就是复现这个过程。
- http://job.neuq.edu.cn/content.jsp?urltype=news.NewsContentUrl&wbtreeid=1022&wbnewsid=1978&&tdsourcetag=s_pcqq_aiomsg
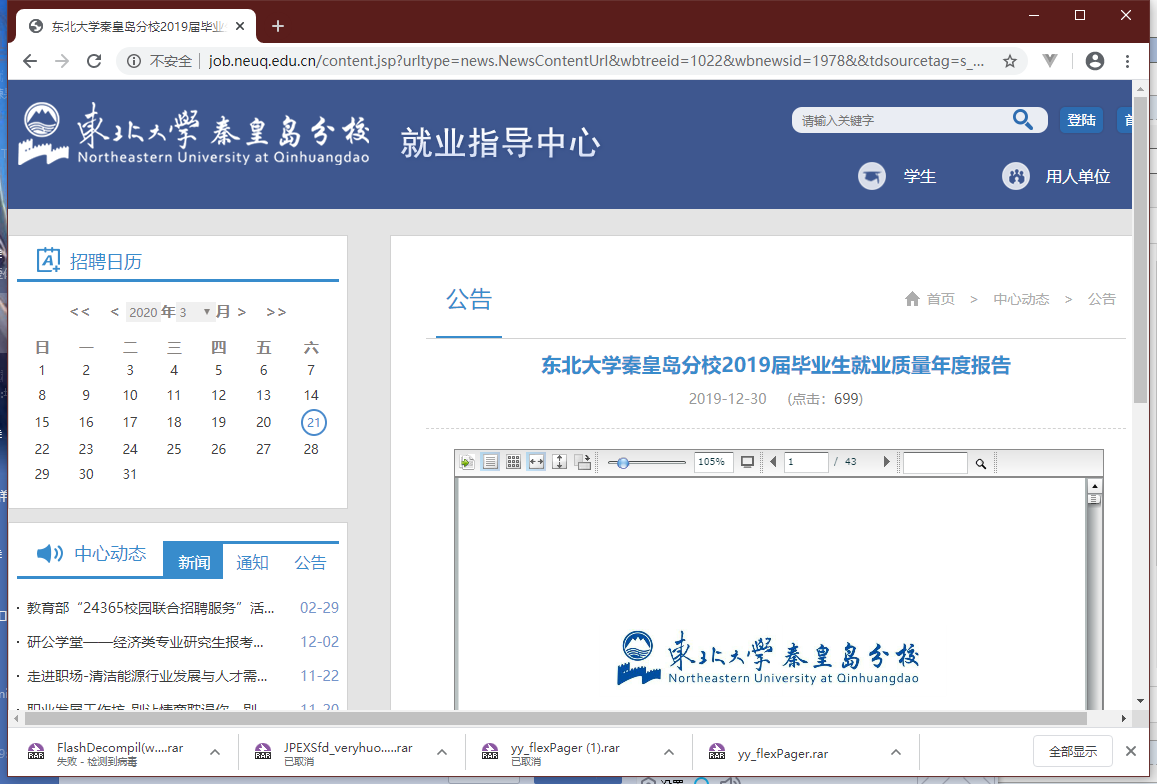
从右键我们可以得知它是 flash 播放器,这个真的没办法通过 html 得到,那么怎么办呢。

搜索 .pdf 或 .doc 都没用了,根本得不到它的文件,反而可以得到 swf 文件,讲道理,如果是早年间的电脑,相关工具应该还是可以解决问题的,如 swf2png 这类工具。
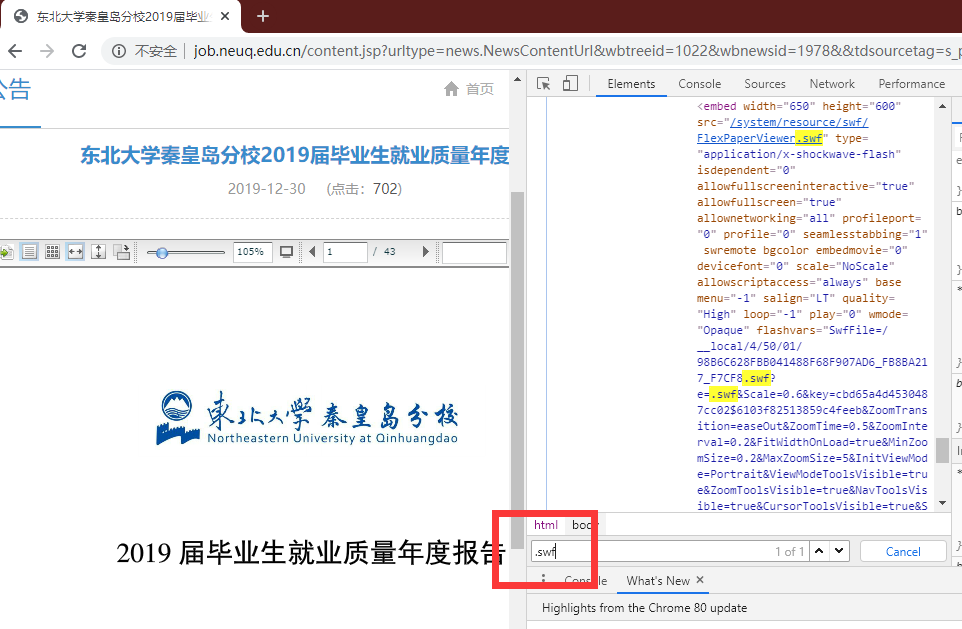
但是 win10 已经无法正常 work 了,那么我在这个地方浪费了很久以后,仔细看了一下它的组件,对,就是 /system/resource/swf/FlexPaperViewer.swf 挺古老的东西了。
> 顺便一提,谷歌浏览器将在 2020年12月终止 flash 组件。
那么,正面转换 swf 已经不现实了,我开始阅读标签代码,如下图。
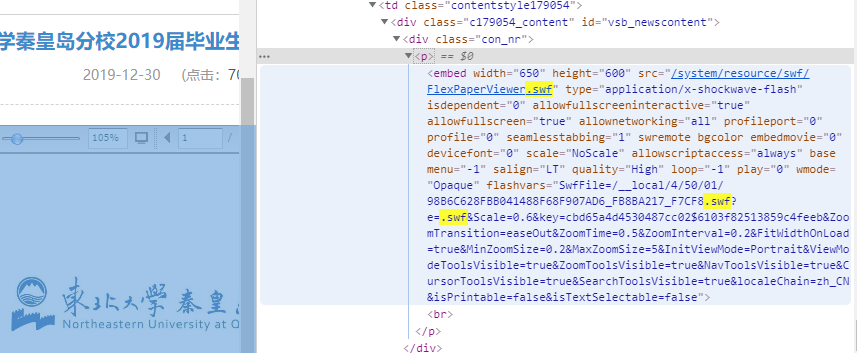
```html
加载全部内容