谈谈集合.Map
写代码的木公 人气:0
------
本文来谈谈我们平时使用最多的HashMap。
------
### 1. 简介
`HashMap`是我们在开发过程中用的最多的一个集合结构,没有之一。`HashMap`实现了Map接口,内部存放Key-Value键值对,支持泛型。在`JDK1.8`以前,`HashMap`内部是以数组加链表的结构维护键值对数据。在`JDK1.8`中,`HashMap`以数组、链表加红黑树的结构维护数据,当链表长度大于8以后会自动转为红黑树提升数据增删改查的效率。另外`JDK`还提供了很多Map接口的其他实现,比较常用的有`LinkedHashMap`、`TreeMap`以及已经淘汰但是经常拿来和`HashMap`做对比的`HashTable`。他们的继承关系如下。
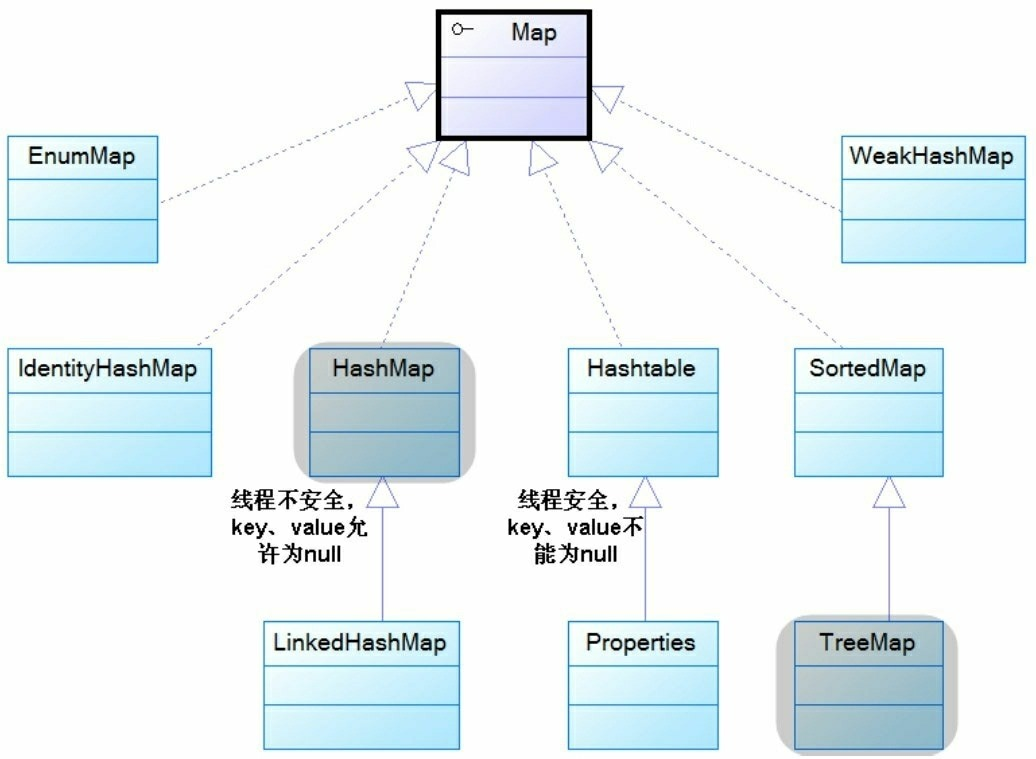
值得注意的是`HashMap`不是线程安全的,所以`JDK`又提供了`ConcurrentHashMap`和`SynchronizedMap`等,可以在多线程环境下使用。
### 2. `HashMap`中一些常量介绍
```java
// Hash表的默认初始化长度,默认是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//Hash表的最大长度
static final int MAXIMUM_CAPACITY = 1 << 30;
//默认负载因子,负载因子的大小可以平衡时间和空间的关系,如果负载因子较大,比较节省空间,但是增加了Hash碰撞的几率
//如果负载因子较小,resize会发生的比较频繁,空间利用率不高,但是减少了Hash碰撞的概率。
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//当桶上面的链表长度大于8时,链表会转换成树结构
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
static final int MIN_TREEIFY_CAPACITY = 64
transient Node[] table;
/**
* Holds cached entrySet(). Note that AbstractMap fields are used
* for keySet() and values().
*/
transient Set> entrySet;
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount;
/**
* The next size value at which to resize (capacity * load factor).
*
* @serial
*/
// (The javadoc description is true upon serialization.
