每天都在用 Map,这些核心技术你知道吗?
楼下小黑哥 人气:0
本篇文章站在多线程并发安全角度,带你了解多线程并发使用 `HashMap` 将会引发的问题,深入学习 `ConcurrentHashMap` ,带你彻底掌握这些核心技术。
全文摘要:
- `HashMap` 核心技术
- `ConcurrentHashMap` 核心技术
- 分段锁实战应用
## HashMap
`HashMap` 是我们经常会用到的集合类,JDK 1.7 之前底层使用了数组加链表的组合结构,如下图所示:
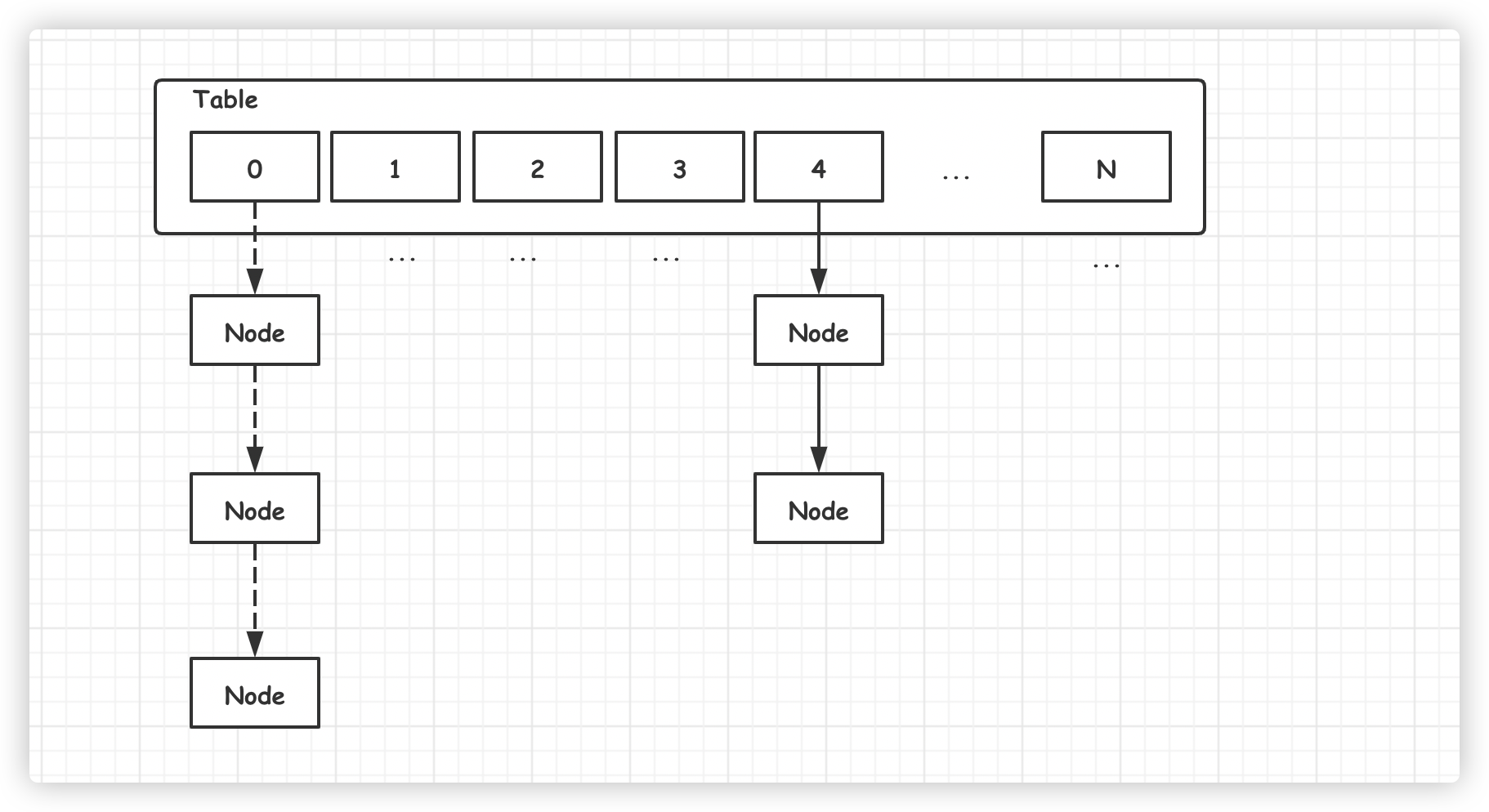
新添加的元素通过取模的方式,定位 `Table` 数组位置,然后将元素加入链表头部,这样下次提取时就可以快速被访问到。
访问数据时,也是通过取模的方式,定位数组中的位置,然后再遍历链表,依次比较,获取相应的元素。
如果 `HasMap` 中元素过多时,可能导致某个位置上链表很长。原本 **O(1)** 查找性能,可能就退化成 **O(N)**,严重降低查找效率。
为了避免这种情况,当 `HasMap` 元素数量满足以下条件时,将会自动扩容,重新分配元素。
```java
// size:HashMap 中实际元素数量
//capacity:HashMap 容量,即 Table 数组长度,默认为:16
//loadFactor:负载因子,默认为:0.75
size>=capacity*loadFactor
```
`HasMap` 将会把容量扩充为原来的两倍,然后将原数组元素迁移至新数组。
```java
