AI:拿来主义——预训练网络(二)
renyuzhuo 人气:1上一篇文章我们聊的是使用预训练网络中的一种方法,特征提取,今天我们讨论另外一种方法,微调模型,这也是迁移学习的一种方法。
微调模型
为什么需要微调模型?我们猜测和之前的实验,我们有这样的共识,数据量越少,网络的特征节点越多,会越容易导致过拟合,这当然不是我们所希望的,但对于那些预先训练好的模型,还有可能最终无法很好的完成所要做的工作,因此我们还需要对其更改,基于此原因,我们需要做的就是拿来一个训练好的模型,更改其中更加抽象的层,即网络后面的层,然后再采用新的分类器,这样可以比较好的解决上面所提出的过拟合问题了。
进行微调网络的步骤是:
在已经训练好的网络(基网络)基础上,添加自定义的层;
冻结基网络并训练新添加的层;
冻结基网络的一部分层,另一部分可训练;
联合训练解冻的这些层和添加的部分。
我们上一篇提到的方法就可以完成前两个步骤,接下来我们看如何解决后两个步骤。这里我们还要更明确一下调整的层数如果过多会带来什么问题:随着可变层数的增多,过拟合的风险会随之加大。还要明确调整网络中识别像素和线条的层不如调整识别耳朵的层更有效,因为不论是识别猫还是桌子识别线条的方法层更通用。
完成这项任务所需要写的代码也是很简单的,就是设置模型是可训练的,然后遍历网络的每一层,针对每一层分别设置是否是可训练的,直到 layer_name 层,前面的层都是不可训练的:
conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'layer_name':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False这里是关键部分代码,老规矩,最后将给出全部代码,我们先来看看结果:
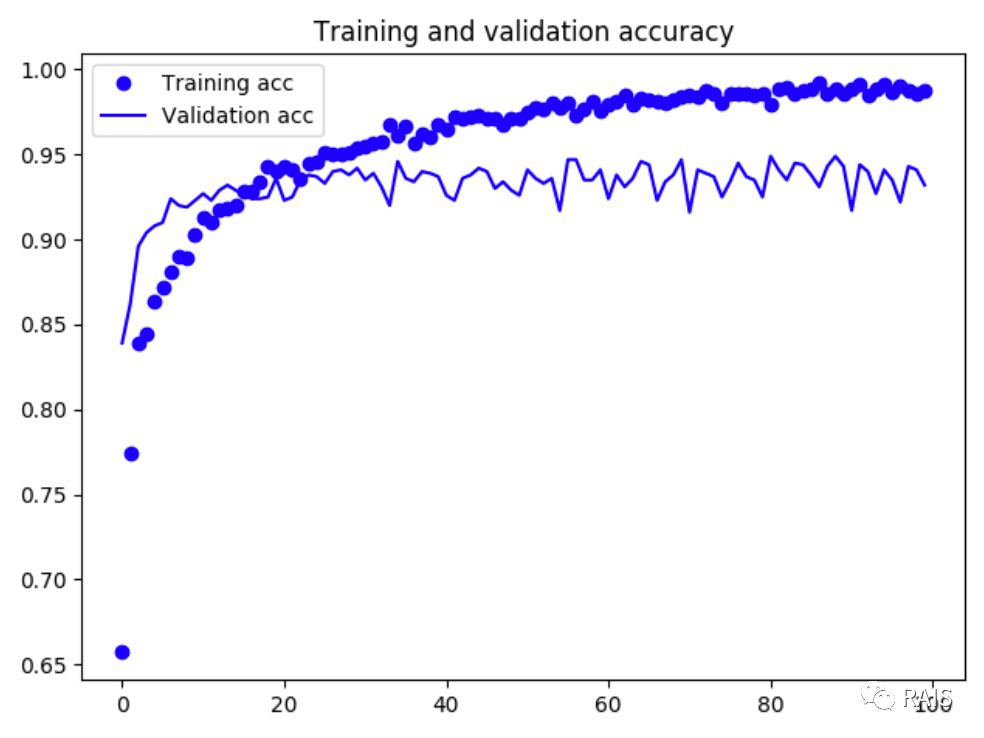
需要注意一下这里的数据,在开始的时候不稳定,迅速爬升,因此纵坐标的数据没有那么好,但我们仔细看一下后期的数据,训练精度和验证精度都在百分之九十到百分之百,验证精度一直有一些波动,是网络的一些噪声引起的,我不想去强制让它们那么漂亮了,一是因为训练时间会比较长,而是因为我觉得没有特别大的必要,波动的最高点和最低点都在可接受的范围内,应该把关注点放在更重要的问题上去。
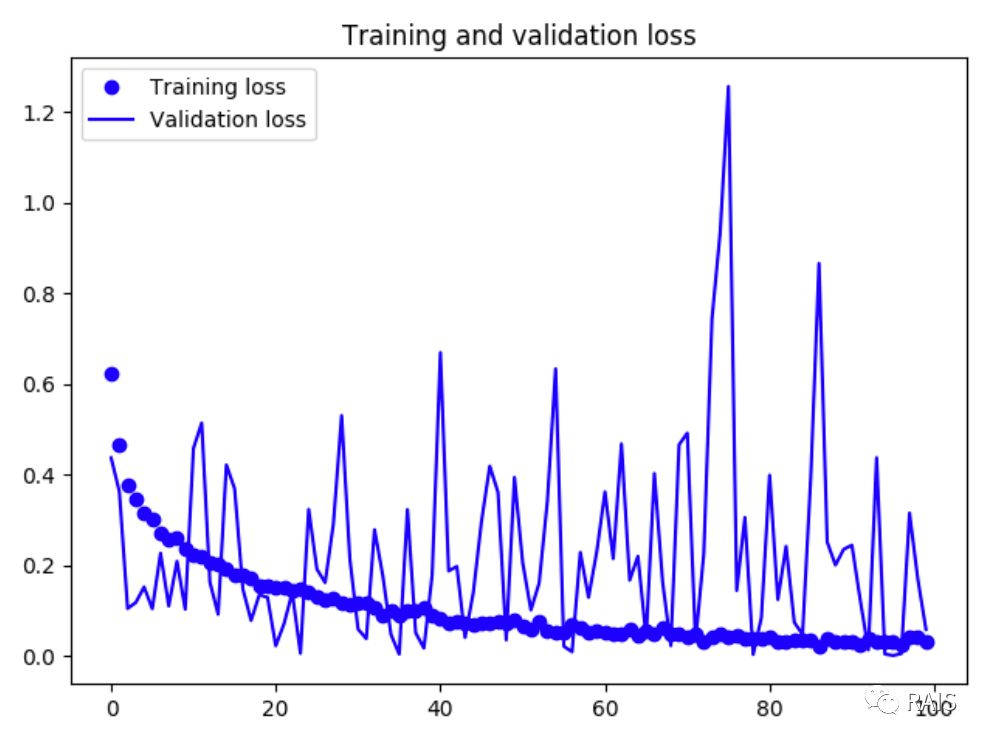
基于本篇文章和上一篇文章,我们做个小结:
计算机视觉领域中,卷积神经网络的表现非常不错,并且在数据集较小的情况下,表现让人是非常优秀的。
数据增强是很好的避免过拟合的方法,过拟合产生的主要原因可能是数据量太少或者是参数过多。
特征提取可以比较好的将现有的神经网络应用于小型数据集,还可以使用微调的方式进行优化。
我们看看代码吧,这里还有一个建议,如果可能尽量使用 GPU 去做网络模型的训练,CPU 在现阶段处理这些问题会有点力不从心,耗时较长,读者也可以考虑减少一些数据量加快速度,但要避免过拟合,请读者心中记住此类问题,在遇到问题的时候是一个方向(当然,笔者是非常惨的,没有好用的 GPU,因此等待数据画图截图是非常痛苦的一件事):
#!/usr/bin/env python3
import os
import time
import matplotlib.pyplot as plt
from keras import layers
from keras import models
from keras import optimizers
from keras.applications import VGG16
from keras.preprocessing.image import ImageDataGenerator
def cat():
base_dir = '/Users/renyuzhuo/Desktop/cathttps://img.qb5200.com/download-x/dogs-vs-cats-small'
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'validation')
train_datagen = ImageDataGenerator(
rescale=1. / 255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
test_datagen = ImageDataGenerator(rescale=1. / 255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
# 定义密集连接分类器
conv_base = VGG16(weights='imagenet',
include_top=False,
input_shape=(150, 150, 3))
conv_base.trainable = True
set_trainable = False
for layer in conv_base.layers:
if layer.name == 'block5_conv1':
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
model = models.Sequential()
model.add(conv_base)
model.add(layers.Flatten())
model.add(layers.Dense(256, activation='relu', input_dim=4 * 4 * 512))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))
conv_base.summary()
# 对模型进行配置
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-5),
metrics=['acc'])
# 对模型进行训练
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
# 画图
acc = history.history['acc']
val_acc = history.history['val_acc']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.show()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
if __name__ == "__main__":
time_start = time.time()
cat()
time_end = time.time()
print('Time Used: ', time_end - time_start)本文首发自公众号:RAIS
加载全部内容