// Additionally, if the table array has not been allocated, this
// field holds the initial array capacity, or zero signifying
// DEFAULT_INITIAL_CAPACITY.)
int threshold;
/**
* The load factor for the hash table.
*
* @serial
*/
final float loadFactor;
```
### 2. 确定Hash桶位置分析
`HashMap`在将键值对放入Map中的第一步是找出这个键值对在Hash表中的位置。`JDK1.8`中`HashMap`的做法是:
```java
//第一步:获得key的hashCode,并加入扰动函数,增加hash值的随机性,减少冲突。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
//其中n是Hash表的长度,相当于hash%n
(n - 1) & hash
```
总的来说,`HashMap`在计算元素在桶中位置的算法很简单:就是根据key的`Hashcode`值,加入扰动函数之后再跟Hasn表的长度取余就得到这个键值对在Hash表中的位置。这边加入扰动函数的做法是:**将key本身的Hashcode值右移16位,再跟自身进行异或。自己的高半区和低半区做异或,就是为了混合原始哈希码的高位和低位,以此来加大低位的随机性。**
> Peter Lawley在文章《An introduction to optimising a hashing strategy》里做了一个实验:他随机选取了352个字符串,在他们散列值完全没有冲突的前提下,对它们做低位掩码,取数组下标。结果显示,当HashMap数组长度为512的时候,也就是用掩码取低9位的时候,在没有扰动函数的情况下,发生了103次碰撞,接近30%。而在使用了扰动函数之后只有92次碰撞。碰撞减少了将近10%。看来扰动函数确实还是有功效的。[见本文](https://www.javacodegeeks.com/2015/09/an-introduction-to-optimising-a-hashing-strategy.html)
### 3. put方法分析
确定好键值对(Entry)的位置后,`HashMap`进行`put`操作。下面以`JDK1.8`的代码做下分析。
```java
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
//step1:判断Hash表是否为空,如果为空就创建一个长度为16的Hash表
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//step2:如果这Hash桶位置上没数据,直接在这个位置上创建
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;
//step3:如果这个Key在HashMap中已经存在,直接覆盖这个key的值
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
//step4:以红黑树的方式加入该键值对
else if (p instanceof TreeNode)
e = ((TreeNode)p).putTreeVal(this, tab, hash, key, value);
else {
//step5:这个桶上是链表,遍历链表,如果在遍历过程中发现这个key已经存在,直接覆盖这个key的值返回
// 如果发现这个key不存在,直接在链表尾部加入这个键值对,并判断链表长度是否大于8,如果长度大于8转为红黑树
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
//step6:如果key之前在HashMap中存在,用新值覆盖旧值,并返回旧值
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
//如果size大于阈值就行进扩容。
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
```
总结一下HashMap进行put元素的过程:
**step1**:会先判断Hash表是否创建,如果没被创建(也就是在创建HashMap时没指定任何参数),就创建一个长度为16的Hash表,并将阈值设置为12;
**step2**:根据key的hashCode值计算出在Hash表中的位置,如果**这个位置上没任何元素**,直接在这个位置上创建元素,然后将size++后就结束了。如果这个位置上有元素进入步骤3.
**step3**:**如果这个位置上有元素**,判断这个元素是否和新加入元素的key相等(判断的标准是key的hash值相等,并且通过equals方法比较也相等),如果相等用新元素的value覆盖旧元素的value,并且返回旧元素的值,方法结束,否则进入步骤4;
**step4**:判断这个位置上是不是一个树形结构,如果是树形结构,按红黑树的形式加入元素,然后返回;否则进入步骤5;
**step5**:进入步骤5的话,那么这儿位置上一定是一个链表结构,遍历链表,如果在遍历过程中发现这个key已经存在,直接覆盖这个key的值返回,如果发现这个key不存在,直接在链表尾部加入这个键值对,并判断链表长度是否大于8,如果长度大于8转为红黑树。
至此,整个put过程结束。顺便提下,`HashMap`是**允许元素的键值为null,并且会存放在Hash表的第一个位置**。
### 4. get方法分析
HashMap的get方法比较简单,源代码如下:
```
final Node getNode(int hash, Object key) {
Node[] tab; Node first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
```
如果hash表为空,或者hash值所在的桶位置上没有值则直接返回null。否则就通过比较key的hash值和equals方法,两者都相等就返回对应的value值。
### 5. 扩容机制分析
当元素向`HashMap`容器中添加元素的时候,会判断当前元素的个数,如果当前元素的个数大于等于阈值时,即当前数组table的长度加载因子就要进行自动扩容。
由于`HashMap`的底层数据结构是“链表散列”,即数组和链表的组合,而数组是无法自动扩容的,所以只能是换一个更大的数组去装填以前的元素和将要添加的新元素。
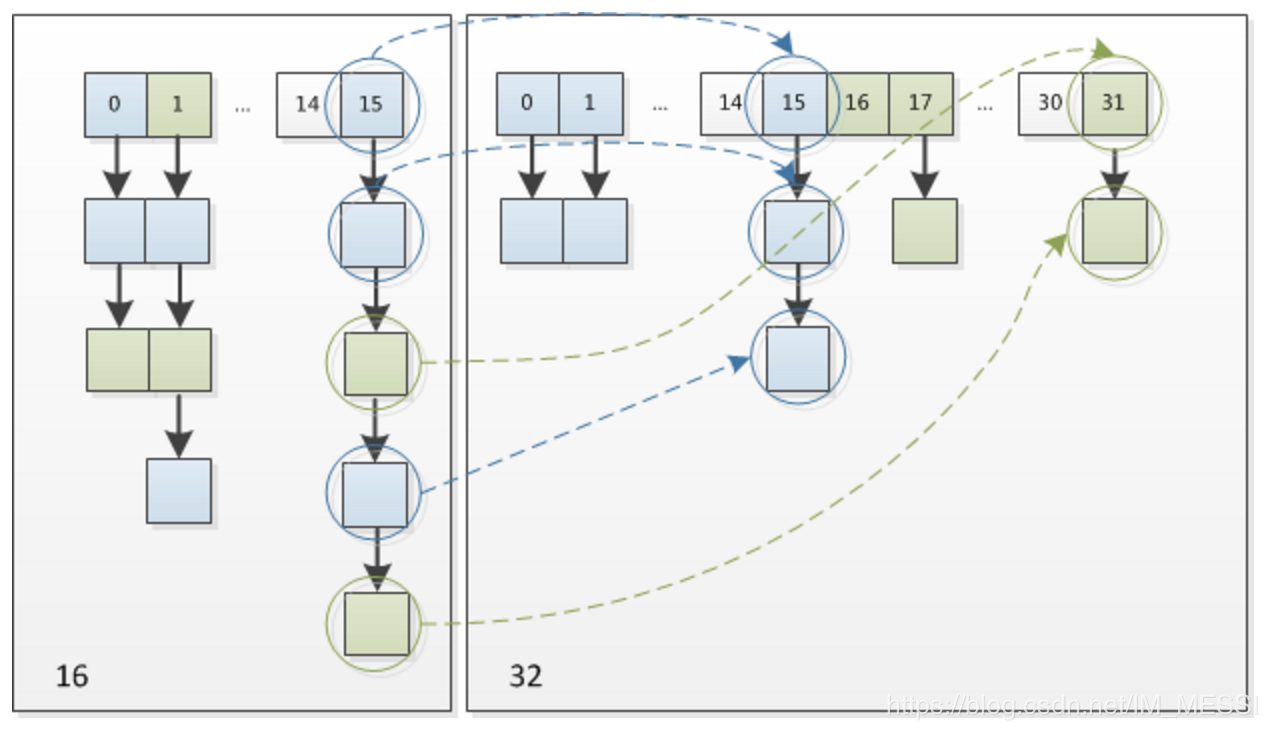
`HashMap`的扩容过程是这样的:首先会创建一个大小是原来一倍的数组(如果原来的数组大小已经达到的最大值,那么不会再创建新的数组,只是将阈值改成最大值然后返回原数组),然后将旧数组中的元素一个个复制到新数组中。从整体上看,扩容就是这么一个简单的过程,只不过`HashMap`在重新计算元素在新数组中位置的时候针对不同的元素采取了些优化措施。比如原来旧数组中每个位置上的值是null值就直接跳过了;如果原来位置上的值是单个值,先通过这个值的hashcode值取余新数组的长度,得出在新数组中的位置,然后再赋值过去;如果原来位置上是一个红黑树结构,就调用split()方法进行拆分放置(这块代码没仔细看过);如果是链表结构,那么元素在新数组中的位置要么和之前一样,要么就是现在的位置加上旧数组的长度。
### 6. 线程安全相关
大家都知道`HashMap`是线程非安全的。下面的情况会产生线程安全问题。
1. `put`的时候导致的多线程数据不一致
比如有两个线程A和B,首先A希望插入一个key-value对到`HashMap`中,首先计算记录所要落到的 hash桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的 hash桶索引和线程B要插入的记录计算出来的 hash桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。
2. `resize`而引起死循环(JDK1.8已经不会出现该问题)
这种情况发生在`JDK1.7` 中`HashMap`自动扩容时,当2个线程同时检测到元素个数超过 数组大小 × 负载因子。此时2个线程会在put()方法中调用了resize(),两个线程同时修改一个链表结构会产生一个循环链表(JDK1.7中,会出现resize前后元素顺序倒置的情况)。接下来再想通过get()获取某一个元素,就会出现死循环。具体产生死循环的原因请看这篇[博客](https://www.jianshu.com/p/1e9cf0ac07f4)
**线程安全的Map**
- Hashtable
- ConcurrentHashMap
- Synchronized Map
`ConcurrentHashMap`这边先不介绍,后面会专门写文章介绍。`SynchronizedMap`是集合工具类生成的并发类,其实现线程安全的原理是在每个方法上加了`synchronized`。
下面介绍下`HashMap`和`HashTable`的区别。
> 1.`HashTable`的方法是同步的,在方法的前面都有synchronized来同步,`HashMap`未经同步,所以在多线程场合要手动同步.
