启发式算法之遗传算法
harrylyx 人气:1刚开学便被拉去参加了研究生数模比赛,赛题是一个航班排班的优化问题,所以第一反映便是遗传算法,比赛期间三个问题都使用单目标遗传算法,趁着还比较熟悉,特此记录,以便后续复习。本篇文章使用Python进行实现。
启发式算法
启发式算法是一种技术,这种技术使得在可接受的计算成本内去搜寻最好的解,但不一定能保证所得的可行解和最优解,甚至在多数情况下,无法阐述所得解同最优解的近似程度。
就是说这种算法的全局最优解只是理论上可行,大多数情况下都是一个局部最优解。启发式算法用的比较多的有模拟退火算法(SA)、遗传算法(GA)、列表搜索算法(ST)、进化规划(EP)、进化策略(ES)、蚁群算法(ACA)、人工神经网络(ANN)。这里重点介绍一下遗传算法(GA)。
遗传算法准备
遗传算法(Genetic Algorithm, GA)起源于对生物系统所进行的计算机模拟研究。它是模仿自然界生物进化机制发展起来的随机全局搜索和优化方法,借鉴了达尔文的进化论和孟德尔的遗传学说。其本质是一种高效、并行、全局搜索的方法,能在搜索过程中自动获取和积累有关搜索空间的知识,并自适应地控制搜索过程以求得最佳解。
具体来说,在写算法之前,有四个很重要的步骤:
- 确定编码方式
- 如何设计编码
- 确定约束条件
- 如何实现约束
确定编码方式
对于编码方式来说,影响到交叉算子、变异算子等遗传算子的运算方法,大很大程度上决定了遗传进化的效率。 总的来说,编码方式可以分为三大类:二进制编码法、浮点编码法、符号编码法。
二进制编码法:将求解的数从十进制转换成二进制表示,这样便于编码与解码,方便交叉和变异算子的实现,但对于一些连续函数的优化问题,由于其随机性使得其局部搜索能力较差,如对于一些高精度的问题,当迭代接近最优解后,由于其变异后表现型变化很大,不连续,所以会远离最优解,达不到稳定。而格雷码能有效地防止这类现象。
格雷码编码法:我们先来复习一下格雷码:
十进制 格雷码 二进制 0 0000 0000 1 0001 0001 2 0011 0010 3 0010 0011 4 0110 0100 5 0111 0101 6 0101 0110 7 0100 0111 8 1100 1000 9 1101 1001 10 1111 1010维基百科对格雷码解决误码的说明:
傳統的二進位系統例如數字3的表示法為011,要切換為鄰近的數字4,也就是100時,裝置中的三個位元都得要轉換,因此於未完全轉換的過程時裝置會經歷短暫的,010,001,101,110,111等其中數種狀態,也就是代表著2、1、5、6、7,因此此種數字編碼方法於鄰近數字轉換時有比較大的誤差可能範圍。葛雷碼的發明即是用來將誤差之可能性縮減至最小,編碼的方式定義為每個鄰近數字都只相差一個位元,因此也稱為最小差異碼,可以使裝置做數字步進時只更動最少的位元數以提高穩定性。
连续两个整数所对应的编码值之间仅仅只有一个码位是不同的,当迭代次数很多接近最优值时,相邻两个值之间变化是最大的,当一个染色体变异后,它原来的表现现和现在的表现型是连续的,这样可以将误差的可能性缩减至最小。
格雷码的转换为:
G为格雷码,B为二进制码,n为当前计算位,\(\oplus\)为异或
就有\(G(n) = B(n+1) \oplus B(n)\)
即\(G(n) = B(n+1) + B(n)\)
浮点编码法
对于一些多维、高精度要求的连续函数优化问题,使用二进制编码来表示个体时将会有一些不利之处。
二进制编码存在着连续函数离散化时的映射误差。个体长度较知时,可能达不到精度要求,而个体编码长度较长时,虽然能提高精度,但却使遗传算法的搜索空间急剧扩大。
所谓浮点法,是指个体的每个基因值用某一范围内的一个浮点数来表示。在浮点数编码方法中,必须保证基因值在给定的区间限制范围内,遗传算法中所使用的交叉、变异等遗传算子也必须保证其运算结果所产生的新个体的基因值也在这个区间限制范围内。
符号编码法
这种编码法其实在解决实际问题时问题时是用的最多的,例如这次的航班优化问题我就使用的这种方法,这种方法要结合实际问题来进行编码,然后交叉和变异也要结合实际进行编写,这里我就举个具体例子来讲解一下符号编码法。
如何设计编码
对于一般的数学函数优化问题都是将求解的值转换成二进制或者格雷码进行迭代然后计算适应度(fitness)即可,这里我主要讲解一下如果不是一个传入值直接求解方程的问题解决。
举个栗子
假如我有10架航班(a,b,c,...),和5个登机口(1,2,3,4,5),我现在要让排班更加紧凑,使得使用的登机口数尽量少。每架飞机有个一个出发时间(departure_time),在出发时间之前45分钟飞机必须到达登机口,于是我们设计的一个最小化函数即为
\[ F = \sum_{i=0}^5\sum_{j=0}^{10}S_{ij}\]
这里i即为登机口数,j为航班数,这样\(S_ij\)就是对应登机口的航班与上一架航班的时间之差,使得时间和最小我们可以使得安排更加紧凑。
那我就可以这样进行编码

10个染色体就是对应的10架航班,里面的内容就是其对应的登机口号,这样我们就可以计算同一登机口的相邻飞机的起飞间隔时间差了。
例如2号登机口对应的就是飞机a,飞机i,那么我们使用$ i_{arrival_time} - a_{arrival_time}$就可以得到对应的时间差了,统计计算1号,3号,4号和5号,加在一起就是我们的目标函数的值了。
确定约束条件
对于不同的问题求解会有不同的约束方式,常见的约束方式有
- 范围限制
- 条件限制
范围限制,例如我们的求值只可在(0,0.3]与[0.5,0.8)之间,那么我们在求解的时候要么加入惩罚项,即计算到非对应范围的时候乘上一个很大的值来限制,要不就在对应交叉和变异的时候先判断在交叉变异进行限制。
条件限制,例如上题,我们假如约束条件,即为飞机有宽与窄之分,我们的登机口也有对应的宽窄之分,对应的飞机只能停到对应的登机口处,所以这里我们编码时也要在满足约束进行编码,编写交叉变异时也针对此进行编写。
如何实现约束
实现约束即在三个地方实现,分别为
- 基因可行解初始化(inital)
- 基因交叉(crossover)
- 基因变异(mutate)
这里简单讲解一下可行解初始化的约束如何实现,我们可以写一个简单的while循环来找到可行解:
POP_SIZE = 100 # 可行解数目
DNA_SIZE = 10 #dna长度,这里为航班数量,即为10
all_airport_id = [1,2,3,4,5] # 登机口id
aircraft_to_airport_dict = {
1:[1,2,3],
2:[2,3,4],
...
