观察法 -- 如何仅通过观察事物的运行方式来把握事件发生的原因
郑瀚Andrew.Hann 人气:21. 观察法综述
0x1:从统计数据中存在的表面虚假规律问题说起
某一天下班,你在地铁看到一则广告,广告上这样写道:
如果你高中毕业了,找到了一份工作,并且婚后才生的孩子,那么你98%不会穷困潦倒。
这则广告的目的是呼吁十几岁的女孩不要早孕,但我们并不清楚该如何理解这个统计数据。从表面上看,这句话的意思似乎是,如果一个年轻女孩能够按照广告上说的那样做,那么她98%不会穷困潦倒。
但是,事实真的是这样吗?而且这句话是说她现在不会处于穷困潦倒的境地,还是永远不会处于穷困潦倒的境地呢?
我们知道,统计规律只在大数定律下起作用,但是具体到一个小样本集,或者说具体到一个个具体的个体来说,这种统计规律就不一定成立了。用概率统计的术语来解释就是,在大数条件下得到的统计规律具有相对小的统计方差(规律显著性更高),但是在小数情况下,统计规律的统计方法会变大(规律显著性更低)。
当然,这个例子中存在的推理错误还不止于此,这个统计结果完全建立在观察到的数据的基础之上,它可能还存在共同原因、虚假因果性、选择偏差等问题。我们这里简单的阐述一下这些问题,详细的讨论会放在文章的后半部分。
1、选择偏差问题
没有任何(个人或社会的)政策能力强制年轻女孩怀孕或者不怀孕,也没有任何政策能迫使她们穷困或者不穷困。这就意味着这个数据只统计了我们观察到的一部分人口中的一个特征:在我们观察到的高中毕业、找到工作并且婚后才生孩子的人口中,有98%的人并未穷困潦倒。但如果具体到某一个人,她高中毕业,找到了一份工作并且婚后才生的孩子,那么她穷困潦倒的概率可能和统计数据并不一样。这一点类似于我们之前讨论的关于SIDS的案例。
2、共同原因问题
有些人没有完成学业的原因可能也正是导致他们贫困的原因,并且这些原因是他们不可控的,
- 也许他们不得不照看家里的老人
- 也许他们缺少生活的保障,比如医疗保险或家人的支持
- 这就意味着他们可能无法只是简单地去寻找一份工作,而且不得不去解决其他问题,比如为家里另找一个护工
而且,如果这些其他因素(比如高额的医疗费用)才是最终导致贫困的原因,那么即便满足了上述三个标准(高中毕业、找工作、不早孕),他们陷入贫困境地的风险也不会改变。
如果未完成学业、找不到工作和婚前生子只是那个导致人们陷入贫困境地的因素所带来的影响(即共同原因下的相关因素),那么针对这些问题采取干预措施就像在处理事情的结果而不是起因。
这对公共政策的制定有着巨大的影响。如果我们只致力于提升人们受教育的机会和就业机会,却不知道是什么因素导致人们无法获得这个机会,也不知道这两者本身是否就是导致贫困的原因,那么我们就更难制定有效的政策干预措施来提高人民的生活水平了。
3、虚假因果性问题
我们在上一篇文章中讨论过,因果关系并不是相关性的唯一解释。
如果我们能够强迫一些人读完高中(或者不读完),然后将他们随机分配到这些不同的实验组中(随机双盲、控制变量),就有可能将这一行为对未来经济形势的影响分离出来。
但实际情况是,我们所观察到的数据往往是我们所能获得的全部信息。
如果为了考察年轻女孩怀孕是否是贫穷导致的结果或引起贫穷的原因而去做一些实验,那么这种行为是不道德的。这和研究吸烟是否会导致肺癌的情况是类似的。
0x2:数据观察法
我们本文要讨论的话题是,当我们只能观察正在发生的情况时,如何去发现事物的运行方式。即使存在上一章节所说的种种问题,但我们依然是有办法从观察数据中科学地得到一些规律的,并用它来指导我们的生产和生活。
2. 基于规律性原理进行因果推理
0x1:穆勒五法
1、案例背景说明
假设一群计算机科学家参加了一个编程马拉松,这些科学家每天都忙到凌晨,营养均衡和饮食健康对他们来说就是天方夜谭。所以很多人在熬夜时都是依靠浓咖啡、比萨饼和功能性饮料来补充能量的。不幸的是,在第二天的颁奖典礼上,他们中的很多人都生病了或者缺席了。
现在问题来了,我们才能确定是哪个或哪些因素导致他们生病的呢?
