曹工说Spring Boot源码(23)-- ASM又立功了,Spring原来是这么递归获取注解的元注解的
三国梦回 人气:0
# 写在前面的话
相关背景及资源:
[曹工说Spring Boot源码(1)-- Bean Definition到底是什么,附spring思维导图分享](https://www.cnblogs.com/grey-wolf/p/12044199.html)
[曹工说Spring Boot源码(2)-- Bean Definition到底是什么,咱们对着接口,逐个方法讲解](https://www.cnblogs.com/grey-wolf/p/12051957.html )
[曹工说Spring Boot源码(3)-- 手动注册Bean Definition不比游戏好玩吗,我们来试一下](https://www.cnblogs.com/grey-wolf/p/12070377.html)
[曹工说Spring Boot源码(4)-- 我是怎么自定义ApplicationContext,从json文件读取bean definition的?](https://www.cnblogs.com/grey-wolf/p/12078673.html)
[曹工说Spring Boot源码(5)-- 怎么从properties文件读取bean](https://www.cnblogs.com/grey-wolf/p/12093929.html)
[曹工说Spring Boot源码(6)-- Spring怎么从xml文件里解析bean的](https://www.cnblogs.com/grey-wolf/p/12114604.html )
[曹工说Spring Boot源码(7)-- Spring解析xml文件,到底从中得到了什么(上)](https://www.cnblogs.com/grey-wolf/p/12151809.html)
[曹工说Spring Boot源码(8)-- Spring解析xml文件,到底从中得到了什么(util命名空间)](https://www.cnblogs.com/grey-wolf/p/12158935.html)
[曹工说Spring Boot源码(9)-- Spring解析xml文件,到底从中得到了什么(context命名空间上)](https://www.cnblogs.com/grey-wolf/p/12189842.html)
[曹工说Spring Boot源码(10)-- Spring解析xml文件,到底从中得到了什么(context:annotation-config 解析)](https://www.cnblogs.com/grey-wolf/p/12199334.html)
[曹工说Spring Boot源码(11)-- context:component-scan,你真的会用吗(这次来说说它的奇技淫巧)](https://www.cnblogs.com/grey-wolf/p/12203743.html)
[曹工说Spring Boot源码(12)-- Spring解析xml文件,到底从中得到了什么(context:component-scan完整解析)](https://www.cnblogs.com/grey-wolf/p/12214408.html)
[曹工说Spring Boot源码(13)-- AspectJ的运行时织入(Load-Time-Weaving),基本内容是讲清楚了(附源码)](https://www.cnblogs.com/grey-wolf/p/12228958.html)
[曹工说Spring Boot源码(14)-- AspectJ的Load-Time-Weaving的两种实现方式细细讲解,以及怎么和Spring Instrumentation集成](https://www.cnblogs.com/grey-wolf/p/12283544.html)
[曹工说Spring Boot源码(15)-- Spring从xml文件里到底得到了什么(context:load-time-weaver 完整解析)](https://www.cnblogs.com/grey-wolf/p/12288391.html)