}# 这里是每架飞机对应的登机口id,这里我就简写了
def inital(self):
pop = [] # 可行解list
while len(pop) != POP_SIZE:
dna = [0 for i in range(DNA_SIZE)]
all_aircraft_id = list(range(1, 11)) # 所有飞机id
temp_airport_id_set = set() # 遍历过的存储飞机对应的可行的飞机场
for aircraft_id in all_aircraft_id:
workable_airport = aircraft_to_airport_dict[aircraft_id] #可行的登机口id
while 1: #直到要找到合适的机场停机
airport_id = random.choice(list(workable_airport)) # 随机生成一个登机口id
temp_airport_id_set.add(airport_id)
if len(temp_airport_id_set) == len(workable_airport):
dna[aircraft_id-1] = 0 #如果全都不合适,就跳出
break
if constraint(aircraft_id, airport_id): #如果满足约束
dna[aircraft_id-1] = airport_id这里的constraint约束函数可以是很多约束,比如时间约束,区域约束等等。
遗传算法实现
个人认为遗传算法总体分为5个部分:
- 初始化可行解
- 目标函数,即计算适应度(fitness)
- 适者生存
- 交叉进化
- 变异
具体流程为:
生成n组可行解dna
迭代m次:
计算每个dna的fitness
适者生存
循环n个dna:
交叉进化
变异接下来主要讲一下适者生存、交叉进化和变异
适者生存
物竞天择,适者生存
适者生存的意思就是通过计算fitness,然后作为随机选择的概率,这样概率越大的就被选择到概率越大。具体实现如下,我对fitness做了个倒数,这里是因为我计算的是最小化,所以越小对于我来说是最优的,所以取倒数再计算概率才符合逻辑。
def select(self, pop, fitness):
fitness = 1 / fitness
idx = np.random.choice(np.arange(POP_SIZE), size=POP_SIZE, replace=True,
p=fitness/fitness.sum())
return pop[idx]交叉进化
交叉进化有很多种方式,具体可以看这篇文章遗传算法中几种交叉算子小结,讲的已经很全了。
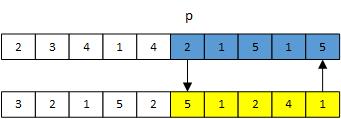
这里我主要讲一下单点交叉,即随机在双亲(parent)dna上选择一个点p,然后与孩子(child)dna上p点后的基因进行交换,实现起来也十分简单。如下图,o点为2,然后就将将蓝色部分与黄色部分互相交换。
CROSS_RATE = 0.8 #交叉概率
def crossover(self, parent, pop):
if np.random.rand() < CROSS_RATE:
i_ = random.randint(0, POP_SIZE - 1) # 孩子基因,child
p = np.random.randint(0, DNA_SIZE) # 单点交叉
parent[p:DNA_SIZE] = pop[i_][p:DNA_SIZE]
return parent
return parent变异
人间总有那么多出其不意的突变,很难说我们怎样才算是到了穷途末路,人只要一息尚存,对什么都可抱有希望。
——蒙田《蒙田随笔全集》
许多突变都是中性的,但有些可能会对后代造成损伤,而有些则可能是有益的。控制基因的突变可以对生物体造成极大的影响。有益的基因突变可以帮助生物更好地适应环境,并很可能遗传给后代。
变异就是在dna上随机选择一个点进行基因变异,这样做的原因是防止局部最优,因为如果这个世界有人突变,那么就不排除会比我们现在更加适应这个世界的可能。c点就是变异点。

MUTATION_RATE = 0.01 #突变概率
def mutate(self, child):
for c in range(DNA_SIZE):
if np.random.rand() < MUTATION_RATE:
workable_airport = aircraft_to_airport_dict[aircraft_id] #可行的登机口id
random_airport_id = random.choice(workable_airport) #随机一个机场
child[c] = random_airport_id加载全部内容