WEB应用之http协议和httpd闲聊
Linux-1874 人气:3什么是web?在日常生活中我们常常听到web这个词,它到底是什么呢?今天我们来聊一聊web应用http协议;相信生活在如今互联网时代的我们,http这个协议应该对我们不是很陌生吧!比如双十一双十二我们去某宝、某东去抢购商品,它背后就是用一堆web服务器通过http协议或https协议在给我们提供服务;简单点说web服务就是一个C/S架构,服务端提供服务,客户端通过http协议或https协议进行访问,拿到服务端对应的资源,这就是web服务;所谓C/S架构就是客户端和服务端架构;对于服务端一侧在iso七层网络模型中应用层协议存在的意义是实现某一具体应用,通常情况下他们都会向内核空间注册一众所周知的服务端口,并监听在某一地址,或多个地址上,对外提供服务;这也通常是C/S架构的软件服务工作的特点;而http协议就是工作在应用层的80端口对外提供服务;对于客户端一侧就没有监听这一说了,通常情况下客户端也是工作在应用层或者我们可以这样理解,它实际不是工作在应用层;我们知道网络资源对于计算机来说只有内核的特权指令才能够操作,而对于普通用户来说,内核的功能我们必须在用户空间提供一应用程序,通过应用程序对内核提供的API进行系统调用,从而实现操作网络资源的能力;实现客户端的软件有很多,图形界面下常见的浏览器chrome呀,firefox呀,ie等等,这些程序都是web服务的客户端,当然除此之外,像在Linux字符界面的web客户端有,wget、curl、elinks等等;这些客户端在用户空间访问服务端时,会随机向内核注册一端口,然后把自己的请求信息通过封装应用层首部,传输层,网络层,数据链路层,物理层,最后通过网卡发送给服务端,服务端收到客户端的请求会对客户端封装的报文,层层拆除,从而拿到客户端的请求,拿到客户端的请求后,然后封装响应报文,封装响应报文的过程类似客户端封装请求报文,先封装应用层首部,然后传输层,网络层,数据链路层,物理层,然后发送给客户端;客户端拿到报文后,层层拆封装,最终拿到服务端的响应;这就是http协议的一次事务过程,无外乎就是客户端请求,服务端响应;
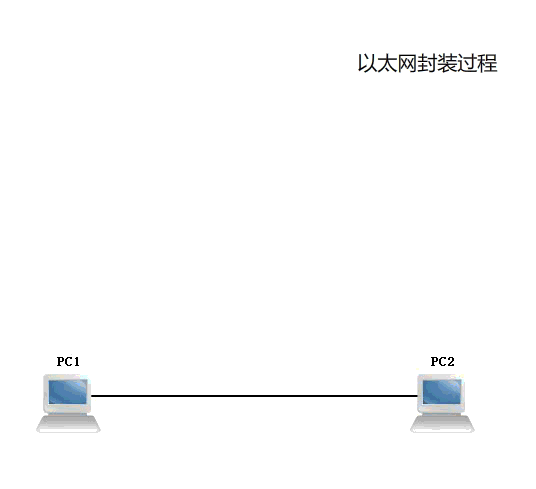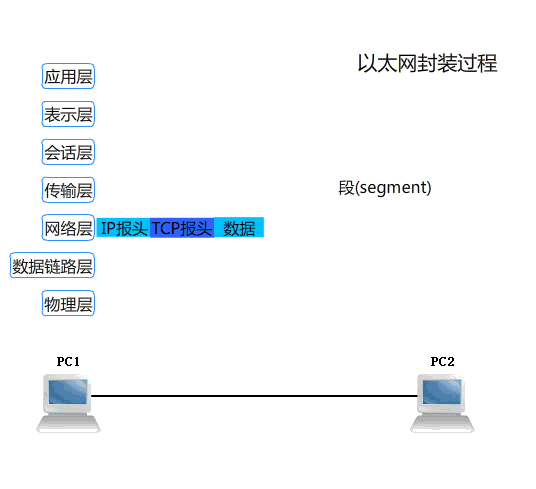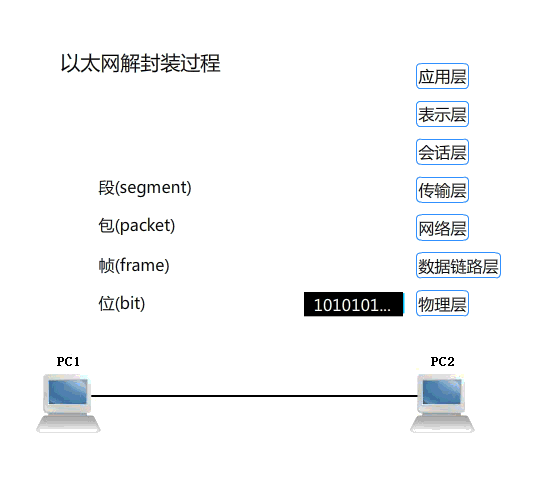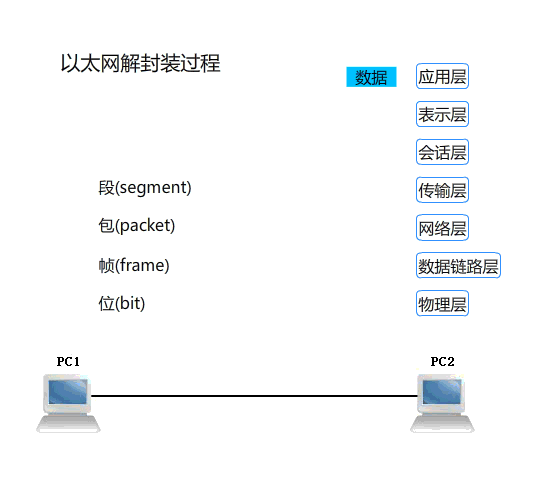
提示:以上是以太网的封装报文和解封装报文的一个过程,http协议是应用层协议,通常情况下应用层就是上面三层;应用层是工作在用户空间的,而下面四层是工作在内核空间,通常我们把下面四层称为通信子网层;这也是我们之前的iptables里面经常提到的内核空间功能必须要由用户空间程序对内核发起系统调用才能够操作内核空间功能,所以像iptables、ipvsadm这类工具我们不称他们叫服务,而是工具的原因;同理像web客户端我们通常也只是叫它是工具,而不叫服务;通常所谓服务就是需要向内核注册一端口,然后监听在某一地址上,我们把这种工作在用户空间(或者内核空间的功能)的程序叫服务,简单点讲服务需要被监听,之所以要被监听是因为通信的需要;