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry e : table) {
while(null != e) {
Entry next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
// 以下代码导致死链的产生
e.next = newTable[i];
// 插入到链表头结点,
newTable[i] = e;
e = next;
}
}
}
```
旧数组元素迁移到新数组时,依旧采用『**头插入法**』,这样将会导致新链表元素的逆序排序。
多线程并发扩容的情况下,链表可能形成**死链(环形链表)**。一旦有任何查找元素的动作,线程将会陷入死循环,从而引发 **CPU** 使用率飙升。
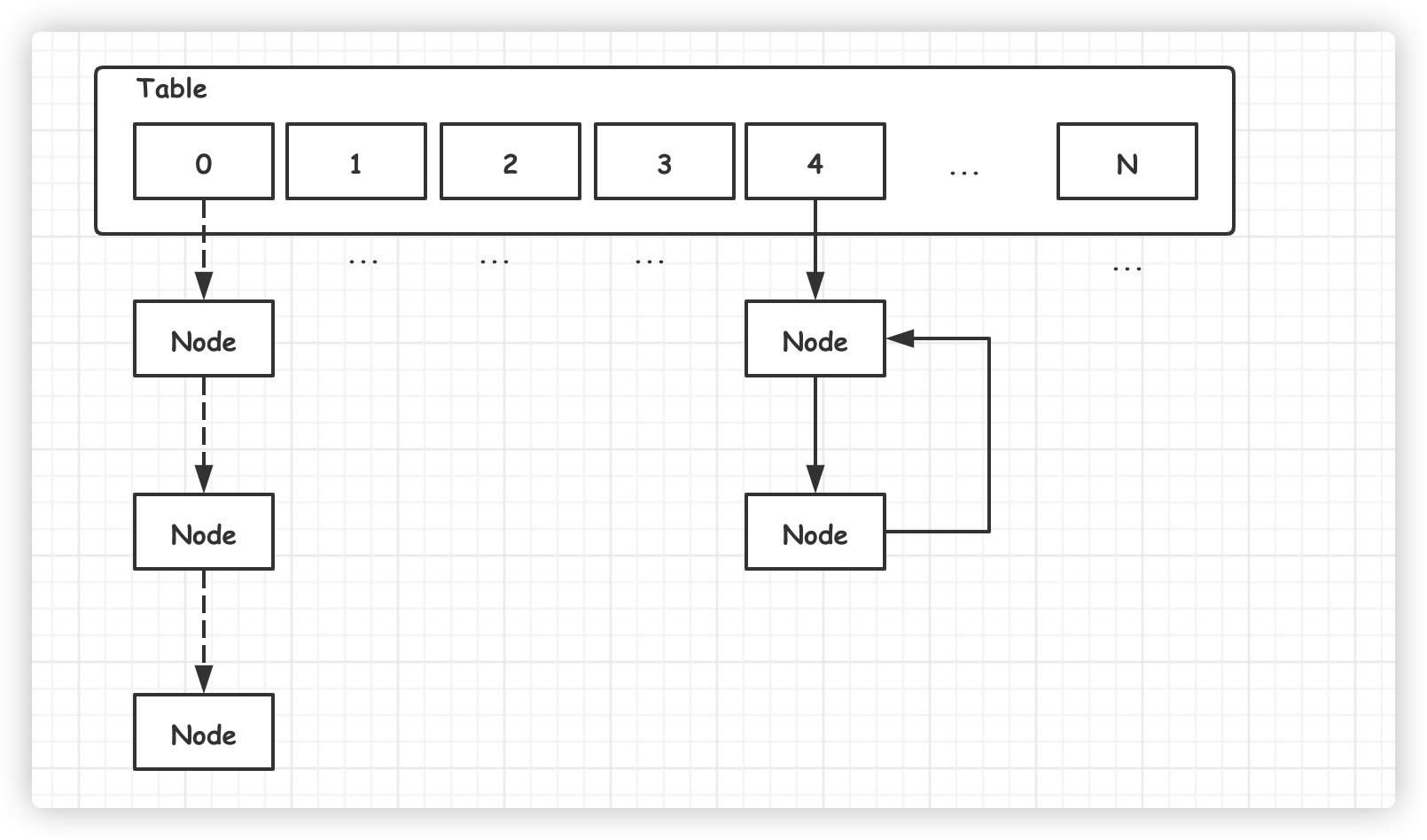
网上详细分析死链形成的过程比较多,这里就不再详细解释,大家感兴趣可以阅读以下**@陈皓**的文章。
文章地址:**https://coolshell.cn/articles/9606.html**
### JDK1.8 改进方案
JDK1.8 `HashMap` 底层结构进行彻底重构,使用数组加链表/红黑树方式这种组合结构。
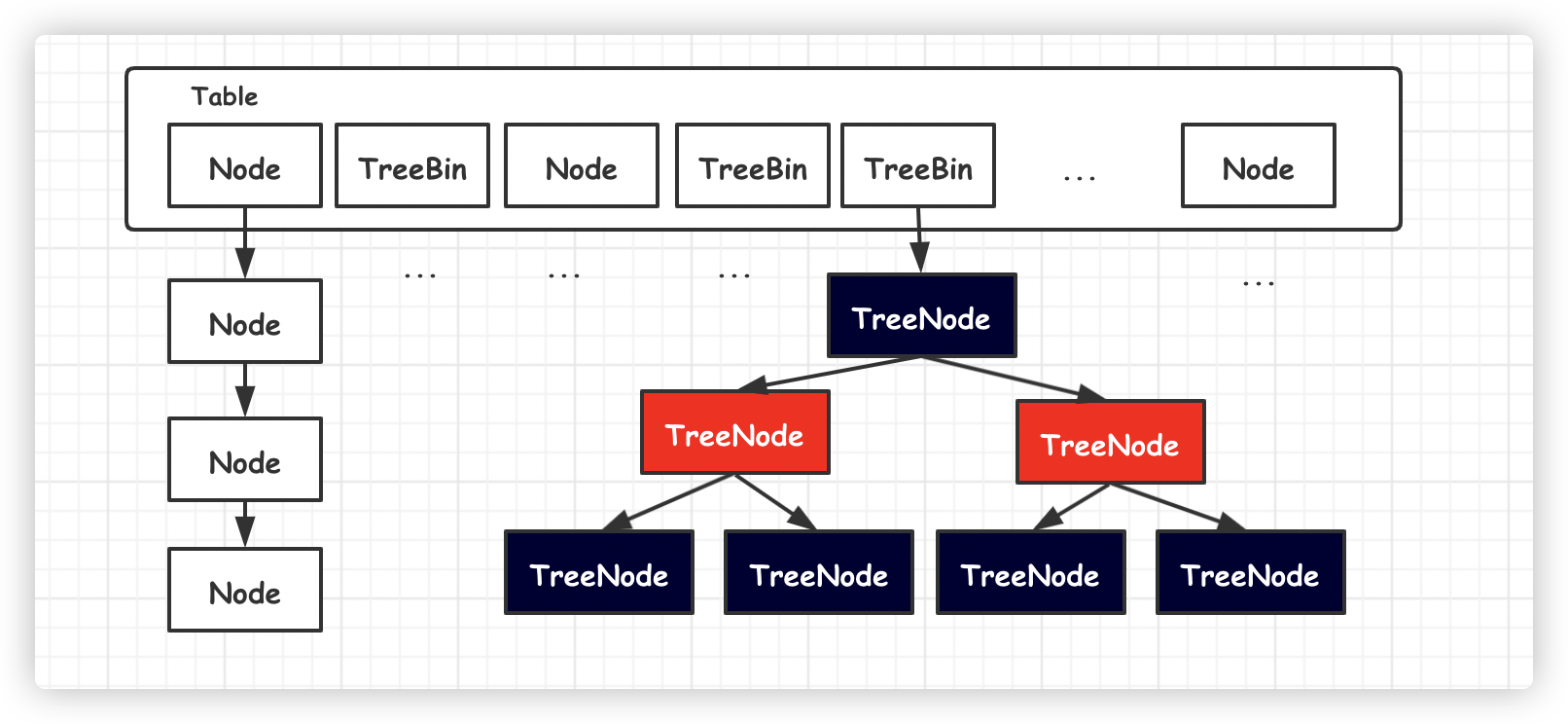
新元素依旧通过取模方式获取 `Table` 数组位置,然后再将元素加入链表**尾部**。一旦链表元素数量超过 8 之后,自动转为**红黑树**,进一步提高了查找效率。
> 面试题:为什么这里使用红黑树?而不是其他二叉树呢?
