李宏毅深度学习与人类语言处理-introduction
周若梣 人气:0
**深度学习与人类语言处理(Deep learning for Human Language Processing)**
李宏毅老师深度学习与人类语言处理课程笔记,请看正文
-----
### 这门课会学到什么?

- 为什么叫人类语言处理呢?
现在大家熟知的基本都是自然语言处理,那什么是自然语言呢?
>在自然中发展出来的用于沟通的语言(例如中文、英文)
自然语言相反的是人造语言:例如编程(Java、python)
人类的自然语言分为两种形态:语音、文字

所以这门课叫**深度学习与人类语言处理**
大多数自然语言处理课程中语音处理只占了一小部分,是因为语音处理不重要吗?

**世界上只有56%的语言可以被写出来**,例如闽南语、台语,但不是每个说闽南语的人都会写。文字的书写系统是被创造出来的。所以很多语言机器无法通过文字理解,所以这门课程会用一半的时间讲述语音处理。
- 人类语言有多复杂

一秒钟的声音信号含有16K个采样点,每个采样点有256个可能的值。
> 古希腊哲学家赫拉克利特说过 "No man ever steps in the same river twice, for it's not the same river and he's not the same man."
**没有人可以说同一段话两次**,每次的声音信号都不一样
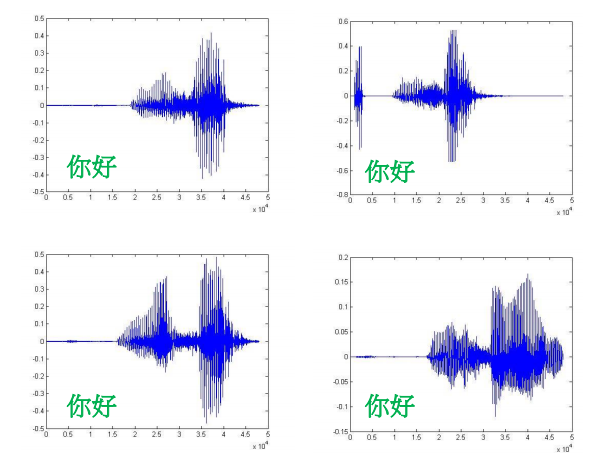
那么文本有多复杂?
有记录的最长英文的句子有13955个词(2014,吉尼斯世界纪录)
然而,,,下一秒吉尼斯世界记录就被破了,xx写“ ”;xx说xx写了“..."

- 一张图告诉你本次课程内容
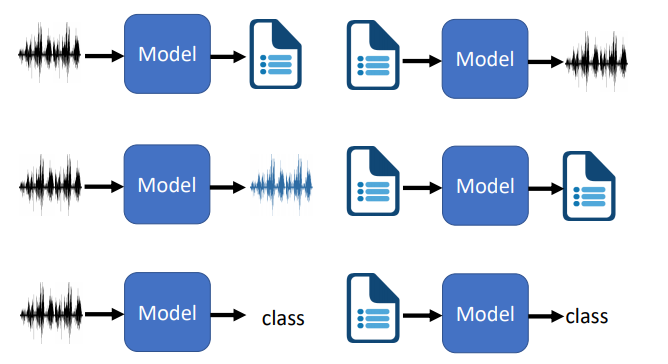
**Model是什么?**

**硬Train一发**是一种信念,是一种梦想,是一种浪漫,是人类亘古以来原始的冲动,总之,没办法一句话解释清楚。
### 人类语言处理的下一步
2014年seq2seq模型横空出世,可以解决大多数人类语言相关的问题,在拥有目前为止最强武器Deep learning的情况下,人类自然语言处理的下一步在哪里?
这门课程将会关注近三年来的研究,再有了*硬train一发*后,接下来还有什么技术?
- 语音到文本(语音识别)
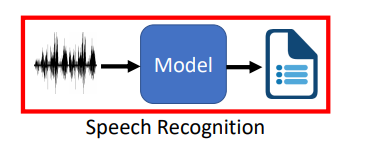
传统语音识别,由多个模块构成,组合起来模型很大,2个G