> 2.`HashTable`不允许null值(key和value都不可以) ,`HashMap`允许null值(key和value都可以)。
> 3.`HashTable`有一个contains(Object value)功能和containsValue(Object value)功能一样。
> 4.`HashTable`使用Enumeration进行遍历,`HashMap`使用Iterator进行遍历。
>
> 5.`HashTable`中hash数组默认大小是11,增加的方式是 old*2+1。`HashMap`中hash数组的默认大小是16,而且一定是2的指数。
### 7. 其他Map实现
#### 7.1 `TreeMap`
`TreeMap`是有序的Map结构。应用在需要根据key排序的场景下。`TreeMap`内部是通过红黑树实现有序的。这边就不进行深入研究了。感兴趣的大家可以自己研究下代码。
下面提供下`TreeMap`的使用示例:
```java
//根据key的默认排序顺序排序
TreeMap treeMap = new TreeMap<>();
treeMap.put("Java","obj");
treeMap.put("Python","obk");
treeMap.put("C##","oxx");
treeMap.forEach((key,value) ->{
System.out.println("["+key+"]"+":"+"["+value+"]");
});
//自定义key的排序顺序
//如果自定义了比较器,那么TreeMap比较两个key是否相等的规则就变成
//首先根据hashcode判断,然后通过key的compare方法判断,而不是通过equals方法判断了
TreeMap treeMap1 = new TreeMap<>(new Comparator() {
@Override
public int compare(String o1, String o2) {
return o1.compareToIgnoreCase(o2);
}
});
treeMap1.put("Java","obj");
treeMap1.put("Python","obk");
treeMap1.put("java","oxx");
treeMap1.forEach((key,value) ->{
System.out.println("["+key+"]"+":"+"["+value+"]");
});
```
#### 7.2 `LinkedHashMap`
`LinkedHashMap`继承于`HashMap`,`HashMap`是无序的,当我们希望有顺序地去存储key-value时,就需要使用LinkedHashMap了。`LinkedHashMap`使用双向链表维护顺序。(**Entry中维护了两个指针,分别指向前面的节点和后面的节点**)