2、John Stuart Mill 的穆勒五法
John Stuart Mill 在19世纪提出了穆勒五法,主要用于研究一类典型问题:有些团体中出现了某种结果,而另一些团体中没有出现某种结果,针对这种情况,试图找出这些团体中的共同点和不同点。
1)契合法 - 寻找必要条件
假设我们收集到的观察数据如下:

契合法顾名思义,它考察的是在所有出现某种结果的案例之间有什么共同点。
在上面的表格中,在所有头疼的案例中,唯一的共同点就是人们都喝了功能性饮料,那么这就在一定程度上证明了功能性饮料可能会导致头疼,注意!这里只能说是可能,因为出现了一个反例(Betty也喝了功能性饮料但没头疼)。
契合是指某个原因是导致某个结果的必要条件,除非出现这个原因,否则不会出现这个结果。然而,这并不意味着这个原因每次都会导致这种结果,即它不一定是充分条件。
在上表中,Betty也喝了功能性饮料,但是她却没有出现头疼的症状。因此,我们不能说喝功能性饮料是出现头疼症状的充分条件,只能说是必要条件。
可以看到,契合法有一个局限性:它要求每一个案例都是一致的。如果有几百个人都生病了,只有一个人没有生病,只有一个人没生病,那么我们就无法找出精确的因果关系。
2)差异法 - 寻找充分条件
要想确定充分条件,我们就要考察出现某种结果和未出现某种结果的情况有什么差别,即如果每次只要出现某个原因,就一定会出现某个结果。
在本例中,所有熬夜的人第二天都很疲惫,而那几个没有熬夜的人第二天都很精神,那么我们就会发现熬夜是第二天很疲惫的一个充分条件。这就是穆勒的差异法。
假设我们收集到的观察数据如下:
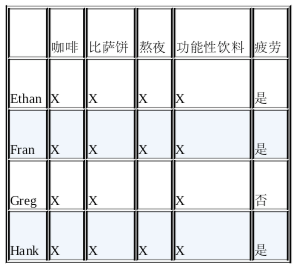
我们对比了疲劳案例和非疲劳案例之间的差异,会发现,对于出现疲劳结果的案例来说,所有4个因素都是一样,即都是契合的,所以我们无法通过契合法来确定其中一个因素就是导致疲劳的原因。
但是通过考察这些案例的差异,我们看到熬夜似乎是疲劳案例和非疲劳案例的唯一区别。
3)契合差异并用法 - 寻找充分必要条件
为了找出那些既是充分条件也是必要条件的原因,我们将契合法和差异法结合起来使用,这就是穆勒的契合差异并用法。
在这种情况下,我们要找的是那些每次出现某种结果时都会出现的因素,并且只有在出现这种结果时才会出现这些因素。
假设我们收集到的观察数据如下:

两个肚子疼的人都熬夜了,也都喝了咖啡,所以根据契合法,这两个因素都可能是导致肚子疼的原因。
接下来,我们用差异法继续细分,我们来考察一下这两个因素在那些肚子不疼的人和肚子疼的人身上有什么差别,我们发现,Diane熬夜了,但没有出现肚子疼的症状,所以熬夜并不满足差异法的要求,而喝咖啡满足差异法的要求,所以根据观察到的数据来看,喝咖啡是导致肚子疼的充分必要条件。
上述讨论了契合法、差异法、契合差异法,但是这里依然存在一个很大的问题!