[曹工说Spring Boot源码(16)-- Spring从xml文件里到底得到了什么(aop:config完整解析【上】)](https://www.cnblogs.com/grey-wolf/p/12314954.html)
[曹工说Spring Boot源码(17)-- Spring从xml文件里到底得到了什么(aop:config完整解析【中】)](https://www.cnblogs.com/grey-wolf/p/12317612.html)
[曹工说Spring Boot源码(18)-- Spring AOP源码分析三部曲,终于快讲完了 (aop:config完整解析【下】)](https://www.cnblogs.com/grey-wolf/p/12322587.html)
[曹工说Spring Boot源码(19)-- Spring 带给我们的工具利器,创建代理不用愁(ProxyFactory)](https://www.cnblogs.com/grey-wolf/p/12359963.html)
[曹工说Spring Boot源码(20)-- 码网恢恢,疏而不漏,如何记录Spring RedisTemplate每次操作日志](https://www.cnblogs.com/grey-wolf/p/12375656.html)
[曹工说Spring Boot源码(21)-- 为了让大家理解Spring Aop利器ProxyFactory,我已经拼了](https://www.cnblogs.com/grey-wolf/p/12384356.html)
[曹工说Spring Boot源码(22)-- 你说我Spring Aop依赖AspectJ,我依赖它什么了](https://www.cnblogs.com/grey-wolf/p/12418425.html)
[工程代码地址](https://gitee.com/ckl111/spring-boot-first-version-learn ) [思维导图地址](https://www.processon.com/view/link/5deeefdee4b0e2c298aa5596)
工程结构图:

# 概要
spring boot源码系列,离上一篇,快有2周时间了,这两周,本来是打算继续写这个系列的;结果中间脑热,就去实践了一把动态代理,实现了一个mini-dubbo这样一个rpc框架,扩展性还是相当好的,今天看了下spring mvc的设计,思路差不多,都是框架提供默认的组件(比如handlermapping),然后程序里自定义了的话,就覆盖默认组件。
然后,因为mini-dubbo实现过程中的一些其他问题,以及工作上的需要,写了netty实现的http 连接池,这个系列还没讲完,留着后边再补,不然我们的源码系列就耽搁太久了,今天我们还是接着回来弄源码系列。
今天这讲,主题是:给你一个class,怎么读取其上的注解,需要考虑注解的元注解(可以理解注解上的注解)
# 读取class上的注解
## 常规做法
我们的Class类,就有很多获取annotation的方法,如下:
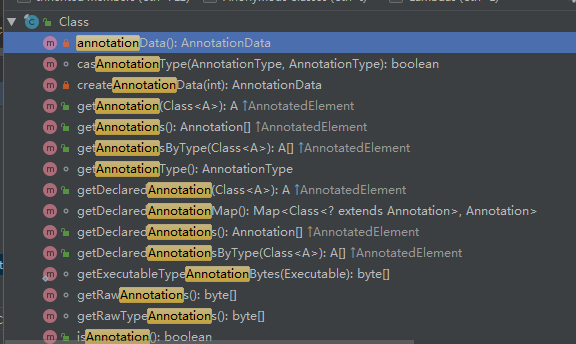
但是,这个有一个问题是,无法递归获取。
比如,大家使用spring的,都知道,controller这个注解上,是注解了component的。

如果你在一个标注了@controller注解的类的class上,去获取注解,是拿不到Component这一层的。
为啥要拿Component这一层呢?你可以想一下,最开始写spring的作者,是只定义了Component这个注解的,业务逻辑也只能处理Component这个注解;后来呢,又多定义了@controller,@service这几个,但是,难道要把所有业务逻辑的地方都去改一改?很明显,你不会,大佬更不会,直接解析@controller注解,看看它的元注解有没有@component就行了,有的话,直接复用之前的逻辑。
那么,如何进行递归解析呢?
