图解MySQL索引(上)—MySQL有中“8种”索引?
浪人~ 人气:1关于MySQL索引相关的内容,一直是一个让人头疼的问题,尤其是对于初学者来说。笔者曾在很长一段时间内深陷其中,无法分清“覆盖索引,辅助索引,唯一索引,Hash索引,B-Tree索引……”到底是些什么东西,导致在面试过程中进入比较尴尬的局面。
很多人可能会抱怨”面试造火箭,工作拧螺丝,很多知识都是为了面试学的,工作中根本用不到!“。庆幸的是,MySQL中索引不仅是面试必考知识,还是工作中用到最为频繁的必备技能,在笔者看来,索引是MySQL中性价比最高的一部分内容。
由于MySQL中支持多种存储引擎,在不同的存储引擎中实现略微有所差距,索引下文中如果没有特殊声明,默认指的都是InnoDB存储引擎,下文中索引基于这张user表来进行延迟。
| id | name | age |
|---|---|---|
| 001 | Lily | 18 |
| 002 | Tom | 20 |
| 003 | Jack | 19 |
| 004 | John | 28 |
| 005 | Alice | 24 |
| 006 | Lucy | 21 |
| 007 | Rose | 18 |
| 008 | Steven | 16 |
一、索引的底层数据结构
首先,索引是高效获取数据的数据结构。就像书中的目录一样,我们可以通过它快速定位到数据所在的位置,从而提高数据查询的效率。