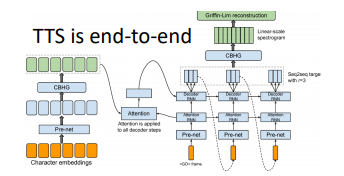
那如果使用端到端的深度学习呢?google的模型只有80M
语音上的seq2seq模型并**不是大家所熟知的基于Attention的seq2seq模型**,我们会揭开语音seq2seq模型的神秘面纱,看看不同领域的seq2seq模型有什么区别
- 文本到语音(语音合成)
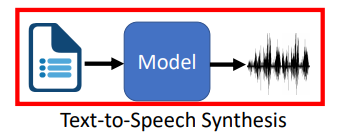
语音合成是怎么做的?训练一个神经网络,输入是文字,输出是语音,然后就没有然后了。。。
> Tokuda"每次我开除一个语言学家,语音识别的性能就会提升一点。"
**所有的问题都被神经网络解决了吗?**
google小姐发生过破音!在输入多个字是正常发音,输入单字时破音了,有想去的可以去看看 :https://www.youtube.com/watch?v=EwbTlnUkctM
- 语音到语音

语音到语音什么用呢?
**1.语音分离**(speech separation)
人类可以从不同说话者中辨别说话人,专注于想要听的说话人;机器可以吗?现在用NN已经可以做到了,仅仅硬train一发
**2.声音转化**(voice convesion)
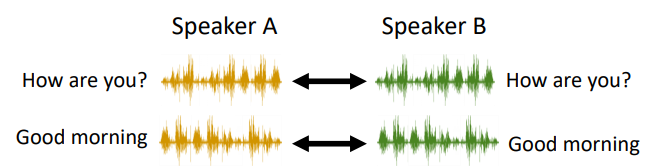
让A和B说同一句话,采集很多样本,使用NN*硬Train一发*就可以了,但是如何想要把我的声音转化成新垣结衣的声音,就不行了,因为我不能把新垣结衣找来,新垣结衣不会说中文啊。所以我们希望的声音转化系统只听过A的声音,B的声音,不一定要念一样的句子,机器也可以把A声音转化为B声音
- 语音到类别
可以用在说话人识别、语音唤醒
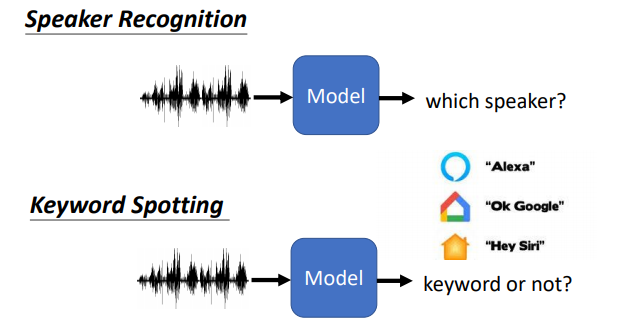
需要说出指定唤醒词才可以唤醒它们,但是机器需要不断的收集声音,直到听见唤醒词,所以模型需要尽量小,降低功耗。
- 输入是文本
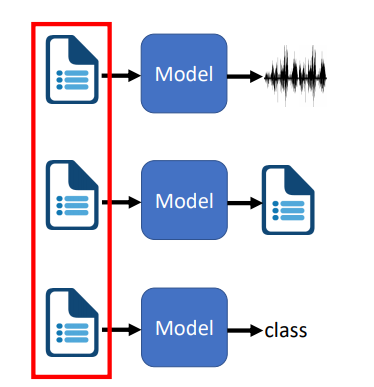
Bert一脚踢翻了玛利亚之墙
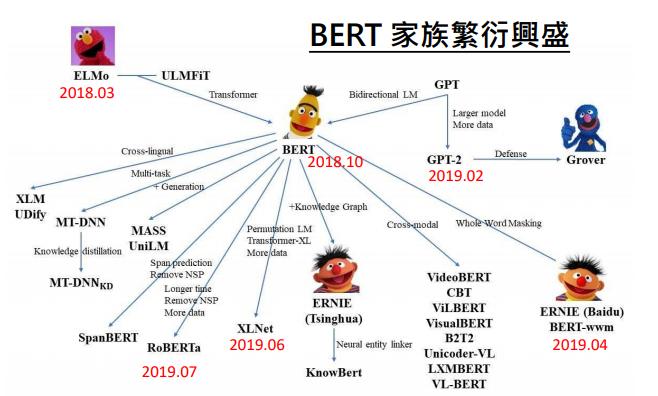
模型越来越大。。。