由于 JDK1.8 链表采用『**尾插入**』法,从而避免并发扩容情况下链表形成死链的可能。
那么 `HashMap` 在 JDK1.8 版本就是并发安全的吗?
其实并没有,多线程并发的情况,`HashMap` 可能导致丢失数据。
下面是一段 JDK1.8 测试代码:
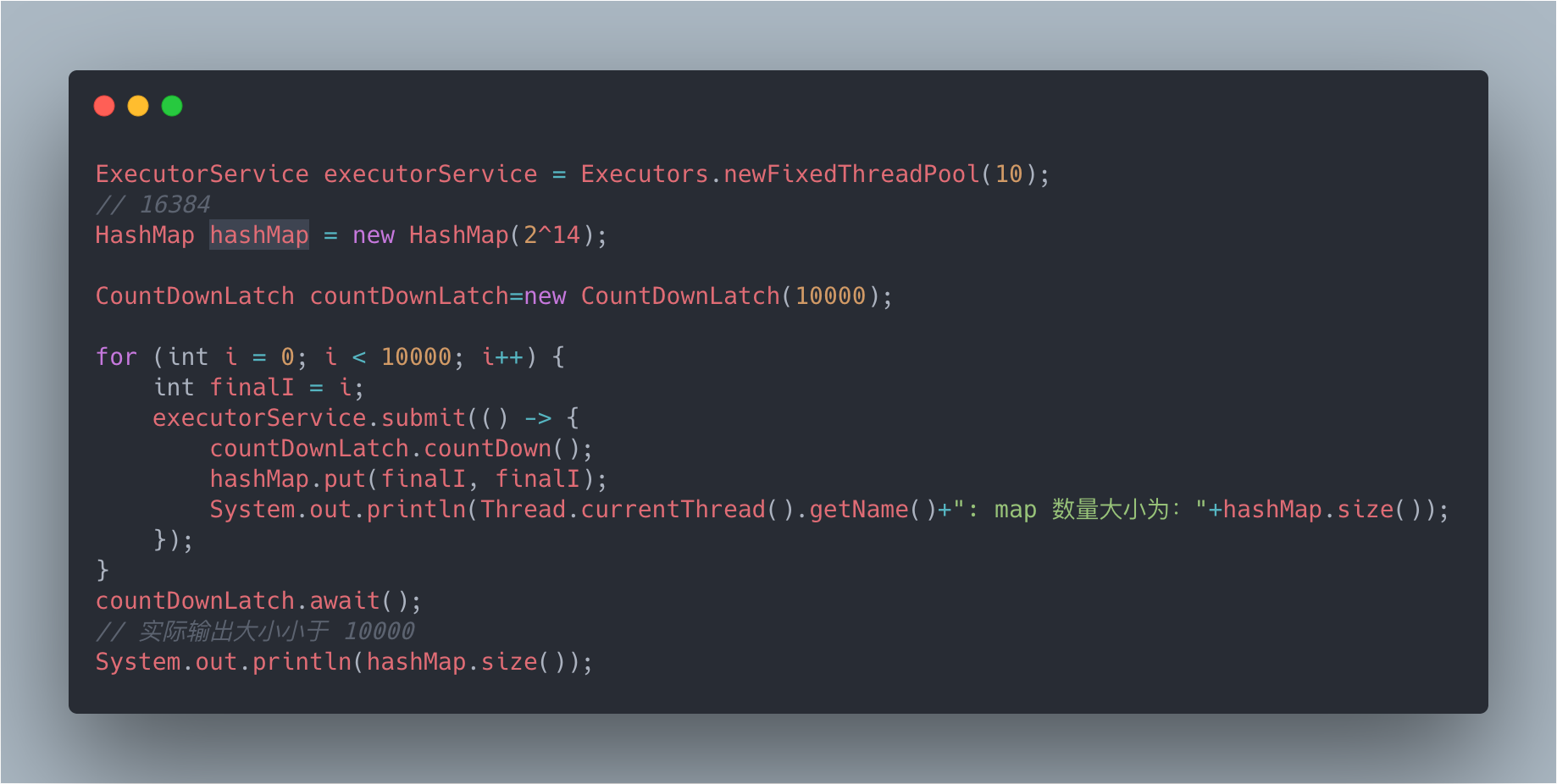
在我的电脑上输出如下,数据发生了丢失:
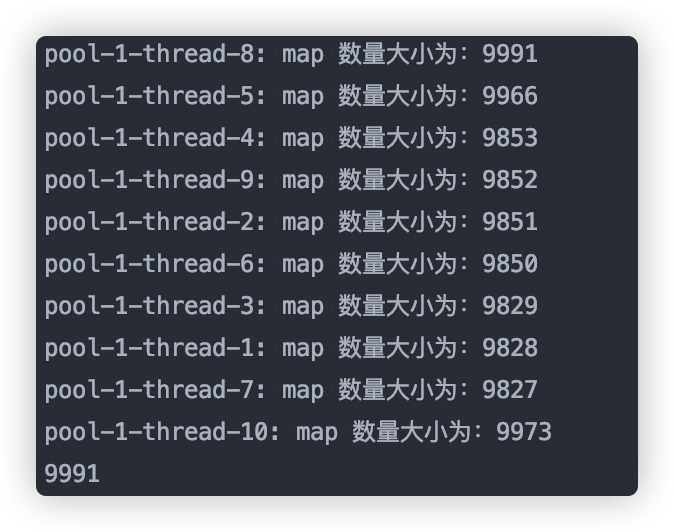
从源码出发,并发过程数据丢失的原因有以下几点:
**并发赋值时被覆盖**
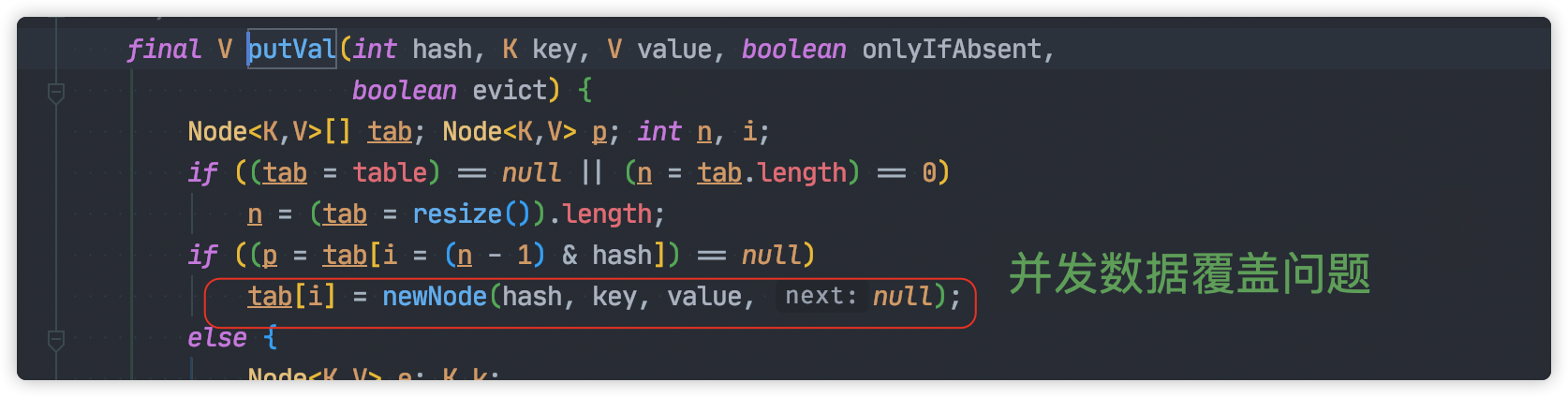
并发的情况下,一个线程的赋值可能被另一个线程覆盖,这就导致对象的丢失。
**size 计算问题**

每次元素增加完成之后,`size` 将会加 1。这里采用 `++i`方法,天然的并发不安全。
> 对象丢失的问题原因可能还有很多,这里只是列举两个比较的明显的问题。
>
> 当然 JDK1.7 中也是存在数据丢失的问题,问题原因也比较相似。
一旦发生**死链**的问题,机器 **CPU** 飙升,通过系统监控,我们可以很容易发现。
但是数据丢失的问题就不容易被发现。因为数据丢失环节往往非常长,往往需要系统运行一段时间才可能出现,而且这种情况下又不会形成脏数据。只有出现一些诡异的情况,我们才可能去排查,而且这种问题排查起来也比较困难。
## SynchronizedMap
对于并发的情况,我们可以使用 JDK 提供 `SynchronizedMap` 保证安全。
`SynchronizedMap` 是一个内部类,只能通过以下方式创建实例。
```java
Map m = Collections.synchronizedMap(new HashMap(...));
```