假设我们观察到有2000人在熬夜后出现了肚子疼,但是仅有2个人在熬夜后肚子不疼,即必要性和充分性都不成立。那么我们就永远无法从观察数据中找到任何因果关系。
在现实生活中,有很多因果关系并不是每次都会出现的,所以穆勒要求的条件过于严格了。一般而言,我们不能仅凭几个反例就完全推翻一个原因。但这种方法仍然能为我们提供一个直觉式的指导原则,帮助我们探索各种因果假设,而且这种方法与我们对原因的一些定性研究所用的方法也是一致的。
4)剩余法
在现实中,只有一个原因和一个结果的情况也很少见。
也许人们吃比萨饼、熬夜、并且喝了大量咖啡,结果导致同时出现了很多疾病。如果我们观察到人们既出现的疲劳症状,又出现了肚子疼的症状,但是这些既疲劳又肚子疼的人之间并没有什么共同点,或者这些人和其他人并没有什么差别,那我们应该怎么做呢?有些情况下,我们希望可以将导致疲劳和肚子疼的不同原因区分开来。
假设我们收集到的观察数据如下:
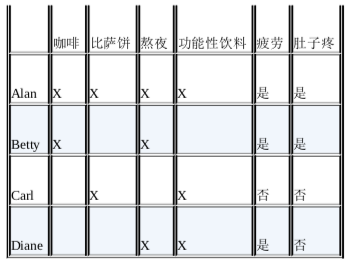
假设我们已经知道熬夜是导致疲劳的原因了,这样一来,就可以用熬夜来解释 Alan、Betty、Diane 感到疲劳的事实了。同时我们还知道熬夜并不会导致肚子疼,所以可以假设一定有其他因素导致了肚子疼。
接下来,我们只要考察一下所有肚子疼的案例之间有什么共同点和不同点就可以了,这就是所谓的排除已知的因果结果,得到剩余的因果结果。
一旦排除了疲劳和熬夜这两个因素,剩下的唯一一个共同因素就是喝咖啡了。这就是所谓的剩余法。
需要特别注意的是,剩余法存在以下几点问题:
- 需要待观测对象存在因果互斥结构:这个方法假定了我们已经知道所有其他可能的原因导致的所有结果,并且一个原因只会导致一个结果(因果结构之间需要互斥的)。如果现实情况是,熬夜和喝咖啡相互作用才会导致肚子疼,那么我们无法通过剩余法来来找到这种因果关系。解决这个问题的最好方法就是控制变量法,一次只改变一个变量。
- 无法得到证实性因果关系:我们可以根据这个方法做出一些假设,以此来推断可能是什么原因引起了我们所观察到的现象,但我们无法用它来证实某个关系一定就是因果关系。
- 观测变量集不完整:我们所研究的变量永远都只是所有可能被衡量出的变量的一个子集,它们可能只是我们根据感知到的相关性选择出来的,也可能只是我们事后分析数据时实际衡量出的变量。然而,真正的原因可能并不在那些假设之中,而这可能会让我们无法找到导致某个结果的原因,或者找到的可能只是表示原因的一个迹象。例如,如果每个吃比萨饼的人同时也喝了一些有问题的自来水,而我们的变量集中却没有包含喝水这个变量,那我们将会发现吃比萨饼是导致某种结果的一个虚假原因。
5)共变法
继续讨论编程马拉松的这个例子,也许那些程序员在工作的时候很容易吃过多的比萨饼,如果吃过多的比萨饼会导致体重增加,那么随着比萨饼食用量的增加,我们应该能够看到这些人的体重也随之增加,这就是穆勒的共变法。
在共变法中,原因和结果之间存在剂量效应(随着原因的增加,结果的剂量也随之增加)。
当然,实际情况总是更复杂一些,原因和结果之间的关系也并不总是线性关系。
以饮酒为例,随着饮酒量的增加(在一定范围内),饮酒对健康的好处也会协同增加,但如果饮酒过量就会造成对健康的反向伤害。有一个J形曲线反映了饮酒量与冠心病等健康问题之间的关系,
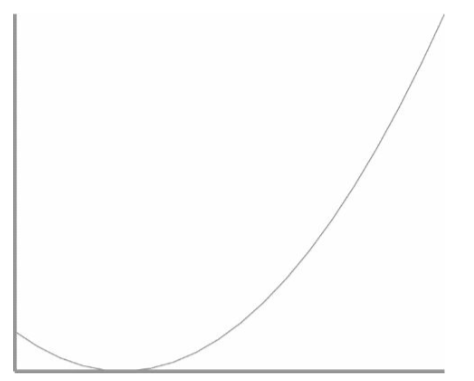
- 在每日饮酒量从0克上升到20克的过程中,疾病的发病率逐渐降低