IPC(Inter-Process Communication,进程间通信),所谓进程间通信就是两个进程互相交换数据;进程间通信的方式有很多,比如内存共享、内存映射、BSD socket等等;其中最为常见的一种BSD socket,它允许位于不同主机(当然同一主机也是可以的,只不过同一主机用这种socket机制显得不那么高效)上的进程之间进行通信;什么叫socket?相信懂点网络编程的人都听过这个词吧! 所谓socket就是IP加端口,对于套接字可以分TCP套接字、udp套接字、raw套接字,它们通常情况下是通过socket API(封装了内核中的socket通信相关的系统调用)来创建不同的套接字类型;如SOCK_STREAM就是表示TCP套接字,SOCK_DGRAM就表示UDP套接字,SOCK_RAW就表示raw套接字;根据套接字所使用的地址格式,我们又可以分为IPV4的套接字、ipv6套接字和unix_sock(同一主机上的不同进程间基于socket套接字通信使用的一种地址);例如AF_INET就表示ipv4格式的套接字,AF_INET6就表示ipv6套接字格式,AF_UNIX就表示unix_sock套接字格式;其中前两者用于网络通信,通常是位于不同主机间进程通信,而后者unix_sock用于同一主机的两个进程通信较为常见;后者就是我们常见的sock文件,例如mysql客户端连接本地服务端就是用的这种机制;
了解上面的底层通信原理,我们再来聊聊今天的主题http吧
http是hyper text transfer protocol的简写,它是应用层协议,默认工作在tcp协议的80端口,属于文本协议;在http协议0.9版本中,它就只能用于传输html文本,也是在互联网上使用的最原始的版本,功能相当简陋;1.0版本引进了cache机制,MIME机制和更多的method,使得http协议一下子被广泛使用,MIME是多用途互联网邮件扩展类型,它的主要作用是让一些非文本格式的附件能够通过互联网互相传输,并且在接收方接收后能够将其还原成原有格式的附件的机制,什么意思呢?它能够让一些非文本格式的附件在通过互联网传输后还原成原来格式的附件的一种机制;这使得http协议可以传输非文本格式的数据,比如图片、视频、音乐等;所谓method就是客户端请求服务端资源时数据传输请求的方法,在0.9版本http协议只支持GET这一种方法,在1.0版本中http协议支持了更多的请求方法,如GET、PUT、POST、DELETE、HEAD等等;在这之后有1.1版本,它主要是在1.0版本上增强了缓存功能;随后就是2.0,2.0主要是在1.1版本上做了很多优化,使得原有1.1本版的诸多性能问题得以解决,现在主流使用的http协议版本是1.1和2.0版本;
http工作模式
http的工作模式非常简单,在上面我们也提到过,不外乎就是客户端请求,服务端响应;其中我们把请求报文叫做http request响应报文叫做http response;对于客户端的一次请求和服务端的一次响应响应我们把这一过程叫做http协议的一次事务;
web资源:web resource