## 递归解析类上注解--方法1
我们要获取的class,长这样:
```java
package org.springframework.test;
@CustomController
public class TestController {
}
@Documented
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Controller
public @interface CustomController {
}
```
这个方法,是从spring 源码里摘抄的,在内部实现中,基本就这个样子:
```java
我这个版本是4.0,在:org.springframework.bootstrap.sample.Test#recusivelyCollectMetaAnnotations
public static void getAnnotationByClass(String className) throws ClassNotFoundException {
Class<?> clazz = Class.forName(className);
Set metaAnnotationTypeNames = new LinkedHashSet();
for (Annotation metaAnnotation : clazz.getAnnotations()) {
recusivelyCollectMetaAnnotations(metaAnnotationTypeNames, metaAnnotation);
}
}
private static void recusivelyCollectMetaAnnotations(Set visited, Annotation annotation) {
if (visited.add(annotation.annotationType().getName())) {
for (Annotation metaMetaAnnotation : annotation.annotationType().getAnnotations()) {
//递归
recusivelyCollectMetaAnnotations(visited, metaMetaAnnotation);
}
}
}
```
我试了下,这个方法在新版本里,方法名变了,核心还是差不多,spring 5.1.9可以看这个类:
`org.springframework.core.type.classreading.AnnotationAttributesReadingVisitor#recursivelyCollectMetaAnnotations`
输出如下:
> java.lang.annotation.Documented
> java.lang.annotation.Retention
> java.lang.annotation.Target
> org.springframework.stereotype.Controller
> org.springframework.stereotype.Component
## 递归解析类上注解--方法2
这个是我自己实现的,要复杂一些,当然,是有理由的:
```java
import org.springframework.core.type.AnnotationMetadata;
import org.springframework.core.type.classreading.MetadataReader;
import org.springframework.core.type.classreading.SimpleMetadataReaderFactory;
public static void main(String[] args) throws IOException, ClassNotFoundException {
SimpleMetadataReaderFactory simpleMetadataReaderFactory = new SimpleMetadataReaderFactory();
LinkedHashSet result = new LinkedHashSet<>();
getAnnotationSet(result, "org.springframework.test.TestController", simpleMetadataReaderFactory);
}
public static void getAnnotationSet(LinkedHashSet result, String className, SimpleMetadataReaderFactory simpleMetadataReaderFactory) throws IOException {
boolean contains = result.add(className);
if (!contains) {
return;
}
MetadataReader metadataReader = simpleMetadataReaderFactory.getMetadataReader(className);
AnnotationMetadata annotationMetadata = metadataReader.getAnnotationMetadata();
Set annotationTypes = annotationMetadata.getAnnotationTypes();
if (!CollectionUtils.isEmpty(annotationTypes)) {
for (String annotationType : annotationTypes) {
// 递归
getAnnotationSet(result, annotationType, simpleMetadataReaderFactory);
}
}
}
```
估计有的同学要骂人了,取个注解,搞一堆莫名其妙的工具类干嘛?因为,spring就是这么玩的啊,方法1,是spring的实现,不假。但是,那个已经是最内层了,人家外边还封装了一堆,封装出来,基本就是方法2看到的那几个类。
##spring抽象出的注解获取的核心接口
大家看看,就是下面这个,类图如下:

其大致的功能,看下图就知道了:
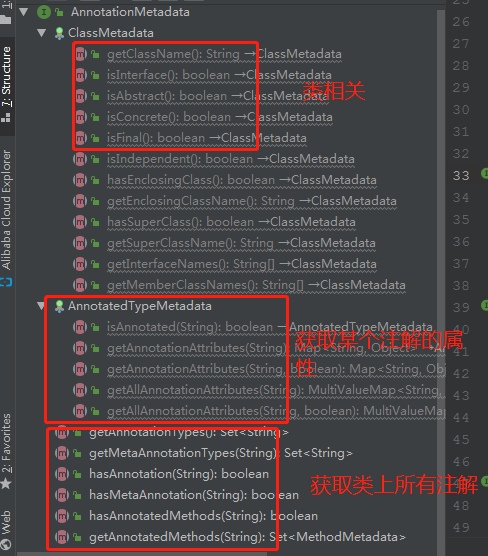
这个接口,一共2个实现,简单来说,一个是通过传统的反射方式来获取这些信息,一个是通过asm的方式。
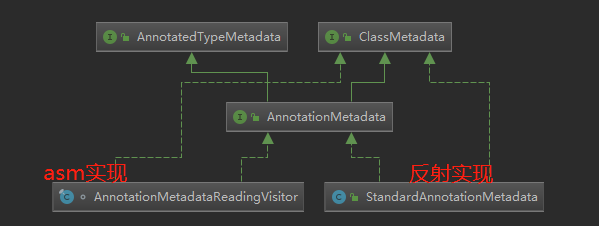
两者的优劣呢,大家可以看看小马哥的书,里面提到的是,asm方式的性能,远高于反射实现,因为无需加载class,直接解析class文件的字节码。
我们这里也是主要讲asm方式的实现,大家看到了上面这个asm实现的类,叫:AnnotationMetadataReadingVisitor,它的类结构,如下:

从上图可以大致知道,其继承了ClassMetadataReadingVisitor,这个类,负责去实现ClassMetaData接口;它自己呢,就自己负责实现AnnotationMetadata接口。
我们呢,不是很关心类的相关信息,只聚焦注解的获取。
##AnnotationMetadataReadingVisitor如何实现AnnotationMetadata接口
AnnotationMetadata接口,我们最关注的就是下面这2个方法:
```java
// 获取直接注解在当前class上的注解
Set getAnnotationTypes();
// 获取某个直接注解的元注解,比如你这里传个controller进去,就能给你拿到controller这个注解的元注解
Set getMetaAnnotationTypes(String annotationType);
```
大家可以看到,它呢,给了2个方法,而不是一个方法来获取所有,可能有其他考虑吧,我们接着看。
###getAnnotationTypes的实现
这个方法,获取直接注解在target class上的注解。
那看看这个方法在AnnotationMetadataReadingVisitor的实现吧:
```java
public Set getAnnotationTypes() {
return this.annotationSet;
}
```
尴尬,看看啥时候给它赋值的:
```java
@Override
public AnnotationVisitor visitAnnotation(final String desc, boolean visible) {
String className = Type.getType(desc).getClassName();
this.annotationSet.add(className);
return new AnnotationAttributesReadingVisitor(className, this.attributeMap,
this.metaAnnotationMap, this.classLoader, this.logger);
}
```
方法名字,见名猜意思,:visit注解,可能还使用了visitor设计模式,但是这个方法又是什么时候被调用的呢
###asm简介
简单介绍下asm框架,官网:
官网说明如下:
> **ASM** is an all purpose Java bytecode manipulation and analysis framework. It can be used to modify existing classes or to dynamically generate classes, directly in binary form. ASM provides some common bytecode transformations and analysis algorithms from which custom complex transformations and code analysis tools can be built. ASM offers similar functionality as other Java bytecode frameworks, but is focused on [performance](https://asm.ow2.io/performance.html). Because it was designed and implemented to be as small and as fast as possible, it is well suited for use in dynamic systems (but can of course be used in a static way too, e.g. in compilers).
>
> ASM is used in many projects, including:
>
> - the [**OpenJDK**](http://openjdk.java.net/), to generate the [lambda call sites](http://hg.openjdk.java.net/jdk8/jdk8/jdk/file/687fd7c7986d/src/share/classes/java/lang/invoke/InnerClassLambdaMetafactory.java), and also in the [Nashorn](https://en.wikipedia.org/wiki/Nashorn_(JavaScript_engine)) [compiler](http://hg.openjdk.java.net/jdk8/jdk8/nashorn/file/096dc407d310/src/jdk/nashorn/internal/codegen/ClassEmitter.java),
> - the [**Groovy**](http://www.groovy-lang.org/) [compiler](https://github.com/apache/groovy/blob/GROOVY_2_4_15/src/main/org/codehaus/groovy/classgen/AsmClassGenerator.java) and the [**Kotlin**](https://kotlinlang.org/) [compiler](https://github.com/JetBrains/kotlin/blob/v1.2.30/compiler/backend/src/org/jetbrains/kotlin/codegen/ClassBuilder.java),
> - [**Cobertura**](http://cobertura.github.io/cobertura/) and [**Jacoco**](http://www.eclemma.org/jacoco/), to [instrument](https://github.com/cobertura/cobertura/blob/v1_9_4/src/net/sourceforge/cobertura/instrument/ClassInstrumenter.java) [classes](https://github.com/jacoco/jacoco/blob/v0.8.1/org.jacoco.core/src/org/jacoco/core/instr/Instrumenter.java) in order to measure code coverage,
> - [**CGLIB**](https://github.com/cglib/cglib), to dynamically generate [proxy](https://github.com/cglib/cglib/blob/RELEASE_3_2_6/cglib/src/main/java/net/sf/cglib/core/ClassEmitter.java) classes (which are used in other projects such as [**Mockito**](http://site.mockito.org/) and [**EasyMock**](http://easymock.org/)),
> - [**Gradle**](https://gradle.org/), to [generate](https://github.com/gradle/gradle/blob/v4.6.0/subprojects/core/src/main/java/org/gradle/api/internal/AsmBackedClassGenerator.java) some classes at runtime.