- 在20克的时候,发病率达到最低点
- 但到了20克之后,随着饮酒量的增加,发病率开始上升
与之类似的关系还有很多,像运动强度和感染疾病概率的关系、和咖啡和心力衰竭之间的关系。和吃药一样,饮酒、喝咖啡以及运动等活动都有一个最优量,超过这个最优量后,它们就可能会危害健康。
一旦过了这个最优量之后,我们就看不到剂量效应了,相反,我们会看到该因素产生的效果开始逐渐减弱而不是不断增强。
3、穆勒五法应用的实际案例
John Snow 发现了1854年伦敦爆发霍乱的原因,这是历史上使用穆勒五法的最有名的案例之一。
在疫情爆发时,人们并不清楚疾病究竟是如何传播的,但有一张地图显示疾病的发病率在不同地域间存在明显差异。这个疾病是人传染给人的吗?居住地有什么东西引起了疾病的爆发呢?还是说仅仅是因为人们都生活在被感染的区域所以才导致了疾病的爆发?
Snow通过调查,发现了以下几个事实:
- 大部分死亡都发生在某个特定的地理区域,而且还都靠近宽街(Broad Street)的水泵
- 还有一些死亡案例不靠近宽街,这些房子里的居民只有10个死于霍乱,在这10个人中,有5个人的家属反馈说,死者总是去宽街的水泵取水,因为他们更喜欢那里的水。还有另外3个死者都是小孩,他们上学的地方靠近宽街的水泵。
Snow在完成数据收集后,开始进行了分析,他的推理过程如下:
- 死者大多数都使用过宽街水泵里的水,这里符合穆勒的契合法,即在所有出现某种结果(比如感染霍乱)的案例中寻找共同点
- 在伦敦这个区域,除了那些习惯饮用上述泵井中的水的人,还没有出现其他感染霍乱的特殊案例。他证实了霍乱的发病率在使用了那个水泵的人群中上升了,而且也只在那个人群中上升了。这就是差异法。
4、穆勒五法存在的问题与挑战
穆勒五法有一个问题:一个原因导致某种结果出现的可能性的大小,取决于除这个原因之外还存在哪些其他因素。
比如说:
- 分别服用两种药物可能对血糖没有任何影响,但同时服用可能就会产生相互作用,从而显著地提高血糖值。
- 酒驾和跟车距离太近单独一个,不一定会100%导致交通事故,但是当这2个因素组合在一起时,往往就会必然地导致交通事故。
- 能见度太低、路面结冰、鲁莽驾驶,这3个因素组合起来,就会以很高的概率导致交通事故
要想解决这个问题,就不能只看单一原因与单一结果之间成对的关系,而是要考虑导致某种结果的一系列因素的组合。
以流行病学研究为例,各种原因都是相互关联的,人们与各种环境的长期接触、生活方法、以及严重暴露(比如接触某种传染性疾病)等各种因素会共同影响人们的健康状况。这种情况在流行病学领域经常出现,因此,流行病学家 Kenneth Rothman 提出用饼形图来表示这些原因组合。
原因饼形图是由一系列足以导致某种结果的因素共同组成的,它包含能产生某种结果的所有必要因素。下图展示的是导致3起交通事故的原因组合饼形图:

在这个例子中,每一个饼形图都足以让这个结果发生,所以每一次这些因素出现时都会发生一起交通事故。然而,有很多不同的原因组合都能导致这个结果。所以这些因素中的每个单独因素都不是引起交通事故的必要条件。
休谟和穆勒的要求是,每次某个原因出现时都会导致相应的结果,但有时候让这个原因起作用的那些必要条件可能根本就没有出现,或者每次只有在出现某个原因时才会出现相应的条件,但有时不同的原因能导致同样的结果。
因此,休谟和穆勒的要求是一个极为严格的条件。在现实生活中,很多结果可能是通过多种方式产生的,并且这种情况往往都存在一系列原因。