web资源分静态资源和动态资源,所谓静态资源就是无需服务端做额外的处理的资源,我们叫静态资源,什么意思呢?客户端请求的资源,在服务端是什么样通过http协议传输后到客户端上就是什么样,我们就把这种不需要服务端额外处理的资源叫静态资源,常见的静态资源有.jpg, .png, .gif, .html, txt, .js, .css, .mp3, .avi等;所谓动态资源就与之相反,客户端请求的资源通常是需要被程序执行或处理后,然后把执行结果或处理后的结果发送给客户端,我们把这种需要服务端通过某一执行程序作出处理的资源叫动态资源;常见的有.php.jsp.asp等;这里还需要注意一点的是,我们平常看到的网页资源往往不是单独的一个资源,它可能是有很多资源组成,有动态的,也有静态的,每个资源都需要单独请求,如下所示;
提示:可以看到我们访问一个页面的背后其实是有很多资源组成;
资源的标识机制:URL
所谓资源标识符就是用于描述服务器某特定资源的位置;简单点就是用于告诉服务端客户端要访问的资源;通常情况下URL由协议加“://”加服务器地址(可以是域名,或主机名)[:port](若服务端工作在非标准端口,我们还需要指定端口)然后加资源路径或资源名称(这里的资源路径指的是web服务的根路径开始,而非文件系统的根路径)例如http://www.test.com/index.html这就是一个URL,客户端介入这样一个URL对应的服务端就知道客户端请求的资源是www.test.com这台主机上的index.html文件,服务端就会把对应目录下的文件响应给客户端;对于服务端它怎么去自己的文件系统上找index.html这个文件,通常情况下是通过我们对服务端定义的documentroot来决定的,在nginx中我们可以通过root指令来指定虚拟主机的根目录对应文件系统路径的映射;
一次完整的http请求处理过程通常是有以下几步来完成:
(1) 建立或处理连接:接收请求或拒绝请求;
(2) 接收请求:接收来自于网络上的主机请求报文中对某特定资源的一次请求的过程;
http的响应模型,http的响应模型主要有单进程I/O模型、多进程、复用I/O模型和服用多进程模型,其中单进程I/O模型就是启动一个进程处理用户的请求,这意味着,一次只能处理一个请求,多个请求被串行响应;多进程I/O模型表示由父进程并行启动多个子进程,每个子进程进行相应一个用户请求;复用单进程I/O模型有两个模式,多线程模式和事件驱动模式,前者表示一个进程生成N个线程,一个线程处理一个请求;而事件驱动模式中一个进程直接处理N个请求,没有线程的说法;复用多进程I/O模型中,启动多个进程,每个进程生成n个线程,每个线程处理一个请求,响应的请求数量是进程数量乘每个进程生成的线程数;
(3) 处理请求:服务器对请求报文进行解析,并获取请求的资源及请求方法等相关信息,根据方法,资源,首部和可选的主体部分对请求进行处理
元数据:请求报文首部
<method> <URL> <VERSION>
HEADERS 格式 name:value
<request body>
……
示例:
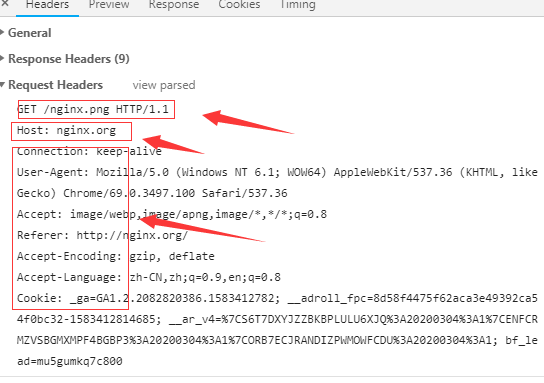
(4) 访问资源:获取请求报文中请求的资源;服务器获取请求报文中请求的资源web服务器,即存放了web资源的服务器,负责向请求者提供对方请求的静态资源,或动态运行后生成的资源;资源放置于本地文件系统特定的路径:DocRoot
示例:如果我们将web资源根目录映射成文件系统上的/var/www/html,即www.test.com/ ---->> /var/www/html,用户访问www.test.com/index.html,就相当于访问文件系统上的/var/www/html/index.html,通常情况下web服务器资源路径映射方式有4种,第一种是通过定义docroot来指定,第二种是alias别名来指定,第三种是虚拟主机的docroot第四种是用户家目录的docroot
