ElasticSearch之映射常用操作
ytao丨杨滔 人气:2

本文案例操作,建议先阅读我之前的文章[《ElasticSearch之安装及基本操作API》](https://ytao.top/2019/12/14/11-elasticsearch/)
> Mapping (映射)类似关系型数据库中的表的结构定义。我们将数据以 JSON 格式存入到 ElasticSearch 中后,在搜索引擎中 JSON 字段映射对应的类型,这时需要 mapping 来定义内容的类型。
# 字段类型
JSON 数据类型映射到 ElasticSearch 定义的类型,常用的简单类型有:
JSON类型 | ElasticSearch 类型
:--:|:--:
文本类型 | Text/Keyword
整数类型 | long/integer
浮点类型 | floathttps://img.qb5200.com/download-x/double
时间类型 | date
布尔值 | boolean
数组 | Text/Keyword
上面要注意的是时间类型,JSON 中并没有时间类型,这里主要指时间格式数据的类型。
# 定义映射
在关系型数据库中,存储数据之前,我们会先创建表结构,给字段指定一个存在的类型。同样 ElasticSearch 在进行数据存储前,也可以先定义好存储数据的 Mapping 结构。
先定义一个简单的 person Mapping:
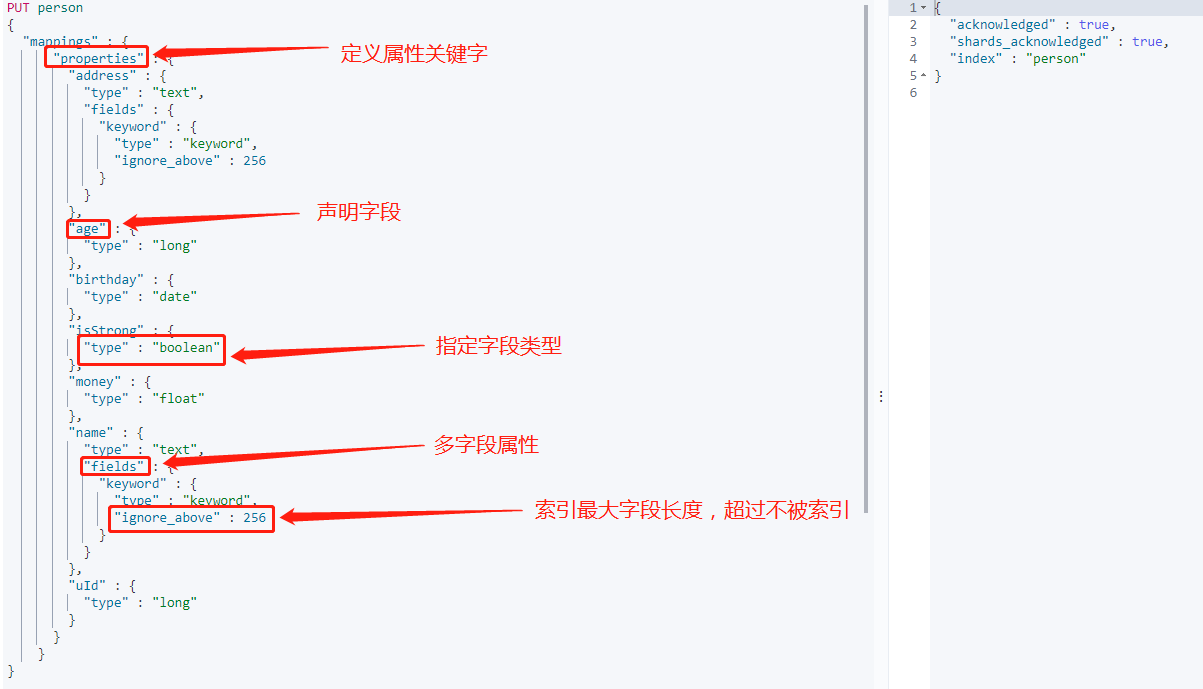
上图中就是一个 Mapping 的定义,如果是在 ElasticSearch7 之前,mappings 里还有 _type 属性。
# 动态映射
当没有事先定义好 Mapping,添加数据时,ElasticSearch 会自动根据字段进行换算出对应的类型,但是换算出来的类型并不一定是我们想要的字段类型,还是需要人为的干预进行修改成想要的 Mapping。
# 更新映射
使用 **dynamic** 控制映射是否可以被更新。
## dynamic-true
设置 dynamic 为`true`是默认 dynamic 的默认值,新增字段数据可以写入,同时也可以被索引,Mapping 结构也会被更新。

添加数据,同时多添加一个没被定义的 `gender` 字段。
```bash
# 向 person 中添加数据
PUT person/_doc/1
{
"uId": 1,
"name": "ytao",
"age": 18,
"address": "广东省珠海市",
"birthday": "2020-01-15T12:00:00Z",
"money": 108.2,
"isStrong": true,
"gender": "男" # Mapping 中未定义的字段
}
```
添加成功,搜索 `gender` 字段:
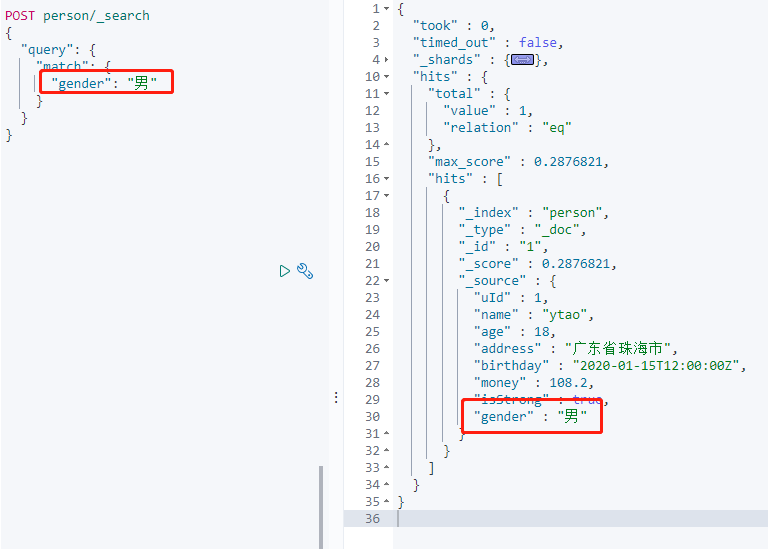
查看 Mapping 结构:
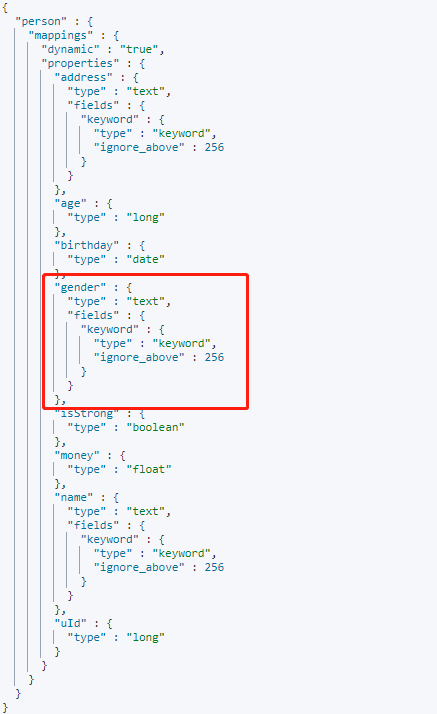
新添加的字段值,在添加过程中 Mapping 已自动添加字段。
## dynamic-false
设置 dynamic 为`false`时,新增字段数据可以写入,不可以被索引,Mapping 结构会被更新。
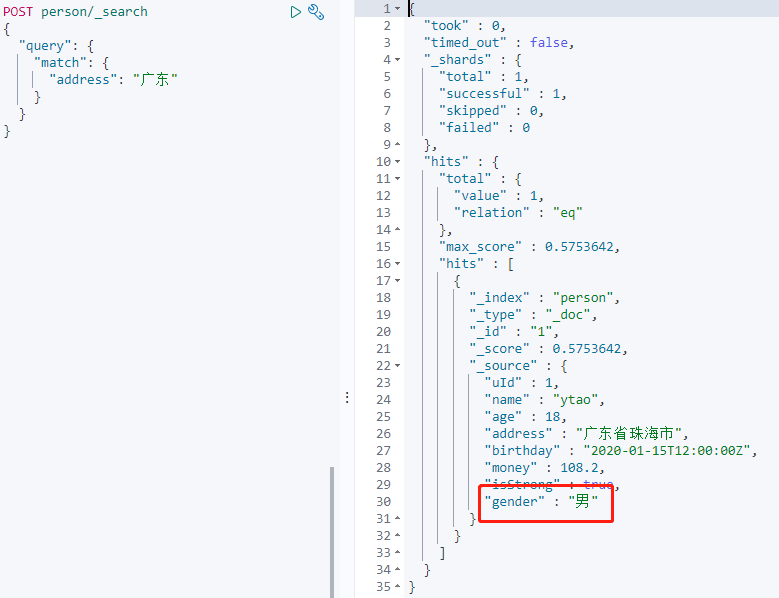
同样先将 dynamic 设置为 false,然后向里面添加数据,其他步骤和上面 true 操作一样。定义 Mapping,添加数据。
搜索 `gender` 字段:

此时新增字段数据无法被索引,但数据可以写入。
Mappnig 也不会添加新增的字段:
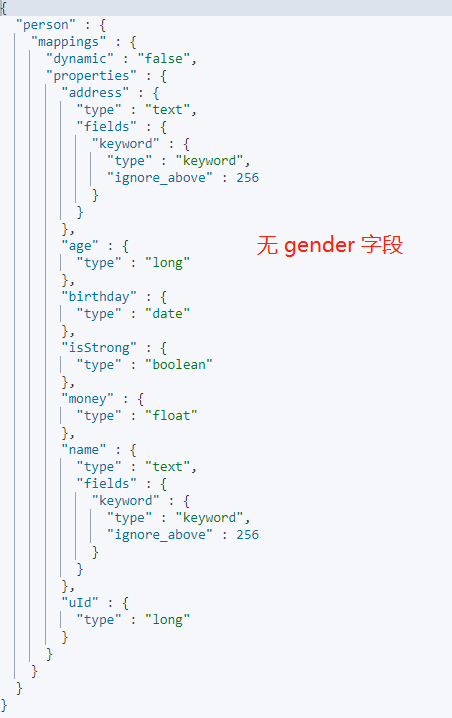
## dynamic-strict
设置 dynamic 为`strict`时,从字面上意思也可以看出,对于动态映射是较严格的,新增字段数据不可以写入,不可以被索引,Mapping 结构不会被更新。只能按照定义好的 Mapping 结构添加数据。
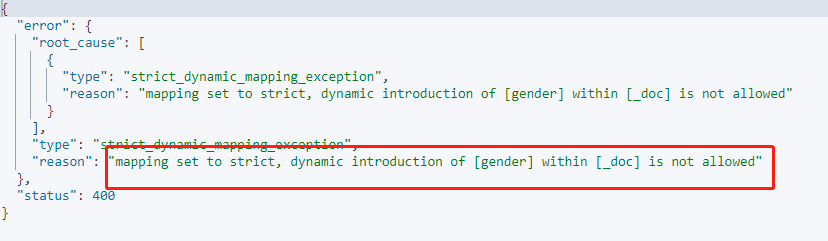
在添加新字段数据时,就马上会抛出异常:
# 自动识别日期类型
上文中,当 dynamic 设置为 true 时,添加新字段数据自动识别类型更新 Mapping,如果是日期类型的话,我们是可以指定识别的类型。