0x2:John Leslie Mackie方法
从穆勒五法存在的问题出发,原因的概念就变成了因素组合中的一个组成部分,这组因素在一起时足以导致某种结果,但这个组合可能并不是出现某种结果的必要条件,因为像这样的原因组合可能有很多。
这就是 John Leslie Mackie的方法,他认为原因不过是那些 INUS条件(非必要充分条件中的非充分必要部分)而已。
在上一章饼形图的例子中,
- 每一块单独的饼形图都是不充分的,因为要想产生某种结果还需要和其他几块结合起来共同作用。
- 但是同时,每一块都是必要的,因为如果缺少其中任何一块,这种结果就不会出现。
- 另一方面,每个饼形图本身又都是非必要条件,因为可能会存在多个饼形图,它们中的每一个足以导致这样的结果
0x3:非决定论 -- 规律性推理的盲区
上面讨论了这么多关于规律性推理的话题,但是笔者需要提醒大家,并不是所有的原因都是 INUS条件。比如说,因果关系可能并不是永远不变的,所以即便我们拥有所有可能的信息,而且所有的必要条件也都出现了,但是结果却并不会百分之百出现,这就是非决定论。
放射性衰变就是一个例子,在这个过程中,我们永远无法确定某个粒子是否会在某个具体的时间点发生衰变,只能知道这件事情发生的概率。衰变永远不会有 INUS条件,因为衰变是没有充分条件的。
0x4:概率推理
1、为什么要使用概率
还是回到文章开头的那个例子:”如果你高中毕业了,找到了一份工作,并且婚后才生的孩子,那么你98%不会穷困潦倒。“。这句话暗示了一个因果关系:对于一个人来说,如果高中毕业、找到工作和婚后生子这些条件都成立,那么她就有98%的概率不会贫困。
人们之所以会对这个统计数据如此感兴趣,是因为这个概率十分接近100%。但是,
- 如此高的概率并不意味着这个关系就是因果关系。可能有些关系出现的概率很高,但并不是因果关系
- 还有一些关系是真正的因果关系,但这些因果关系中的原因可能只是降低了结果出现的概率,或者并未改变结果出现的概率
那么因果概率的理念到底有什么用处呢?
1)因果关系结构不确定
我们之所以需要使用概率法,是因为有些关系本身就是不确定的,比如放射性衰变的例子。概率法并不要求原因能百分百导致相应的结果,也不要求每次出现某个结果之前都会出现某个原因。
在这些情况下,即便穷尽毕生所学,我们仍然无法确定某个结果是否会发生。因为这种情况既不存在前面章节讨论的规律性,也不存在具有任何规律的变量组合。
物理学领域经常出现具有不确定性的案例(例如量子力学),但这种案例在日常生活中更加常见,比如下面我们讨论的例子。
假设 Alice 和 Bob 都喜欢上机器学习课程,而且都喜欢上下午的课。那么,无论我们是以上课的内容为条件还是以上课的时间为条件,都无法完全将 Alice 和 Bob 去上课的可能性区分开。如果我们只知道某个课程的上课时间,那么仍然能够从 Bob 是否上课的信息中推理出 Alice 有没有去上这堂课,因为 Bob 的上课与否可以向我们暗示这堂课的内容(相关性)。
在这个案例中,没有一个单一变量可以将 Alice 和 Bob 去上课的可能性分开。
假如我们增加一个变量,这个变量只有在某个课程的上课时间是下午且课程内容为机器学习的情况下才能成立,那么问题就解决了。但是,我们首先需要对这个问题以及潜在的因果关系有所了解,这样才能知道是否需要增加这个复杂的变量。
2)缺乏对事物的完整认知
在很多情况下,我们之所以认为有些事物看起来具有不确定性,只是因为我们缺乏对事物的完整认知。