- 输出是文字
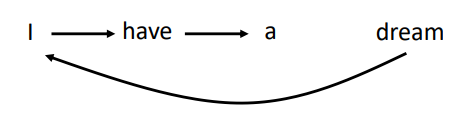
**文本生成**(Text Generation)
Autoregressive:
$$
I \rightarrow have \rightarrow a \rightarrow dream
$$
句子一定要按顺序生成吗?
Non-autoregressive :
- 输入输出都是文字

机器翻译、文本摘要、聊天机器人、问答系统
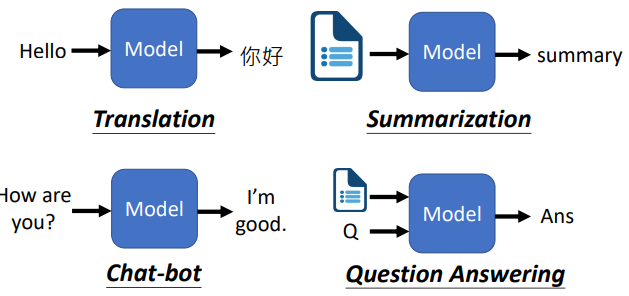
直觉上不是文本到文本问题也可以被转化成文本到文本,例如句法分析(systactic parsing),可以把句法分析树变成文本
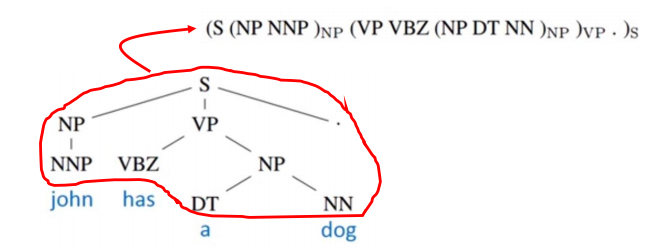
这次课程聚焦于问答系统,其他的应用使用的方法都是大同小异。
### 更多内容
- 元学习
- 参考图像风格转化
- 知识图谱
- 对抗攻击
- 可解释AI
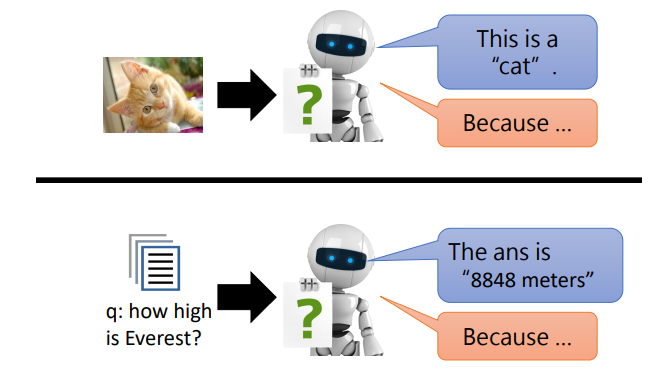
以上就是本次课程涉及的所有内容
>语音和文本相爱想杀的故事
reference:
李宏毅老湿. http://speech.ee.ntu.edu.tw/~tlkagk/courses_DLHLP20.html
加载全部内容