简单来说,就是:
> asm是一个字节码操作和分析的框架,能够用来修改已存在的class,或者动态生成class,直接以二进制的形式。ASM提供一些通用的字节码转换和分析算法,通过这些算法,可以构建复杂的字节码转换和代码分析工具。ASM提供和其他字节码框架类似的功能,但是其专注于性能。因为它被设计和实现为,尽可能的小,尽可能的快。
>
> ASM被用在很多项目,包括:
>
> OpenJDK,生成lambda调用;
>
> Groovy和Kotlin的编译器
>
> Cobertura和Jacoco,通过探针,检测代码覆盖率
>
> CGLIB,动态生成代理类,也用在Mockito和EasyMock中
>
> Gradle,运行时动态生成类
这里补充一句,ASM为啥说它专注于性能,因为,要动态生成类、动态进行字节码转换,如果性能太差的话,还有人用吗? 为啥要足够小,足够小因为它也希望自己用在一些内存受限的环境中。
查看了asm的官方文档,发现一个有趣的知识,asm这个名字,来源于c语言里面的`__asm__`关键字,这个关键字可以在c语言里用汇编来实现某些功能。
另外,其官方文档里提到,解析class文件的过程,有两种模型,一种是基于事件的,一种是基于对象的,可以类比xml解析中的sax和dom模型,sax就是基于事件的,同样也是和asm一样,使用visitor模式。
visitor模式呢,我的简单理解,就是主程序定义好了一切流程,比如我会按照顺序来访问一个class,先是class name,就去调用visitor的对应方法,此时,visitor可以做些处理;我访问到field时,也会调用visitor的对应方法...以此类推。
### asm怎么读取class
针对每个class,asm是把它当作一个Resource,其大概的解析步骤如下:
```java
import org.springframework.asm.ClassReader;
import org.springframework.core.NestedIOException;
import org.springframework.core.io.Resource;
import org.springframework.core.type.AnnotationMetadata;
import org.springframework.core.type.ClassMetadata;
SimpleMetadataReader(Resource resource, ClassLoader classLoader, MetadataReaderLog logger) throws IOException {
// 1.
InputStream is = new BufferedInputStream(resource.getInputStream());
ClassReader classReader = new ClassReader(is);
// 2.
AnnotationMetadataReadingVisitor visitor = new AnnotationMetadataReadingVisitor(classLoader, logger);
// 3.