例如,如果掌握了某种药物的作用机制,或者能观察到足够多这种药物的副作用案例,并且知道它在哪些人身上产生了副作用,那我们就能找到这种药物产生副作用的必要条件。
3)不完整的观察数据
绝大多数情况下,我们需要处理的不仅是观察数据,还要处理不完整的数据,例如:
- 我们不能强迫人们去吸烟以便观察谁会得癌症
- 有氧代谢能力可能是估算出来的,而不是通过在跑步机上进行最大摄氧量测试出来的,因为这对身体不健康的参与者来说可能也不安全
- 只能观察到一个有限的时间段,例如手术结束一年后的恢复情况,而不是三十年后的恢复状况
- 样本之间的采样间隔比我们想要的大得多,例如我们只能拿到每小时的脑代谢情况,而不是像脑电图一样的数据
- 技术上的局限性导致数据采集不完整,例如用微透析技术来测量代谢活动是一个缓慢的过程
总结来说,之所以要使用概率来定义因果关系,是因为我们不仅想要知道某个事物到底是不是原因,还想要知道这个事物到底有多重要。
具体来说,就是我们想要将某种药物的常见副作用和罕见副作用区分开来,或者想要找到最优可能增加就业机会的政策,要想量化某个原因对某个结果造成的影响,可以在使用连续变量的情况下测量这个结果的大小,或者在使用不连续变量的情况下测量这个结果发生的概率。
2、从概率到原因
休谟的研究方法的核心是原因和因果之间存在的规律性,而概率法的基本理念则是原因让结果出现的可能性更大。
如果一件事与另一件事之间没有因果联系,那么在第一件事出现后,第二件事出现的概率应该不会发生任何变化。
抛硬币时正面朝上和反面朝上的概率都是50%,而且每一次抛硬币都是一个独立的事件,所以每一次正面或反面朝上的概率并不会因为上一次抛硬币的结果而发生改变。

如果一件事会导致某个结果,那么在这件事发生后,这个结果出现的可能性应该比平时发现显著改变(增加或减少)。
由于蚊子会传播疟疾,因此如果某个地区的蚊子感染了疟疾,那么这个地区的疟疾发病率应该更高。
如果钾能够减缓肌肉痉挛现象,那么人们在服用了钾之后,肌肉痉挛的病例就应该有所减少,

在上图中,服用钾的概率比未服用钾的概率要低,所以我们用一个更窄的长条来表示服用钾的概率。然而,这个长条形的大部分都是阴影,因为在服用了钾之后,未出现痉挛的概率要高于出现痉挛的概率。相反,在未服用钾的情况下,出现痉挛的概率比未出现痉挛症的概率要高得多。
3、概率推理可能存在的雷区
1)关注绝对值和相对值
对一些事件来说,概率增加了一倍可能听起来差别很大,但如果这只是将一件事变成了两件事,那其实实际的增长并不是很大。比如说,
- 中风的风险可能从0.0000001增加到了0.0000002,这个增长实际上就可以忽略
- 交通出事的风险从0.1增加到了0.2,这个风险就要引起关注了
2)观察样本大小对概率推理置信度的影响
考察样本的大小(比如研究的人口群体有多大)尤为重要,如果观察的样本数量不显著,我们可能都无法将那些结果区分出来。某个差异的出现可能仅仅是自然变化、噪声、或者测量事物引起的。
比如说,蛛网膜下腔出血(SAH,一种极为罕见却致命的中风)的症状每年在10万人中只会出现8例。这就意味着,如果我们用一年的时间去观察10万人,或者用10年的时间去观察1万人,只能看到8起这种中风事件。
而如果观察一个更小的样本,我们观察到的这一事件发生的概率就会远远低于它真正发生的概率。这就是在小样本下大数定律失效的问题。
3. 辛普森悖论