指定 person 的 **dynamic_date_formats** 格式:
```bash
PUT person/_mapping
{
"dynamic_date_formats": ["yyyy/MMhttps://img.qb5200.com/download-x/dd"]
}
```
这里是可以指定多个时间格式。
向 person 添加新数据,分别是 today 和 firstDate:
```bash
PUT person/_doc/2
{
"today": "2020-01-15",
"firstDate": "2020/01/15"
}
```
添加新字段数据后的 Mapping:
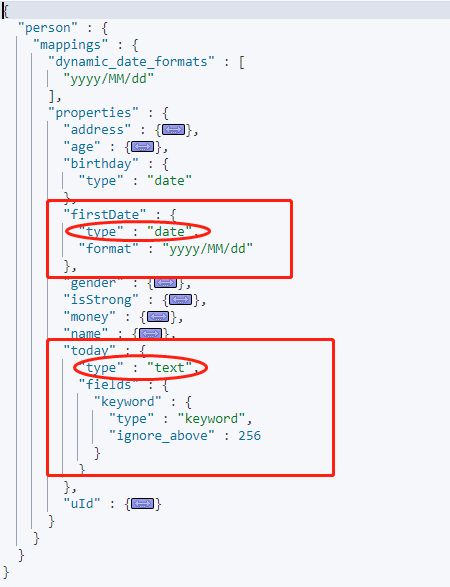
由于上面我们指定了时间格式为 `yyyy/MMhttps://img.qb5200.com/download-x/dd` 时是可以识别为时间格式,所以 today 字段的值为 `yyyy-MM-dd` 格式无法识别为时间类型,判为 text 类型。
# 多字段
Mapping 中可以定义 **fields** 多字段属性,以满足不同场景下的实现。比如 `address` 定义为 `text` 类型,fields 里面又有定义 `keyword` 类型,这里主要是区分两个不同不同使用场景。
- `text` 会建立分词倒排索引,用于全文检索。
- `keyword` 不会建立分词倒排索引,用于排序和聚合。
添加数据:
```bash