classReader.accept(visitor, ClassReader.SKIP_DEBUG);
this.annotationMetadata = visitor;
// (since AnnotationMetadataReader extends ClassMetadataReadingVisitor)
this.classMetadata = visitor;
this.resource = resource;
}
```
各讲解点:
1. 读取class resource为输入流,作为构造器参数,new一个asm的ClassReader出来;
2. 新建一个AnnotationMetadataReadingVisitor类的实例,这个继承了ClassVisitor抽象类,这个visitor里面定义了一堆的回调方法:
```java
public abstract class ClassVisitor {
public ClassVisitor(int api);
public ClassVisitor(int api, ClassVisitor cv);
public void visit(int version, int access, String name,
String signature, String superName, String[] interfaces);
public void visitSource(String source, String debug);
public void visitOuterClass(String owner, String name, String desc);
// 解析到class文件中的注解时回调本方法
AnnotationVisitor visitAnnotation(String desc, boolean visible);
public void visitAttribute(Attribute attr);
public void visitInnerClass(String name, String outerName,String innerName,int access);
// 解析到field时回调
public FieldVisitor visitField(int access, String name, String desc,String signature, Object value);
// 解析到method时回调
public MethodVisitor visitMethod(int access, String name, String desc,
String signature, String[] exceptions);
void visitEnd();
}
```
这其中,方法的访问顺序如下:
```java
visit visitSource? visitOuterClass? ( visitAnnotation | visitAttribute )*
( visitInnerClass | visitField | visitMethod )*
visitEnd
代表:
visit必须最先访问;
接着是最多一次的visitSource,再接着是最多一次的visitOuterClass;
接着是任意多次的visitAnnotation | visitAttribute ,这两个,顺序随意;
再接着是,任意多次的visitInnerClass | visitField | visitMethod ,顺序随意
最后,visitEnd
```
这个顺序的? * () 等符号,其实类似于正则表达式的语法,对吧,还是比较好理解的。
然后呢,我对visitor的理解,现在感觉类似于spring里面的event listener机制,比如,spring的生命周期中,发布的事件,有如下几个,其实也是有顺序的:
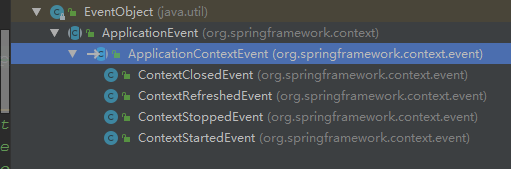
这里还有官网提供的一个例子:
```java
public class ClassPrinter extends ClassVisitor {
public ClassPrinter() {
super(ASM4);
}
public void visit(int version, int access, String name,
String signature, String superName, String[] interfaces) {
System.out.println(name + " extends " + superName + " {");
}
public void visitSource(String source, String debug) {
}
public void visitOuterClass(String owner, String name, String desc) {
}
public AnnotationVisitor visitAnnotation(String desc, boolean visible) {
return null;
}
public void visitAttribute(Attribute attr) {
}
public void visitInnerClass(String name, String outerName,String innerName, int access) {
}
public FieldVisitor visitField(int access, String name, String desc,String signature, Object value) {
System.out.println(" " + desc + " " + name);
return null;
}
public MethodVisitor visitMethod(int access, String name,String desc, String signature, String[] exceptions) {