`SynchronizedMap` 源码如下:
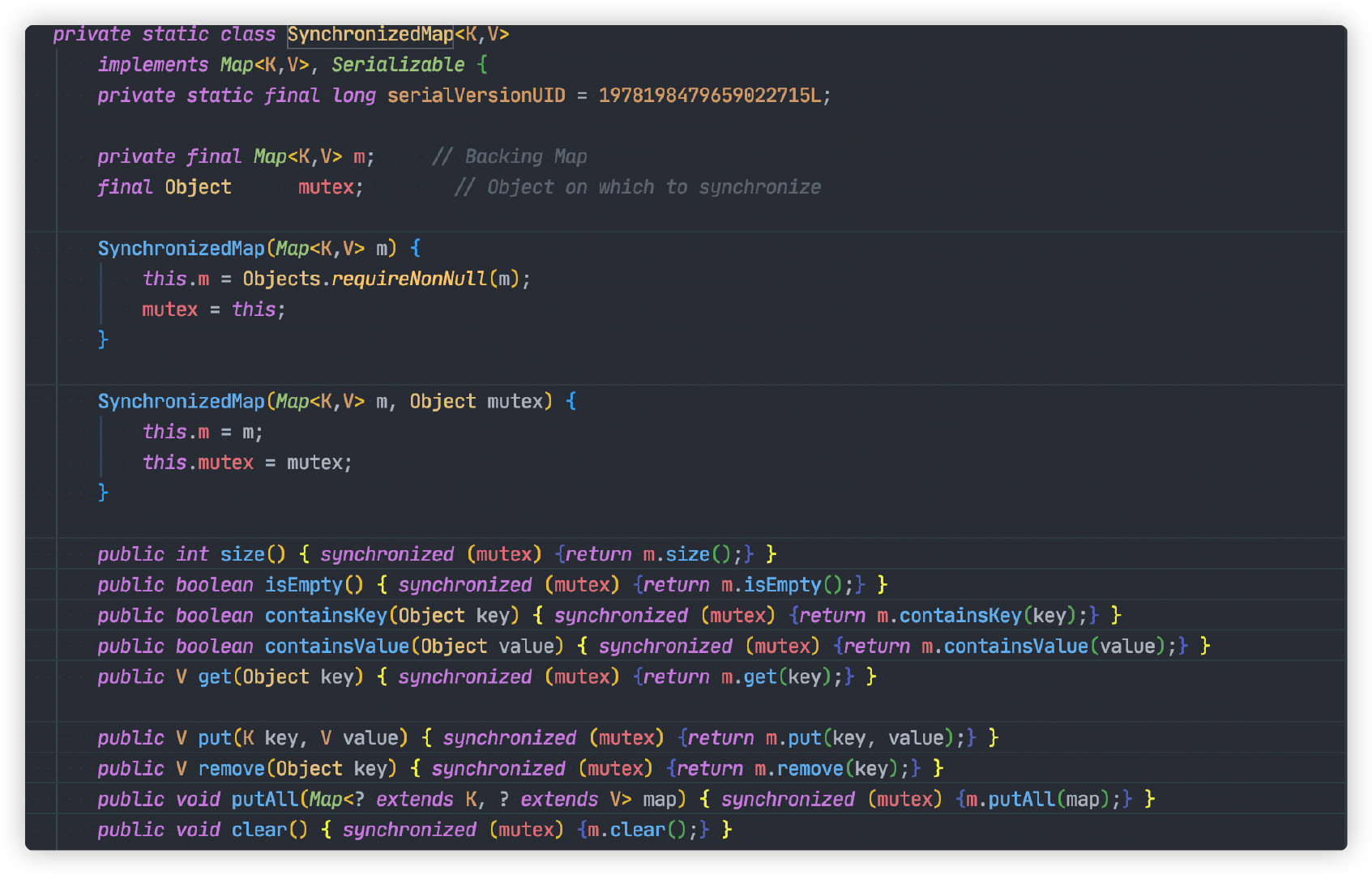
每个方法内将会使用 `synchronized` 关键字加锁,从而保证并发安全。
由于多线程共享同一把锁,导致同一时间只允许一个线程读写操作,其他线程必须等待,极大降低的性能。
并且大多数业务场景都是读多写少,多线程读操作本身并不冲突,`SynchronizedMap` 极大的限制读的性能。
所以多线程并发场景我们很少使用 `SynchronizedMap` 。
## ConcurrentHashMap
既然多线程共享一把锁,导致性能下降。那么设想一下我们是不是多搞几把锁,分流线程,减少锁冲突,提高并发度。
`ConcurrentHashMap` 正是使用这种方法,不但保证并发过程数据安全,又保证一定的效率。
### JDK1.7
JDK1.7 `ConcurrentHashMap` 数据结构如下所示:
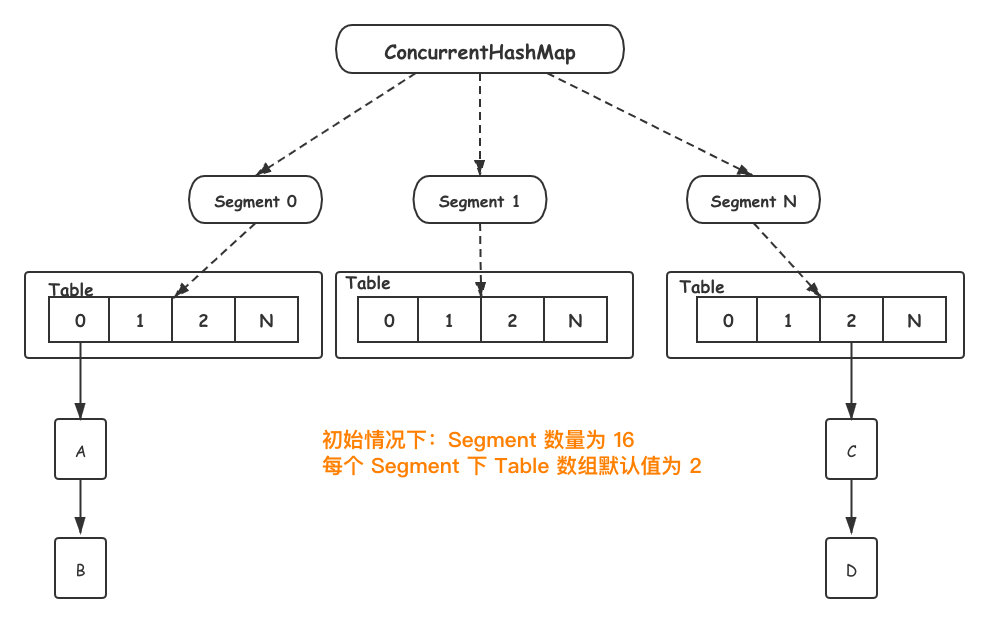
`Segament` 是一个`ConcurrentHashMap`内部类,底层结构与 `HashMap` 一致。另外`Segament` 继承自 `ReentrantLock`,类图如下:
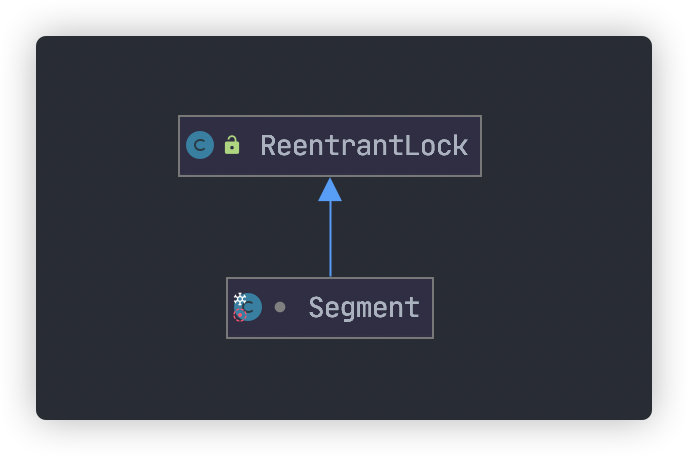
当新元素加入 `ConcurrentHashMap` 时,首先根据 key hash 值找到相应的 `Segament`。接着直接对 `Segament` 上锁,若获取成功,后续操作步骤如同 `HashMap`。
由于锁的存在,`Segament` 内部操作都是并发安全,同时由于其他 `Segament` 未被占用,因此可以支持 **concurrencyLevel** 个线程安全的并发读写。