在MySQL中有许多关于索引的名词和概念,对于初学者来说很容易被迷惑。为了方便理解,我建立了一张表,从具体的案例中尝试说清楚这些概念到底是什么。
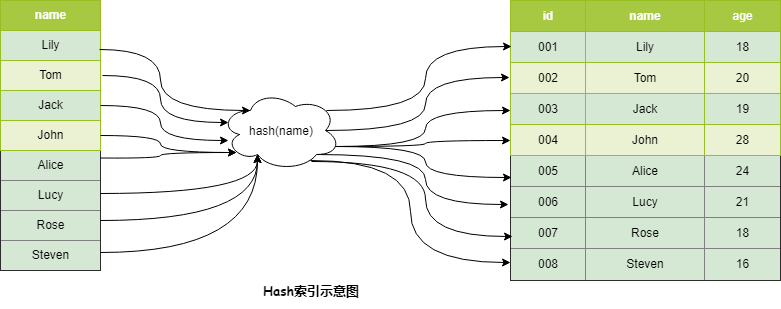
Hash索引
正如上文中说到,索引是提高查询效率的数据结构,而能够提高查询效率的数据结构有很多,如二叉搜索树,红黑树,跳表,哈希表(散列表)等,而MySQL中用到了B+Tree和散列表(Hash表)作为索引的底层数据结构。
需要注意的是,MySQL并没有显式支持Hash索引,而是作为内部的一种优化,对于热点的数据会自动生成Hash索引,也叫自适应Hash索引。
Hash索引在等值查询中,可以O(1)时间复杂度定位到数据,效率非常高,但是不支持范围查询。在许多编程语言以及数据库中都会用到这个数据结构,如Redis支持的Hash数据结构。具体结构如下:
B+Tree索引
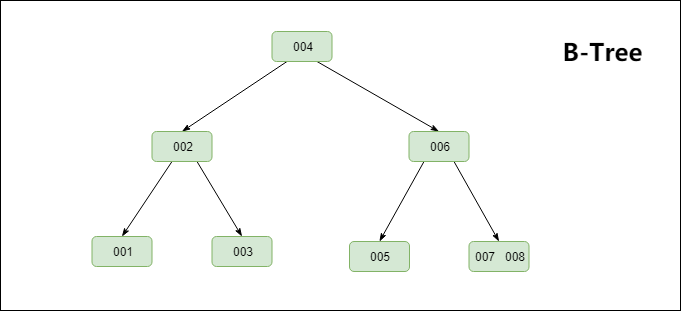
提到B+Tree首先不的不提B-Tree,B-Tree(多路搜索树,并不是二叉的)是一种常见的数据结构。使用B-tree结构可以显著减少定位记录时所经历的中间过程,从而加快存取速度。
B+ 树是基于B-Tree升级后的一种树数据结构,通常用于数据库和操作系统的文件系统中。B+ 树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度。B+ 树元素自底向上插入,这与二叉树恰好相反。