System.out.println(" " + name + desc);
return null;
}
public void visitEnd() {
System.out.println("}");
}
}
```
3. 将第二步的visitor策略,传递给classReader,classReader开始进行解析
### getAnnotationTypes的回调处理

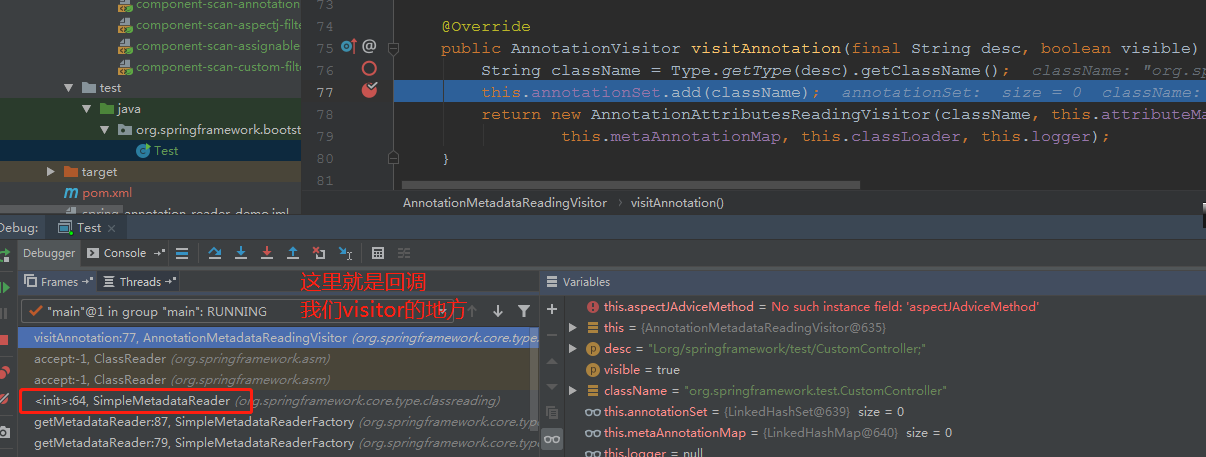
我们接着回到getAnnotationTypes的实现,大家看了上面2个图,应该大致知道visitAnnotation的实现了:
```java
@Override
public AnnotationVisitor visitAnnotation(final String desc, boolean visible) {
String className = Type.getType(desc).getClassName();
this.annotationSet.add(className);
return new AnnotationAttributesReadingVisitor(className, this.attributeMap,
this.metaAnnotationMap, this.classLoader, this.logger);
}
```
这里每访问到一个注解,就会加入到field: `annotationSet`中。
### 注解上的元注解,如何读取
大家再看看上面的代码,我们返回了一个AnnotationAttributesReadingVisitor,这个visitor会在:asm访问注解的具体属性时,其中的如下方法被回调。
```java
@Override
public void doVisitEnd(Class<?> annotationClass) {
super.doVisitEnd(annotationClass);
List attributes = this.attributesMap.get(this.annotationType);
if(attributes == null) {
this.attributesMap.add(this.annotationType, this.attributes);
} else {
attributes.add(0, this.attributes);
}
Set metaAnnotationTypeNames = new LinkedHashSet();
// 1
for (Annotation metaAnnotation : annotationClass.getAnnotations()) {
// 2
recusivelyCollectMetaAnnotations(metaAnnotationTypeNames, metaAnnotation);
}
if (this.metaAnnotationMap != null) {
this.metaAnnotationMap.put(annotationClass.getName(), metaAnnotationTypeNames);
}
}
// 3
private void recusivelyCollectMetaAnnotations(Set visited, Annotation annotation) {
if(visited.add(annotation.annotationType().getName())) {
this.attributesMap.add(annotation.annotationType().getName(),
AnnotationUtils.getAnnotationAttributes(annotation, true, true));
// 获取本注解上的元注解
for (Annotation metaMetaAnnotation : annotation.annotationType().getAnnotations()) { // 4 递归调用自己
recusivelyCollectMetaAnnotations(visited, metaMetaAnnotation);
}
}
}
```
1. 获取注解的元注解,比如,获取controller注解上的注解;这里就能取到Target、Retention、Documented、Component
```java
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
public @interface Controller
```
2. 循环处理这些元注解,因为这些元注解上,可能还有元注解,比如,在处理Target时,发现其上还有Documented、Retention、Target几个注解,看到了吧,target注解还注解了target,在这块的递归处理时,很容易栈溢出。
```java
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.ANNOTATION_TYPE)
public @interface Target {
```
3. 递归处理上面的这些注解
具体的处理,基本就是这样。文章开头的递归,就是摘抄的这里的代码。
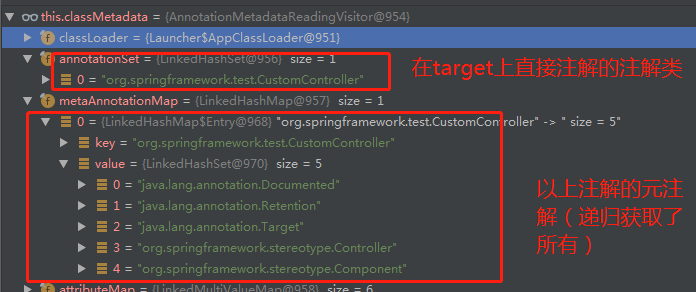
经过最终的处理后,可以看看最后的效果,这里截取的就是AnnotationMetadataReadingVisitor这个对象:
# 总结
这个就是spring 注解驱动的基石,实际上,spring不是一开始就这么完备的,在之前的版本,并不支持递归获取,spring也是慢慢一步一步发展壮大的。
感谢spring赏饭吃!
下一讲,会讲解component-scan扫描bean时,怎么扫描类上的注解的。
加载全部内容