在一些情况下,正相关的原因似乎降低了某种结果出现的概率,或者对某种结果没有任何影响,这又是怎么回事呢?之所以会出现这种情况,主要原因在于采集数据的样本和我们针对变量使用的粒度级别。
0x1:关于辛普森现象的描述
关于辛普森悖论的现象及其背后数学原理的讨论,可以参阅这篇文章。
0x2:样本集切割 - 解决辛普森悖论的一种有效方法
在面对这些辛普森悖论的案例中,我们可以通过增加更多信息来解释这些虚假的关系,具体来说就是考察更小的群体。
就存活率的例子来说,就是分别考察男性和女性小群体内部的情况。
这些实际上就是考察数据问题时使用的粒度级别,我们正在观察的概率实际上反映了概率背后的潜在关系,知道这一点有助于我们从数据中找到那些概率关系。
在制定政策时,我们需要知道某个群体中出现的概率是否也适用于这个政策针对的群体。
问题的关键在于,我们要确定何时以及如何划分手中的数据,因为考察越来越细化的子数据集并不能解决所有问题。整体数据集中不存在的、与直觉相悖的结果可能会出现在子数据集当中,而将这个数据进一步细化可能会导致这些结果再次逆转。
这也是很多因果关系问题的关键所在,我们绝不可能完全脱离因果关系的背景知识而去单独谈论因果关系问题,我们必须利用这种背景知识来选择数据分析的对象,并且用它来解释数据分析的结果。
4. 基于反事实推理原理进行因果推理
0x1:反事实推理的定义
除了正向的规律推理和概率推理,我们经常会从与事实相反的角度来谈论因果关系,例如:
- 如果你没有在我掷保龄球的时候弄出声响,我一定会击中的
- 如果外面再热一点的话,我一定会跑的慢一些
这些话指出了一种必要性或一种造成差异的因素,而这种因素或必要性并不包含任何规律。
通过休谟关于事件发生序列的规律性理论,我们仅能知道有些事件经常一起出现。而我们现在要试图阐明的是,在某种意义上,要想让这些事件按照它们已经发生过的方式再次出现,是离不开导致这些事件发生的那个原因的。如果这个原因没有出现,那么这些事件发生的方式就会打不相同了。这就叫反事实推理。
我们用规律法和反事实推理法来阐述同一个因果概念,
- 第一个事物出现在第二个事物之前,并且所有与第一个事物类似的事物出现之后,都会出现于第二个事物类似的事物,即规律性的定义
- 如果第一个事物不出现的话,那么第二个事物也永远都不会出现,即反事实推理的定义
在休谟的启发下,David Lewis 正式提出了反事实推理的理论基础:
要想让 C 能够引起 E,那么有两个条件必须成立:
- 如果 C 没有出现的话,那么 E 也不会出现
- 如果 C 出现了的话,那么 E 也会出现
这两个条件既包含了必要性又包含了充分性。
举例来说,如果我涂了防晒霜的话,那我就不会被晒伤了,而如果我没有涂防晒霜的话,那我就会被晒伤。
反事实推理法有点类似穆勒五法中的契合法+差异法,读者朋友可以将这个理论套用到前面编程马拉松的例子中。反事实推理法的这种通过一正一反的排他性证明,完整地将因果结构锁定了出来,避免了虚假因果性的问题。
从理论上来说,这个方法让我们能够将那些可能偶然一起发生的因素和那些真正导致某种结果的原因区分开来。
0x2:反事实推理法的局限
1、超定实例问题
反事实推理法也不是完美无缺,有一个著名的例子叫”拉斯普金案“。传说,他曾在吃蛋糕时喝下了有剧毒的葡萄酒,但并没有被立即毒死。结果有人朝他背后开了一枪,而他再次活了下来,接着又中了枪。最后,他被绑起来扔进了冰河之中,但他又自己解开了绳索!不过,最后拉斯普金还是被淹死了。
那么,他的死因是什么呢?我们能否肯定说如果他没有被下毒就不会死?或者有可能这个毒药过了一段才发挥作用?同理,中枪也可能会起同样的作用。