MySQL索引的实现也是基于这种高效的数据结构。具体数据结构如下:
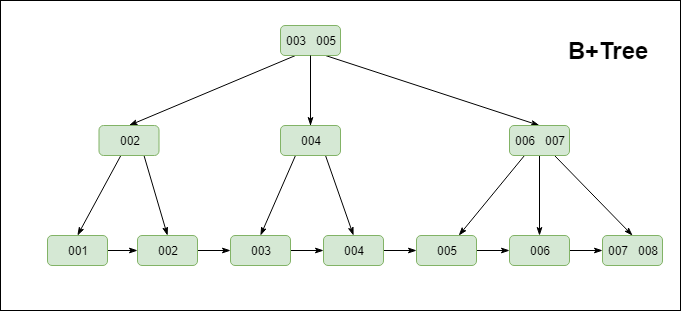
笔者首先要声明一下,不要将B树,B-Tree以及B+Tree弄混淆。首先,B-Tree就是B树,中间的“-”是一个中划线,而不是减号,并不存在"B减树"这种数据结构。其次,就是B+Tree和B-Tree实现索引时有两个区别,具体可见下图
①B+Tree只在叶子节点存储数据,而B-Tree的数据存储在各个节点中
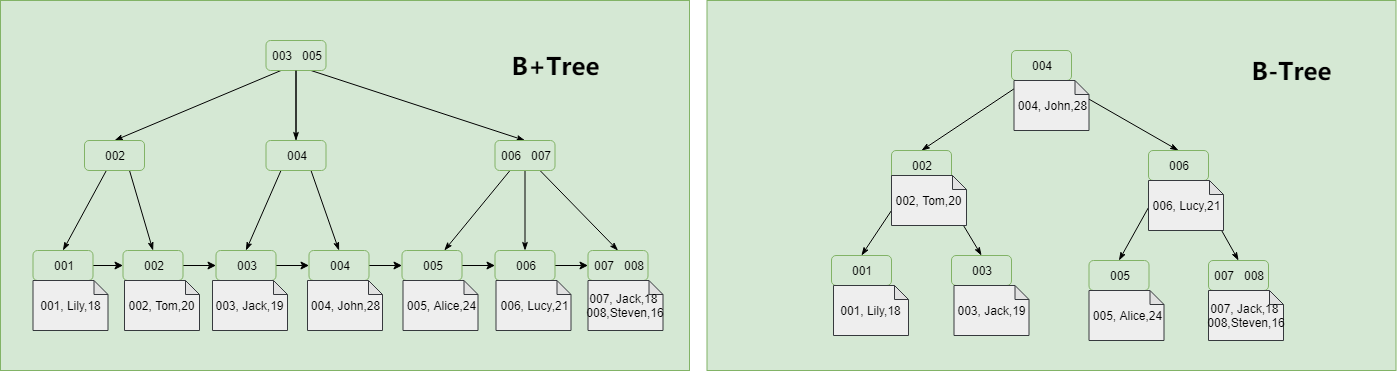
②B+Tree的叶子节点间通过指针链接,可以通过遍历叶子节点即可获取所有数据。
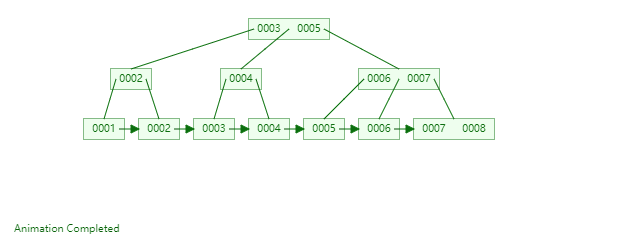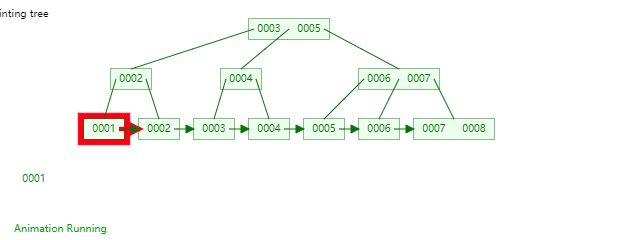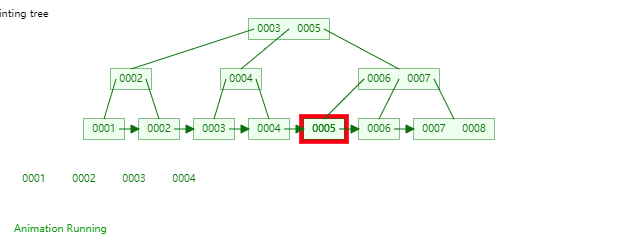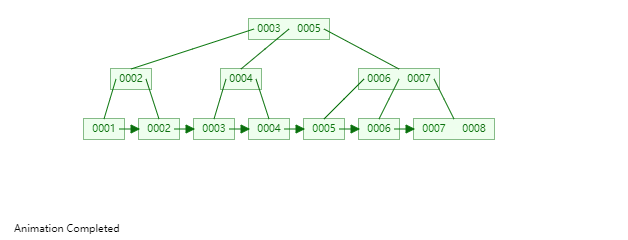
B+Tree是一种神奇的数据结构,如果用语言来讲可能会优点费劲,感兴趣的同学可以点击这里进行数据结构可视化,操作一番后想必会有所收获,下图是笔者演示B+Tree的数据插入方式(自下而上)。