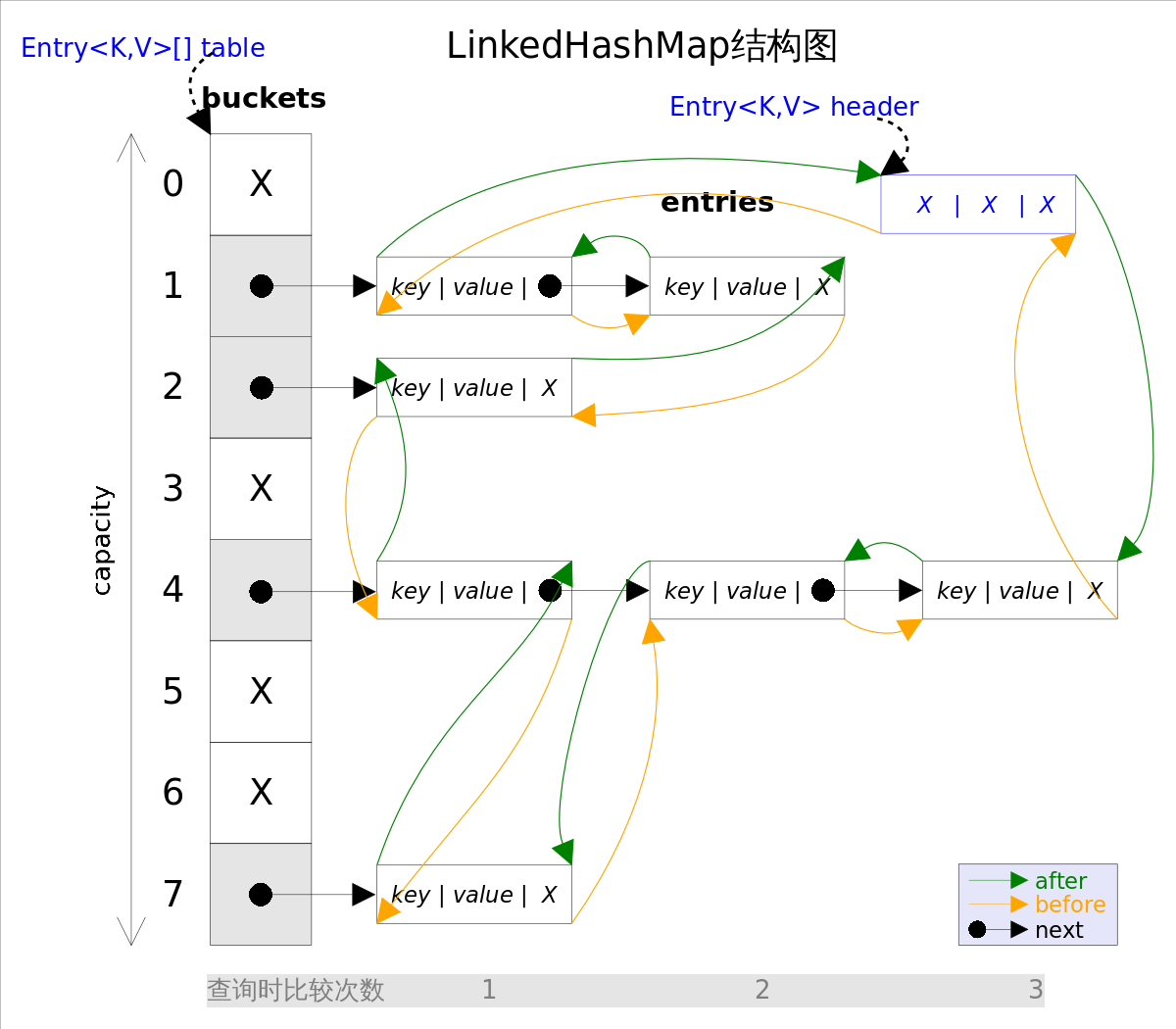
`LinkedHashMap`的有序性分两种:插入顺序和访问顺序。
`LinkedHashMap`的构造函数的参数中有一个`accessOrder`的参数。这个`accessOrder`设置为false,表示以插入顺序访问Map中的值。这个也是默认值。
```java
LinkedHashMap linkedHashMap = new LinkedHashMap<>(16, 0.75f, true);
linkedHashMap.put("name1","Java");
linkedHashMap.put("name2","Python");
linkedHashMap.put("name3","C##");
linkedHashMap.forEach((key,value) ->{
System.out.println("["+key+"]"+":"+"["+value+"]");
});
```
输出
```java
[name1]:[Java]
[name2]:[Python]
[name3]:[C##]
```
输出的顺序和我们put元素的顺序是一致的。
还有一种模式是访问顺序模式,也就是将`accessOrder`设置成`true`。我们来看下效果。
```java
LinkedHashMap linkedHashMap = new LinkedHashMap<>(16, 0.75f, true);
linkedHashMap.put("name1","Java");
linkedHashMap.put("name2","Python");
linkedHashMap.put("name3","C##");
linkedHashMap.get("name2");
linkedHashMap.get("name1");
linkedHashMap.forEach((key,value) ->{
System.out.println("["+key+"]"+":"+"["+value+"]");
});
```
输出
```java
[name3]:[C##]
[name2]:[Python]
[name1]:[Java]
```
**可以看出,在访问顺序模式下,通过get方法和put方法访问过的元素都会被放置到双向链表的尾部。**
### 参考
- https://www.cnblogs.com/xawei/p/6747660.html
- https://blog.csdn.net/zs319428/articlehttps://img.qb5200.com/download-x/details/81984635
- https://blog.csdn.net/yan_wenliang/articlehttps://img.qb5200.com/download-x/details/50976113
加载全部内容