这个例子里出现了好几个原因,而且其中任何一个原因都可能导致某种结果,或者说我们没有找到任何原因,像这样的例子很难进行反事实推理。这些案例都是超定的实例,超定就是多余因果关系的对称形式。
在这个例子中,如果其中一个原因没有发生,结果依然可能会发现。从反事实推理的角度来看,这个结果并不依赖于每一个原因。
2、优先权问题
再来看另一种问题,有两个原因同时存在,但是只有一个原因随时都能起作用,另一个原因只是一个备胎,只有在第一个原因不起作用的情况下才会起作用。
生物学中经常会出现这种类型的备胎机制,比如有两个基因能够产生同样的显性特征,但是其中任何一个基因都能抑制另一个基因的作用,即基因A抑制基因B,以便只有在基因A不起作用的情况下基因B才会起作用。
在这种情况下,我们更是无法通过反事实推理法找到原因,这就是优先权问题。
3、反事实因果关系依赖链问题
1)因果关系链问题
在反事实推理方面,因果关系的具体结构还存在一个很麻烦的问题,即因果关系链。
如果存在一个反事实因果关系依赖链的话,那么这个依赖链中的第一个组成部分就是引起最后一个组成部分的原因。
举一个著名的例子,来自电影《老爸老妈罗曼史》,其中有一集讲的是两个人在争执到底是谁害他们错过了航班,以下是他们的争论,我们做了一些简化:
- Robin觉得是Barney的错,因为Barney在去见他的路上在地铁站翻了一个旋转栅门,所以导致Ted被开了罚单,并且不得不在飞机起飞的那天早上去法庭受审。
- Ted继续往前追溯,觉得这是Robin的错,因为Barney之所以要跑马拉松(因此他在地铁站才需要帮助)完全是由Robin导致的,Robin去Lily家导致Marshall不能跑马拉松,而只能让Barney代替去跑
- Robin则觉得错在Lily,因为她之所以会出现在Lily家(去睡一觉)并导致Marshall受到惊吓然后伤了脚趾,是因为Lily要排队买特价婚纱
- 故事的高超在最后,Ted经过一番分析,认为这件事归根结底是他的错,因为他发现了一枚罕见的幸运便士,然后她和Robin把这枚硬币卖掉了,用卖来的钱去婚纱店对面买了热狗,然后就得知了婚纱店在促销的消息
在这一集中,每一件事都有一个与事实相反的假设,彼此形成环环相扣的链状关系:
- 如果Ted没有去法庭的话,他就不会错过航班
- 如果Marshall去跑马拉松的话,Barney就不会需要Robin的帮助
- 如果Robin没有去婚纱店的话,Marshall的脚趾就不会断
- 而如果Ted没有捡到硬币的话他们就不会知道婚纱店在促销
在这个案例中,不同因果理论对真正的原因有着不同的观点。
- 有些理论寻找的是引发这一系列事件并导致某种结果的最早的因素
- 有些理论则想要找到最直接的原因
这些理论存在的问题是:我们可能会不断找到距离实际结果越来越远的事件。
2)因果依赖链问题
然而,还有更加麻烦的情况:某个事件通常会阻止某种结果的出现,但又会让这种结果以另一种方式出现,从而产生一个表面上的依赖链。
例如,有一个见义勇为的人在一列火车前面救了一个摔倒在铁轨上的人,但这个人后来却在跳伞时摔死了。要是他在铁轨上没有被救的话他就不会去跳伞(因为没有机会了),从反事实推理的角度来看,他的死亡是由被救这件事决定的。这样一来,这位见义勇为的人似乎反倒成了导致他死亡的因素。
这里面涉及到法律定责领域的一个核心问题,后果的可预见性,我们在之后的文章会详细讨论这个话题。
加载全部内容