**size 统计问题**
虽然 `ConcurrentHashMap` 引入分段锁解决多线程并发的问题,但是同时引入新的复杂度,导致计算 `ConcurrentHashMap` 元素数量将会变得复杂。
由于 `ConcurrentHashMap` 元素实际分布在 `Segament` 中,为了统计实际数量,只能遍历 `Segament`数组求和。
为了数据的准确性,这个过程过我们需要锁住所有的 `Segament`,计算结束之后,再依次解锁。不过这样做,将会导致写操作被阻塞,一定程度降低 `ConcurrentHashMap`性能。
所以这里对 `ConcurrentHashMap#size` 统计方法进行一定的优化。
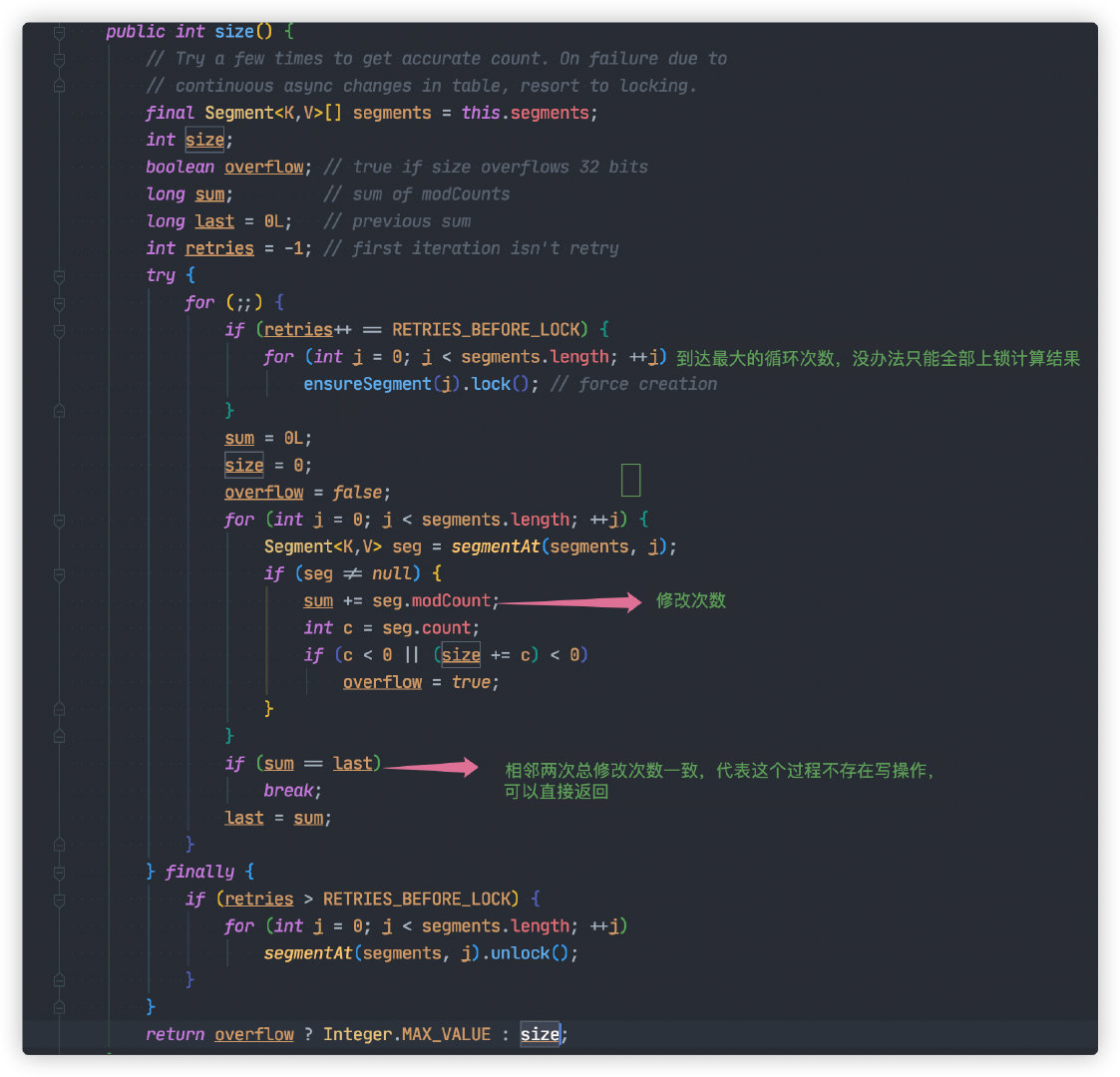
`Segment` 每次被修改(写入,删除),都会对 `modCount`(更新次数)加 1。只要相邻两次计算获取所有的 `Segment` `modCount` 总和一致,则代表两次计算过程并无写入或删除,可以直接返回统计数量。
如果三次计算结果都不一致,那没办法只能对所有 `Segment` 加锁,重新计算结果。
这里需要注意的是,这里求得 **size** 数量不能做到 100% 准确。这是因为最后依次对 `Segment` 解锁后,可能会有其他线程进入写入操作。这样就导致返回时的数量与实际数不一致。
不过这也能被接受,总不能因为为了统计元素停止所有元素的写入操作。
**性能问题**
想象一种极端情况的,所有写入都落在同一个 `Segment`中,这就导致`ConcurrentHashMap` 退化成 `SynchronizedMap`,共同抢一把锁。

### JDK1.8 改进方案
JDK1.8 之后,`ConcurrentHashMap` 取消了分段锁的设计,进一步减锁冲突的发生。另外也引入红黑树的结构,进一步提高查找效率。