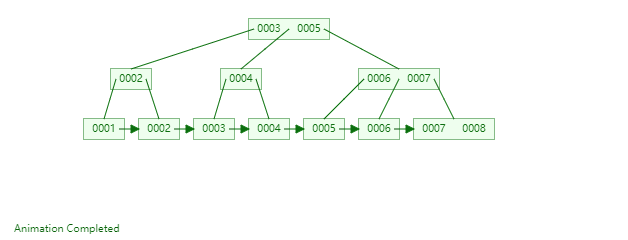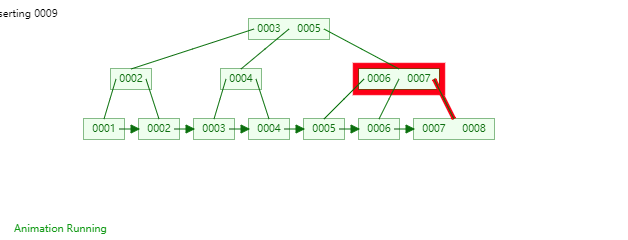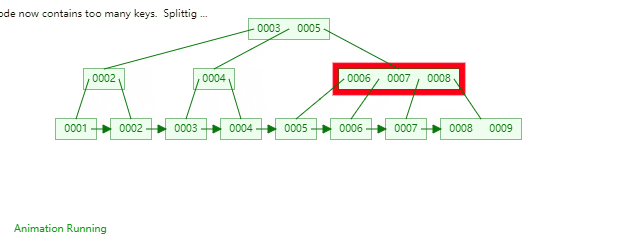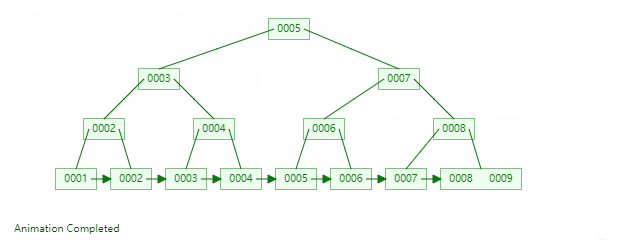
二,数据组织方式
根据数据的组织方式,可以分为聚簇索引和非聚簇索引(也叫聚集索引和非聚集索引)。如果是索引组织数据,就称之为聚簇索引,否则称之为非聚簇索引,简单来说索引和数据是否存储在一起。
需要注意的是,这种索引划分方式通常用来体现不同存储引擎的组织数据方式的差异(通常指的是InnoDB和MyISAM存储引擎)。而InnoDB中的辅助索引并不能称之为非聚簇索引,关于辅助索引的内容,下文会进行详细介绍。InnoDB中是通过索引来组织数据,为聚簇索引。
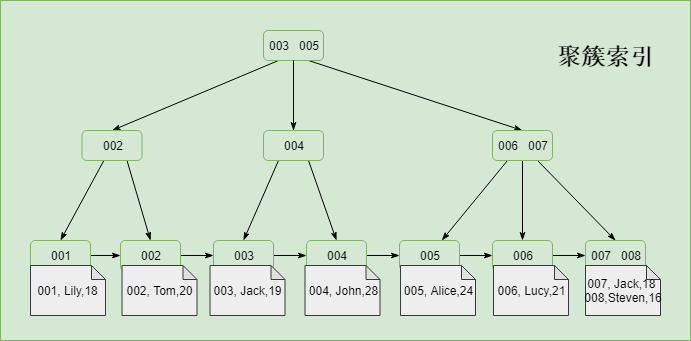
而MyISAM中索引和数据文件分开存储,为非聚簇索引。B+Tree的叶子节点存储的是数据存放的地址,而不是具体的数据 。
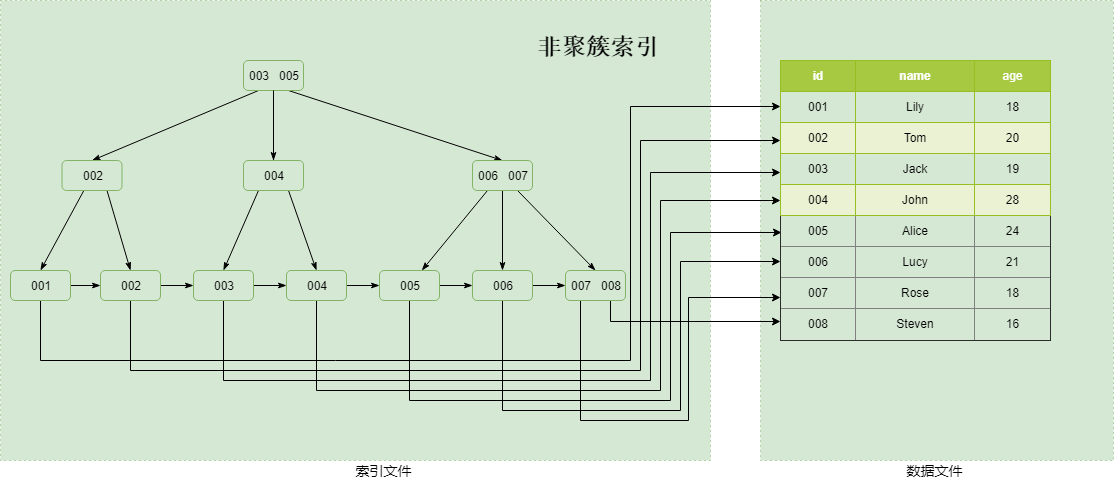
三,索引字段个数
为了能应对不同的数据检索需求,索引即可以仅包含一个字段,也可以同时包含多个字段。单个字段组成的索引可以称为单值索引,否则称之为复合索引(或者称为组合索引或多值索引)。上文中演示的都是单值索引,所以接下来展示一下复合索引作为对比。