# 向 person 中添加数据
PUT person/_doc/1
{
"uId": 1,
"name": "ytao",
"age": 18,
"address": "广东省珠海市",
"birthday": "2020-01-15T12:00:00Z",
"money": 108.2,
"isStrong": true
}
```
查询`address`数据。

查询`address.keyword`数据。
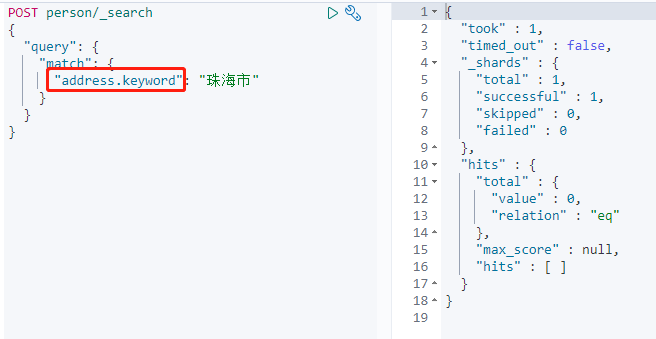
通过`keyword`检索时,由于不会建立分词索引,并没有获取到数据。
# 控制索引
在字段中使用 **index** 指定当前字段索引是否能被搜索到。指定类型为 boolean 类型,false 为不可搜索到,true 为可以搜索到。
先删除之前的 Mapping:
```bash
DELETE person
```
创建 Mapping,设置`name`属性的 `index` 为 false。
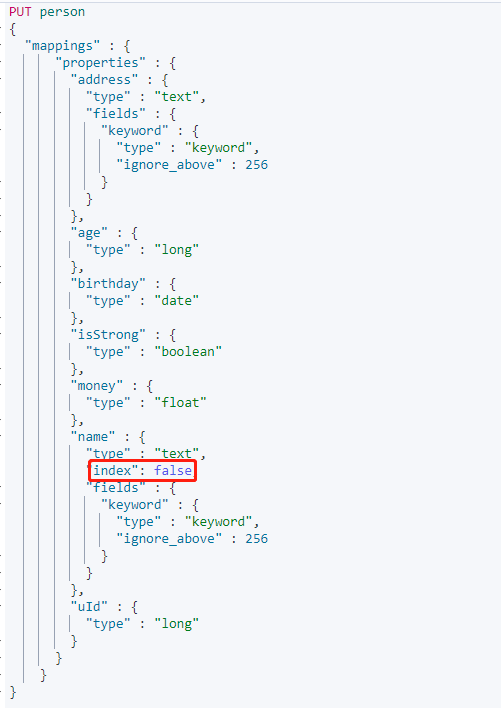
再次添加上面的数据后搜索`name`字段:
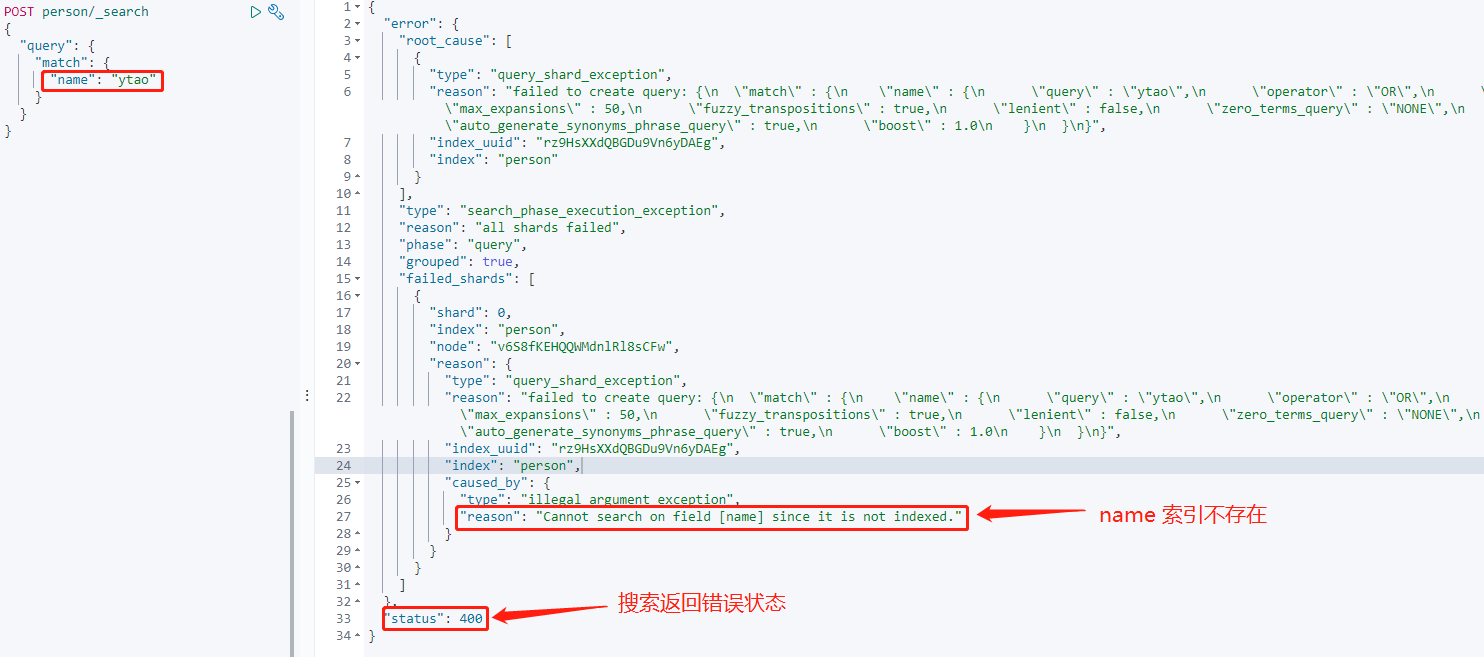
字段 index 设置 false 后,由于没有被索引,所以搜索无法获取到索引。
# 空值处理
现在向 ElasticSearch 中添加一条 address 为空的数据:
```bash
PUT person/_doc/2
{
"uId": 2,
"name": "Jack",
"age": 22,
"address": null,
"birthday": "2020-01-15T12:00:00Z",
"money": 68.7,
"isStrong": true
}
```
搜索 address.keyword 为空的数据:
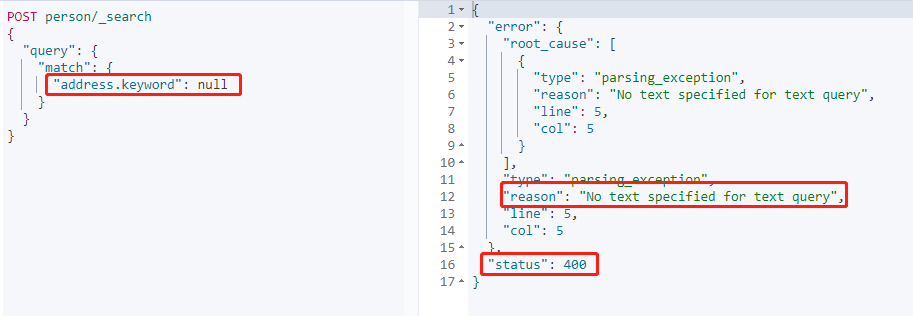
搜索返回异常,默认是不被允许搜索 NUll。
这是需要在 Mapping 指定 **null_value** 属性,并且不能在`text`类型中声明。
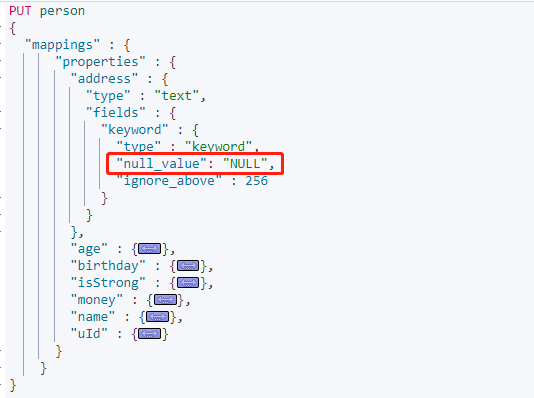
搜索 address.keyword 为空的数据:
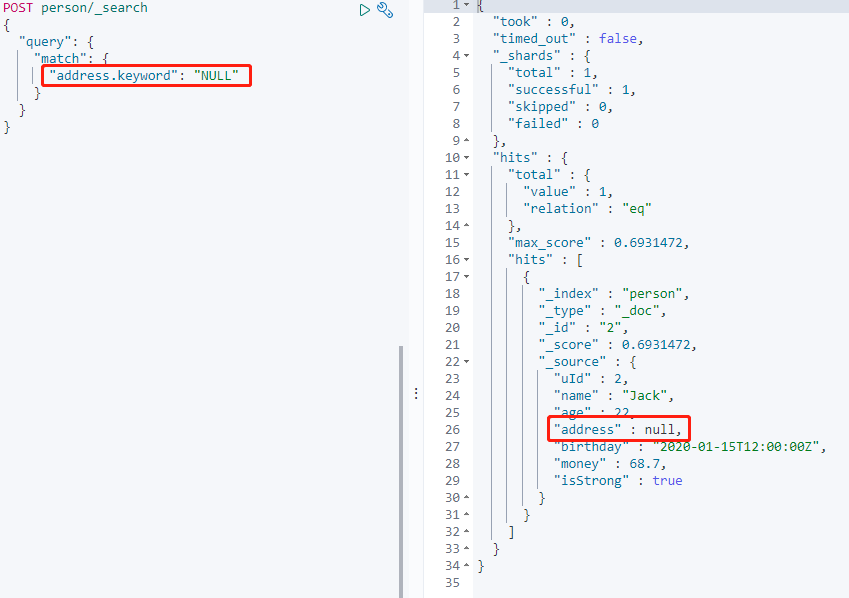
设置 `"null_value": "NULL"` 后,空值可以处理搜索。
# 聚合多个字段
聚合多个字段放到一个索引中,使用 **copy_to** 进行聚合。例如我们在多字段查询中,这是不需要对每个字段进行过滤筛选,只需对聚合字段即可。
在使用 copy_to 时,是通过指定聚合的名称实现。
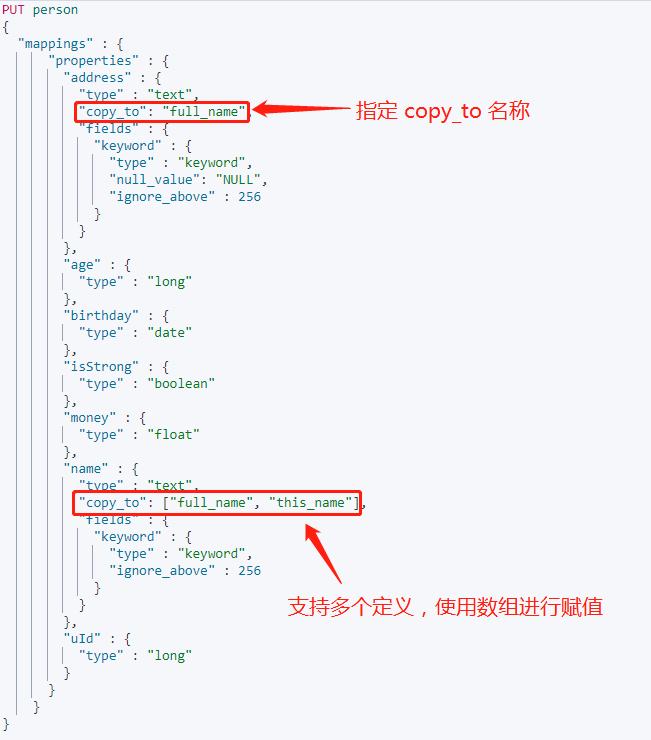
实际上,copy_to 不使用数组格式添加名称,也会自动转换成数据格式。
添加两条数据,待校验搜索:
```bash
# 向 person 中添加数据
PUT person/_doc/1
{
"uId": 1,
"name": "ytao",
"age": 18,
"address": "广东省珠海市",
"birthday": "2020-01-15T12:00:00Z",
"money": 108.2,
"isStrong": true
}
PUT person/_doc/2
{
"uId": 2,
"name": "杨广东",
"age": 22,
"address": null,
"birthday": "2020-01-15T12:00:00Z",
"money": 68.7,
"isStrong": true
}
```
查询 `full_name` 的值,会返回 name 和 address 相关的值的对象。
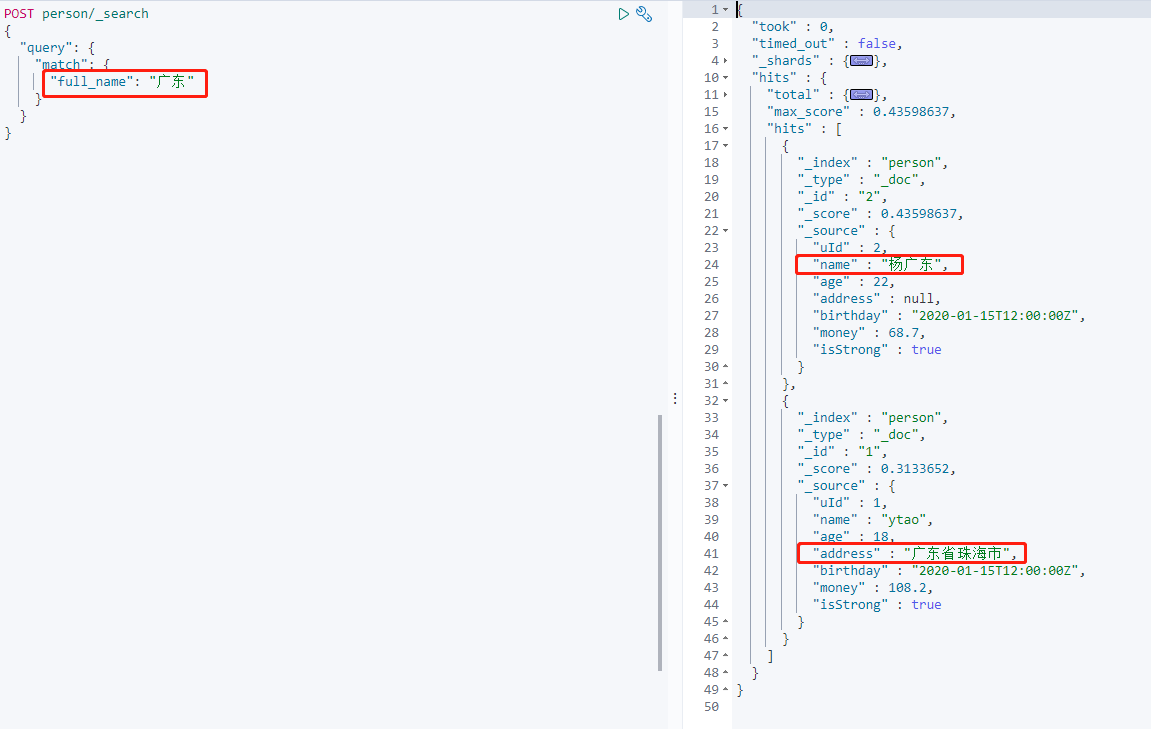
从上面返回结果看到,_source 中的字段没有增加相应的 copy_to 字段名,所以 copy_to 只会拷贝字段内容至索引,并不会改变包含的字段。
# 总结
> 通过本文对创建 Mapping 文件的常用并且实用的操作介绍,也基本能掌握这些日常的使用。了解 Mapping 的功能操作,相信对存储时的设计也有一定帮助。
个人博客: [https://ytao.top](https://ytao.top)
关注公众号 【ytao】,更多原创好文

加载全部内容