数据结构如下所示:
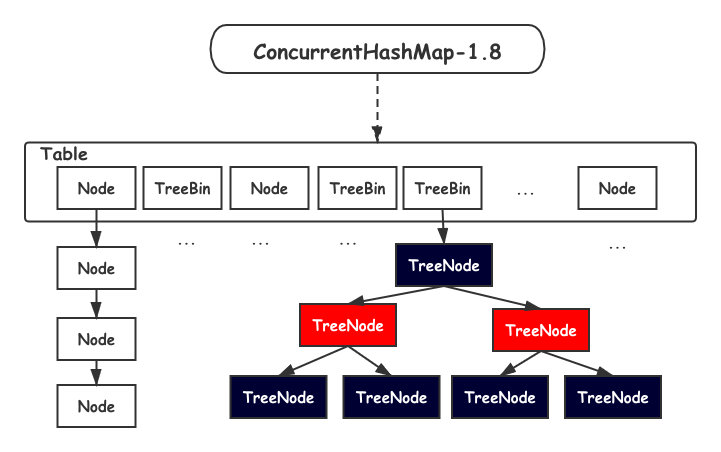
`Table` 数组的中每一个 `Node` 我们都可以看做一把锁,这就避免了 `Segament` 退化问题。
另外一旦 `ConcurrentHashMap` 扩容, `Table` 数组元素变多,锁的数量也会变多,并发度也会提高。
写入元素源码比较复杂,这里可以参考下面流程图。
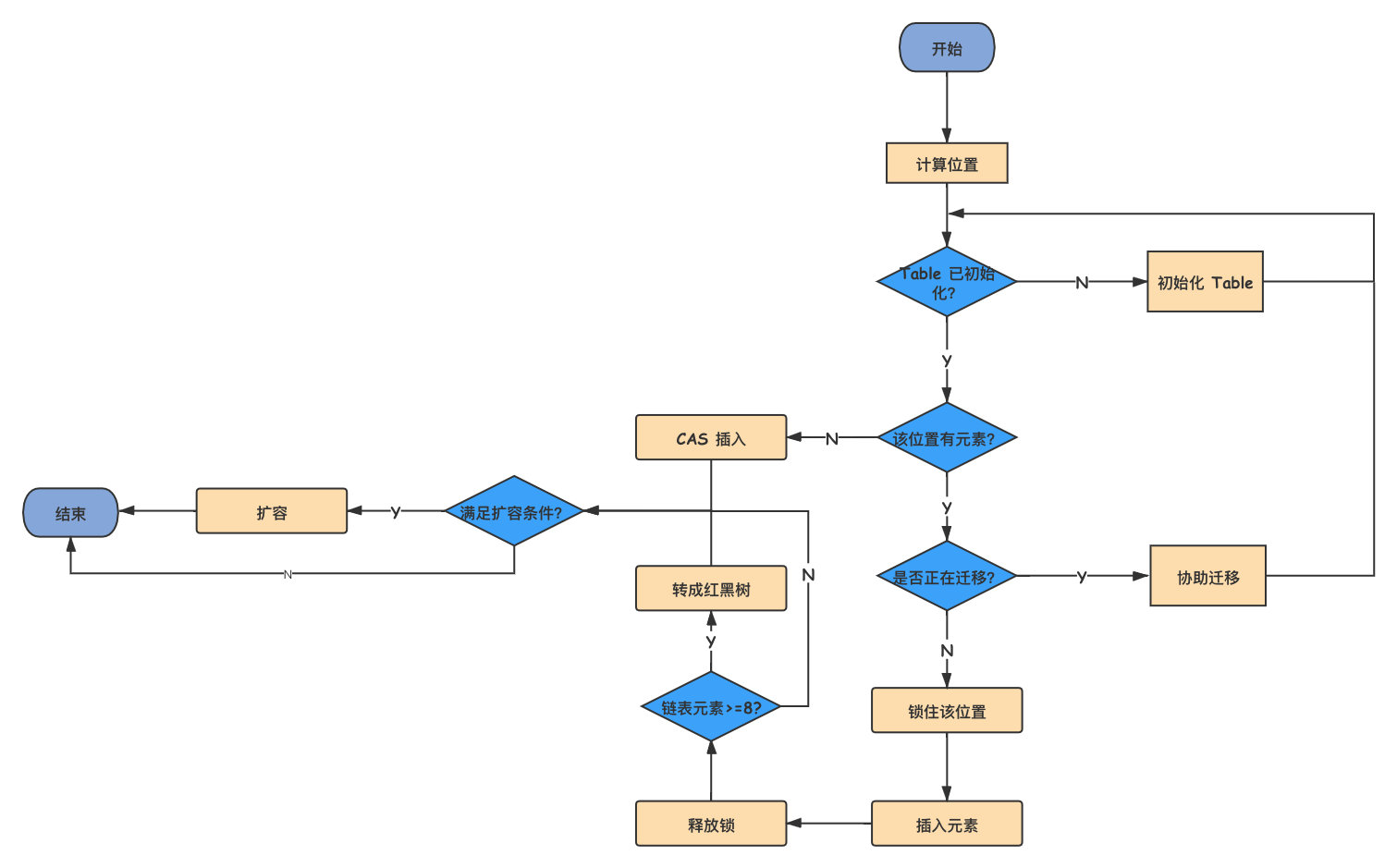
总的来说,JDK1.8 使用 CAS 方法加 `synchronized` 方式,保证并发安全。
**size 方法优化**
JDK1.8 `ConcurrentHashMap#size` 统计方法还是比较简单的:
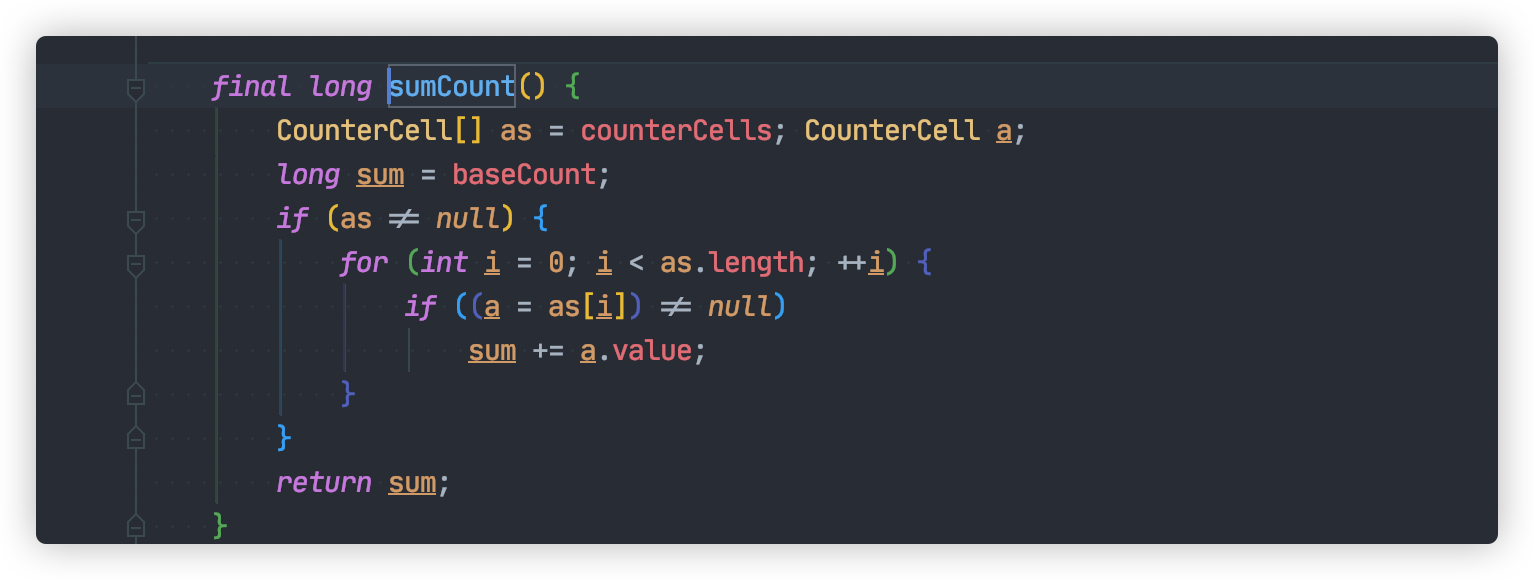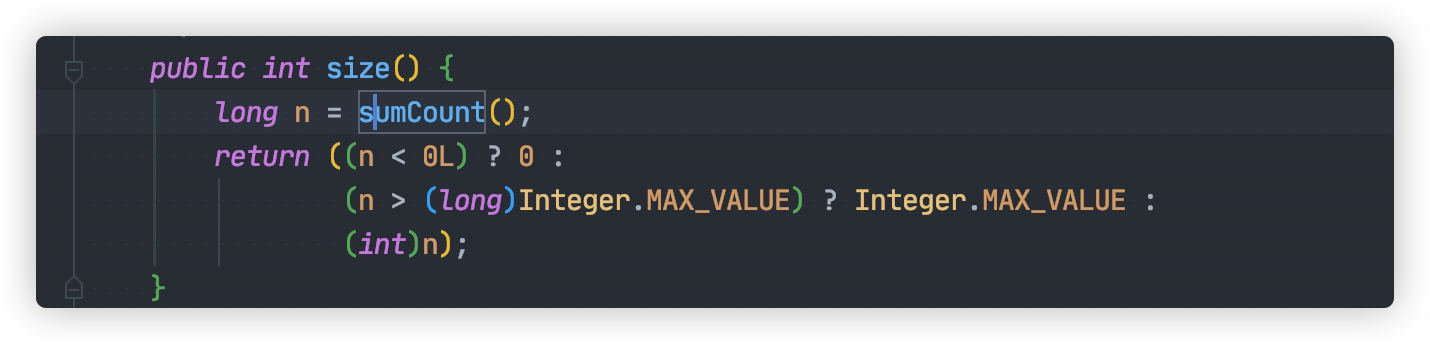
这个方法我们需要知道两个重要变量:
- `baseCount`
- `CounterCell[] counterCells`
`baseCount` 记录元素数量的,每次元素元素变更之后,将会使用 `CAS`方式更新该值。
如果多个线程并发增加新元素,`baseCount` 更新冲突,将会启用 `CounterCell`,通过使用 `CAS` 方式将总数更新到 `counterCells` 数组对应的位置,减少竞争。
如果 `CAS` 更新 `counterCells` 数组某个位置出现多次失败,这表明多个线程在使用这个位置。此时将会通过扩容 `counterCells`方式,再次减少冲突。
通过上面的努力,统计元素总数就变得非常简单,只要计算 `baseCount` 与 `counterCells`总和,整个过程都不需要加锁。