复合索引的索引的数据顺序跟字段的顺序相关,包含多个值的索引中,如果当前面字段的值重复时,将会按照其后面的值进行排序。
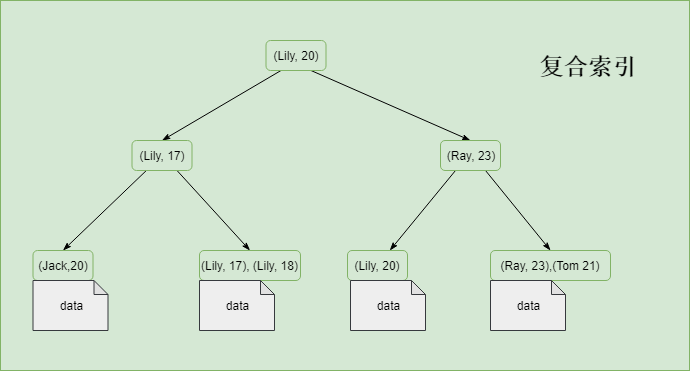
四, 是否存储完整数据行
MySQL中是根据主键来组织数据,所以每张表都必须有主键索引,主键索引只能有一个,不能为null同时必须保证唯一性。建表时如果没有指定主键索引,则会自动生成一个隐藏的字段作为主键索引。
如果不是主键索引,则就可以称之为非主键索引,又可以称之为辅助索引,二级索引。主键索引的叶子节点存储了完整的数据行,而非主键索引的叶子节点存储的则是主键索引值,通过非主键索引查询数据时,会先查找到主键索引,然后再到主键索引上去查找对应的数据,这个过程叫做回表(下文中会再次提到)。
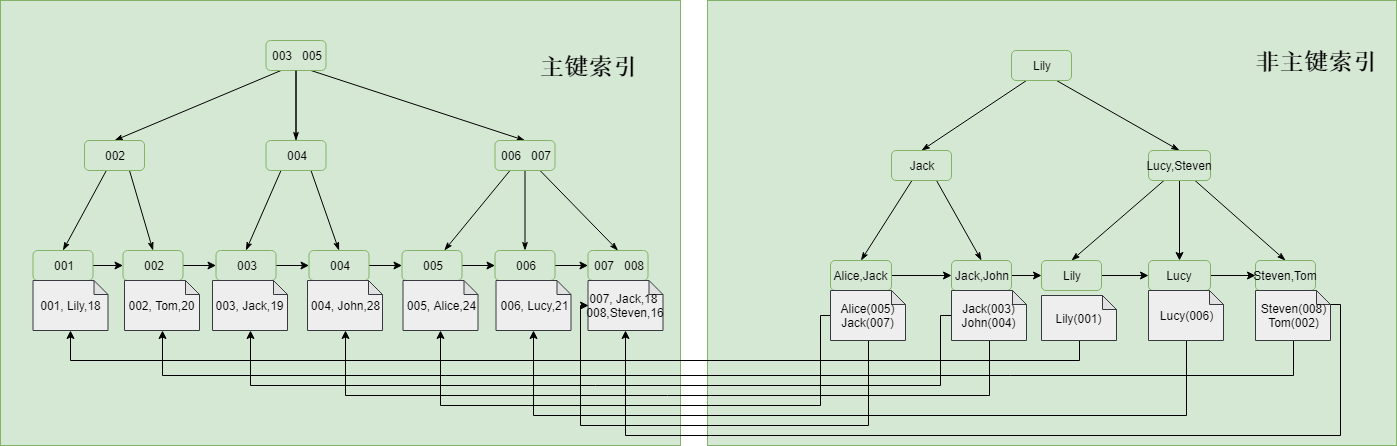
五,其他分类
唯一索引
唯一索引,不允许具有索引值相同的行,从而禁止重复的索引或键值。系统在创建该索引时检查是否有重复的键值,并在每次使用 INSERT 或 UPDATE 语句添加数据时进行检查, 如果有重复的值,则会操作失败,抛出异常。
需要注意的时,主键索引一定时唯一索引,而唯一索引不一定时主键索引。唯一索引可以理解为仅仅是将索引设置一个唯一性的属性。
