java io 总结 java中的Io(input与output)操作总结(四)
人气:0想了解java中的Io(input与output)操作总结(四)的相关内容吗,在本文为您仔细讲解java io 总结的相关知识和一些Code实例,欢迎阅读和指正,我们先划重点:io,input,output,下面大家一起来学习吧。
前面已经把java io的主要操作讲完了 这一节我们来说说关于java io的其他内容
Serializable序列化
实例1:对象的序列化
复制代码 代码如下:
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.io.Serializable;
@SuppressWarnings("serial")
//一个类要想实现序列化则必须实现Serializable接口
class Person implements Serializable {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String toString() {
return "Name:" + this.name + ", Age:" + this.age;
}
}
public class Demo {
public static void main(String[] args) {
String path = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "demo.txt";
Person p1 = new Person("zhangsan",12);
Person p2 = new Person("lisi",14);
//此处创建文件写入流的引用是要给ObjectOutputStream的构造函数玩儿
FileOutputStream fos = null;
ObjectOutputStream oos = null;
try {
fos = new FileOutputStream(path);
oos = new ObjectOutputStream(fos);
//这里可以写入对象,也可以写入其他类型数据
oos.writeObject(p1);
oos.writeObject(p2);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
oos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
所谓对象序列化就是把一个对象进行持久化存储,方便保留其属性
通俗点说,等于把一个对象从堆内存里边揪出来放到硬盘上
当然,如果你开心,你可以序列化其他东西,包括数组,基本数据类型等等
来看看内容,神马玩意儿这是……
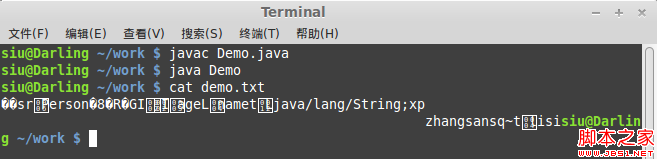
实例2:对象的反序列化
复制代码 代码如下:
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class Demo {
public static void main(String[] args) {
String path = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "demo.txt";
//好吧,这里代码写得着实有点长了,还要抛异常什么的
//如果你也看的烦,那就在主方法上抛吧,构造方法里用匿名对象就好了
//什么?别告诉我你不知道匿名对象
FileInputStream fis = null;
ObjectInputStream ois = null;
try {
fis = new FileInputStream(path);
ois = new ObjectInputStream(fis);
//这里返回的其实是一个Object类对象
//因为我们已知它是个Person类对象
//所以,就地把它给向下转型了
Person p = (Person)ois.readObject();
System.out.println(p);
//抛死你,烦烦烦~!!!
} catch (IOException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} finally {
try {
//还是要记得关闭下流
ois.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
你看,我们把一个对象存放在硬盘上是为了方便日后使用
现在用得着它了,自然得拿出来
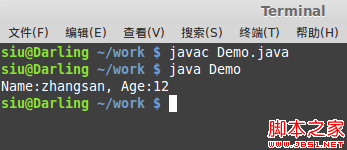
管道流
实例3:线程的通信
复制代码 代码如下:
import java.io.IOException;
import java.io.PipedInputStream;
import java.io.PipedOutputStream;
//实现Runnable接口,实现一个读的线程
class Read implements Runnable {
private PipedInputStream in;
//将需要读的管道流传入到构造函数中
public Read(PipedInputStream in) {
this.in = in;
}
//实现读这一线程
public void run() {
try {
byte[] buf = new byte[1024];
int temp = 0;
//循环读取
//read是一个阻塞方法,需要抛异常
//此处把打印流的代码也加入进来
//是因为如果没有读取到数据,那么打印的代码也无效
while((temp = in.read(buf)) != -1) {
String str = new String(buf,0,temp);
System.out.println(str);
}
} catch (IOException e) {
//其实这里应抛出一个自定义异常的
//暂时我还没弄清楚
e.printStackTrace();
} finally {
try {
//我已经抛火了,这只是为了提醒自己异常很重要
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
//这里实现一个写的类
class Write implements Runnable {
private PipedOutputStream out;
//将管道输入流传进来
public Write(PipedOutputStream out) {
this.out = out;
}
public void run() {
try {
//这里开始写出数据
out.write("管道输出".getBytes());
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
//其实应该可以把这个关闭方法写到上面那个try里边
//但是这样感觉怪怪的,逻辑不大对
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
public class Demo {
public static void main(String[] args) {
PipedInputStream in = new PipedInputStream();
PipedOutputStream out = new PipedOutputStream();
try {
//连接管道
in.connect(out);
//创建对象,开启线程
//此处同样放进try...catch里面
//因为如果没有链接管道,下面操作无意义
Read r = new Read(in);
Write w = new Write(out);
//把已经实现好run方法的对象放入线程中执行
new Thread(r).start();
new Thread(w).start();
} catch (IOException e) {
e.printStackTrace();
}
}
}
好吧,废了那么大劲儿,就打印了这么一句话,异常抛弃来很烦,为了注重细节……
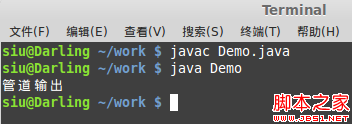
管道流也许很难理解,其实非也
我们知道,字节流和字符流都需要数组来进行流的中转
而管道流则直接串联两条流,一边发送数据,一边接收
然而,同时通信的的两种状态,如何才能确定发送和接收的一致性呢
那么,就需要用到线程,无论是接收方还是发送方先执行
总会造成一个线程的阻塞状态,从而等待另一方的数据传过来
总体而言,管道流的目的,也就是为了线程通信
此外,还有PipedReader和PipedWriter类,操作原理都一样,这里就不再赘述了
DataOutputStream和DataInputStream类
实例4:基本数据类型的写入
复制代码 代码如下:
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo {
public static void main(String[] args) {
String path = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "demo.txt";
DataOutputStream d = null;
try {
//此处需要传入一个OutputStream类的对象
d = new DataOutputStream(new FileOutputStream(path));
//开始写入基本数据类型
d.writeInt(12);
d.writeBoolean(true);
d.writeDouble(12.2223);
d.writeChar(97);
//刷新流
d.flush();
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
d.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
此处我们并不能直观看懂内容,因为它采用字节流的方式操作,而不是字符流
我们只需要知道,此程序已经将基本数据类型写入到硬盘即可

实例5:基本数据类型的读取
复制代码 代码如下:
import java.io.DataInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
public class Demo {
public static void main(String[] args) {
String path = File.separator + "home" + File.separator + "siu" +
File.separator + "work" + File.separator + "demo.txt";
DataInputStream d = null;
try {
d = new DataInputStream(new FileInputStream(path));
//按存储顺序读取基本数据类型
System.out.println(d.readInt());
System.out.println(d.readBoolean());
System.out.println(d.readDouble());
System.out.println(d.readChar());
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
d.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
这里要注意的是,一定要按照写入顺序读取,否则会发生数据的打印错误
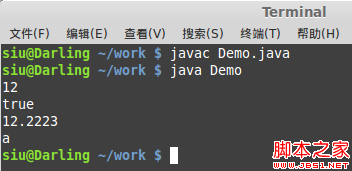
加载全部内容