仔细回味一下,`counterCells` 也是通过类似分段锁思想,减少多线程竞争。
## 分段锁实战应用
`ConcurrentHashMap` 通过使用分段锁的设计方式,降低锁的粒度,提高并发度。我们可以借鉴这种设计,解决某些**热点数据**更新问题。
举个例子,假如现在我们有一个支付系统,用户每次支付成功,商家的账户余额就会相应的增加。
当大促的时候,非常多用户同时支付,同一个商家账户余额会被并发更新。
数据库层面为了保证数据安全,每次更新时将会使用行锁。同时并发更新的情况,只有一个线程才能获取锁,更新数据,其他线程只能等待锁释放。这就很有可能导致其他线程余额更新操作耗时过长,甚至事务超时,余额更新失败的。
这就是一个典型的**热点数据**更新问题。
这个问题实际原因是因为多线程并发抢夺**行锁**导致,那如果有多把行锁,是不是就可以降低锁冲突了那?
没错,这里我们借鉴 `ConcurrentHashMap` 分段锁的设计,在商家的账户的下创建多个**影子账户**。
然后每次更新余额,随机选择某个**影子账户**进行相应的更新。
理论上**影子账户**可以创建无数个,这就代表我们可以无限提高并发的能力。
> 这里感谢**@why** 神提出影子账户的概念,大家感兴趣可以搜索关注,公众号: why技术

架构设计中引入新的方案,就代表会引入新的复杂度,我们一定要这些问题考虑清楚,综合权衡设计。
引入影子账户虽然解决热点数据的问题,但是商户总余额统计就变得很麻烦,我们必须统计所有子账户的余额。
另外实际的业务场景,商家余额不只是会增加,还有可能的进行相应的扣减。这就有可能产生商户总余额是足够的,但是选中的影子账户的余额却不足。
这怎么办?这留给大家思考了。不知道各位读者有没有碰到这种类似的问题,欢迎留言讨论。
大家感兴趣的话,后面的文章我们可以详细聊聊**热点账户**的解决方案。