覆盖索引
上文提到了一个回表的概念,既如果通过非主键索引查询数据时,会先查询到主键索引的值,然后再去主键索引中查询具体的数据,整个查询流程需要扫描两次索引,显然回表是一个耗时的操作。
为了减少回表次数,再设计索引时我们可以让索引中包含要查询的结果,在辅助索引中检索到数据后直接返回,而不需要进行回表操作。
但是需要注意的是,使用覆盖索引的前提是字段长度比较短,对于值长度较长的字段则不适合使用覆盖索引,原因有很多,比如索引一般存储在内存中,如果占用空间较大,则可能会从磁盘中加载,影响性能。当然还有其他原因,具体情况将会在下一篇文章中介绍。
六,总结
本文从不同维度介绍了MySQL中的索引,索引从不同维度划分可以有很多种名称,但是需要明确一个问题就是,索引的本质是一种数据结构,其他索引的划分则是针对实际应用而言。具体分类如下图所示:
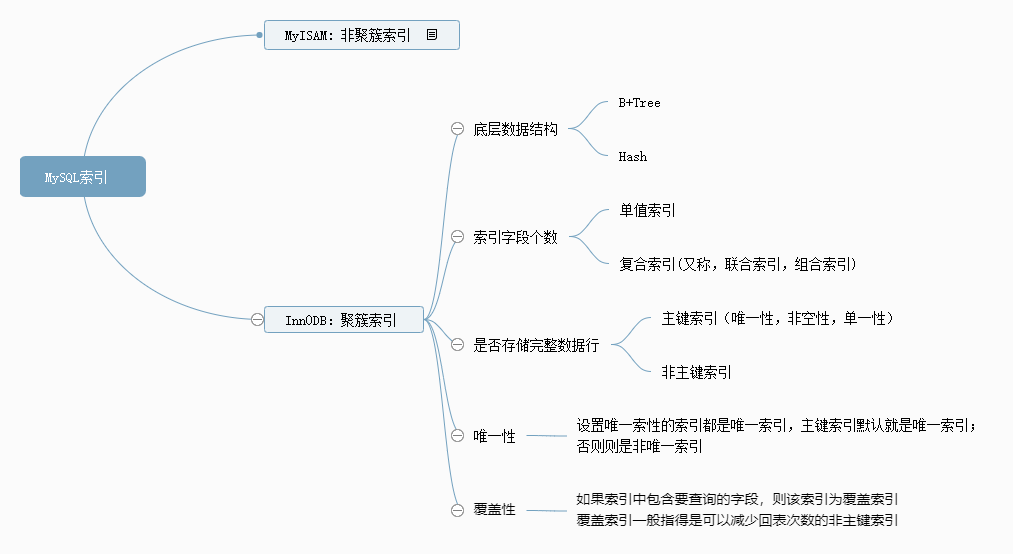
目的是让大家对于索引有个初步且清晰的认识,解决What的问题。后续将会针对Why以及How,进行深入探讨,当然,首先应当能区分本章文章中讲述的概念性问题。
七、Q&A
1. 为什么MySQL索引使用B+Tree实现,而不是搜索二叉树,红黑树或者跳表?
这是一个综合性问题,远不止看起来那么简单,小伙伴们可以把答案写在留言区我们一起探讨,同样笔者将会在下一篇文章中重点介绍为什么,以及如何正确使用索引。

加载全部内容