(5) 构建响应报文:一旦Web服务器识别除了资源,就执行请求方法中描述的动作,并返回响应报文。响应报文中 包含有响应状态码、响应首部,如果生成了响应主体的话,还包括响应主体;
响应实体:如果事务处理产生了响应主体,就将内容放在响应报文中回送过去。响应报文中通常包括:描述了响应主体MIME类型的Content-Type首部,描述了响应主体长度的Content-LengthContent-Type首部和实际报文的主体内容
示例:

(6) 发送响应报文:Web服务器通过连接发送数据时也会面临与接收数据一样的问题。服务器可能有很多条到各个客户端的连接,有些是空闲的,有些在向服务器发送数据,还有一些在向客户端回送响应数据。服务器要记录连接的状态,还要特别注意对持久连接的处理。对非持久连接而言,服务器应该在发送了整条报文之后,关闭自己这一端的连接。对持久连接来说,连接可能仍保持打开状态,在这种情况下,服务器要正确地计算Content-Length首部,不然客户端就无法知道响应什么时候结束了;
(7) 记录日志:最后,当事务结束时,Web服务器会在日志文件中添加一个条目,来描述已执行的事务;
HTTP服务器应用
http服务器程序有httpd、nginx、lighttpd等nginx相关使用和说明可参考本人前面的博客https://www.cnblogs.com/qiuhom-1874/category/1646010.html;接下来我们着重来说说httpd;
httpd是20世纪90年代初,国家超级计算机应用中心NCSA开发,1995年开源社区发布apache(a patchy server)它是一款高度模块化,支持动态加卸载模块,支持多路处理模块,所谓多路处理模块就是httpd的三种响应模型;
第一种是prefork多进程模型,每个进程响应一个请求,一个主进程,主进程程负责生成子进程以及回收子进程、套接字的创建和接收请求并将其派发给某个子进程处理;n个子进程(一个子进程中生成一个线程处理一个请求),子进程主要用于处理请求;工作模型:会预先生成几个空闲进程,随时等待用于响应用户请求;最大空闲和最小空闲;
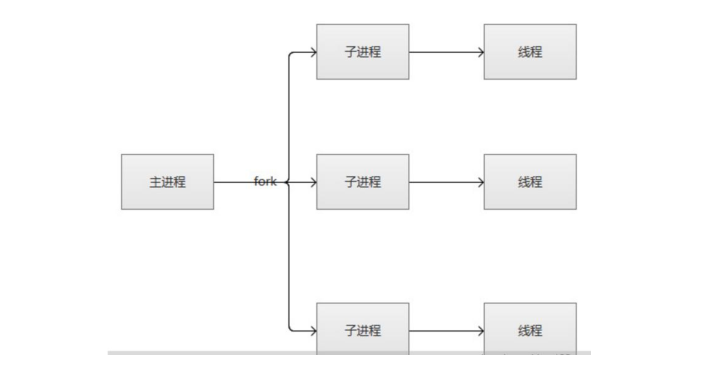
第二种是worker多进程多线程模型,在这种模型中每个线程处理一个用户请求;同样的它也会由一个主进程负责生成子进程,套接字的创建和接收请求并将请求派发给某个子进程进行处理;n个子进程,和上面的profork不同的是,这里的子进程主要负责生成多个线程,而每个线程处理一个请求;这样一来在这种模型中并发响应数量就是n个子进程乘每个子进程生成的M个线程;
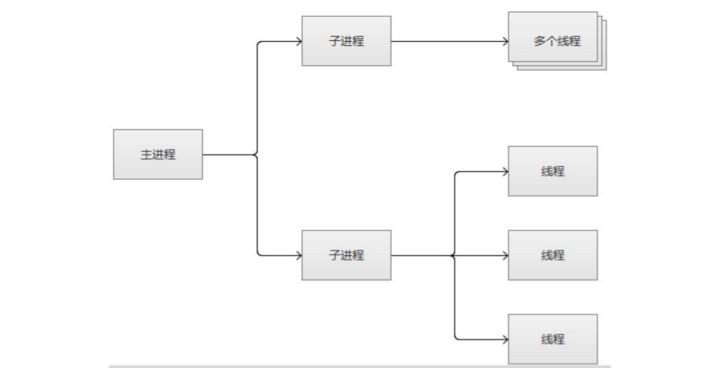
第三种是event:事件驱动模型,多进程模型,一个主进程生成m个子进程,每个进程直接响应n个请求,并发响应请求:m*n,有专门的线程来管理这些keep-alive类型的线程,当有真实请求时,将请求传递给服务线程,执行完毕后,又允许释放。这样增强了高并发场景下的请求处理能力

以上就是httpd的一些简单介绍,在后续的文章中我会持续更新httpd的其他用法和配置指令的说明,有感兴趣的朋友可以关注关注,共同探讨;
加载全部内容