## 总结
`HashMap` 在多线程并发的过程中存在死链与丢失数据的可能,不适合用于多线程并发使用的场景的,我们可以在方法的局部变量中使用。
`SynchronizedMap` 虽然线程安全,但是由于锁粒度太大,导致性能太低,所以也不太适合在多线程使用。
`ConcurrentHashMap` 由于使用多把锁,充分降低多线程并发竞争的概率,提高了并发度,非常适合在多线程中使用。
最后小黑哥再提一点,不要一提到多线程环境,就直接使用 `ConcurrentHashMap`。如果仅仅使用 `Map` 当做全局变量,而这个变量初始加载之后,从此数据不再变动的场景下。建议使用不变集合类 `Collections#unmodifiableMap`,或者使用 Guava 的 `ImmutableMap`。不变集合的好处在于,可以有效防止其他线程偷偷修改,从而引发一些业务问题。
`ConcurrentHashMap` 分段锁的经典思想,我们可以应用在**热点更新**的场景,提高更新效率。
不过一定要记得,当我们引入新方案解决问题时,必定会引入新的复杂度,导致其他问题。这个过程一定要先将这些问题想清楚,然后这中间做一定权衡。
## 参考资料
1. 码出高效 Java 开发手册
2. http://www.jasongj.com/java/concurrenthashmap/
## 最后说一句(求关注)
看到这里,点个关注呀,点个赞呗。别下次一定啊,大哥。写文章很辛苦的,需要来点正反馈。
才疏学浅,难免会有纰漏,如果你发现了错误的地方,还请你留言给我指出来,我对其加以修改。
感谢您的阅读,我坚持原创,十分欢迎并感谢您的关注

> 欢迎关注我的公众号:程序通事,获得日常干货推送。如果您对我的专题内容感兴趣,也可以关注我的博客:[studyidea.cn](https://studyidea.cn)
加载全部内容